| 利用excel内的doi和python批量下载外文文献 | 您所在的位置:网站首页 › python自动下载网页中的文件怎么删除 › 利用excel内的doi和python批量下载外文文献 |
利用excel内的doi和python批量下载外文文献
|
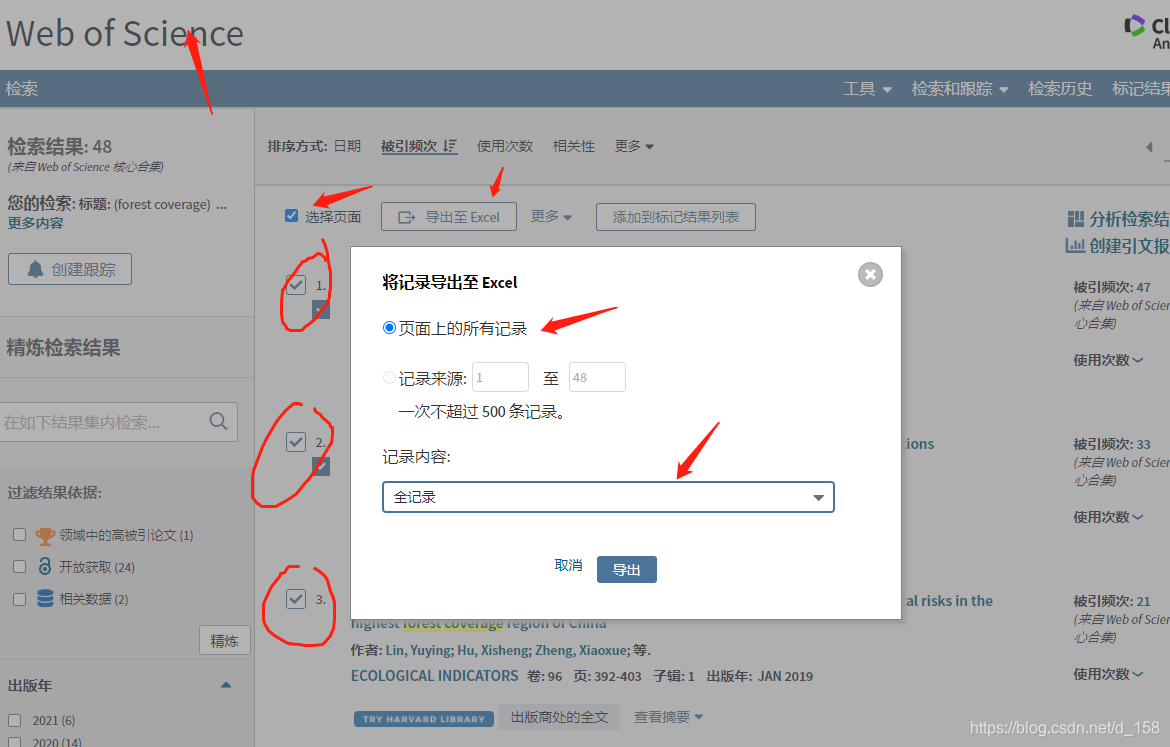
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、将选择的文献用excel导出1.文献按Excel导出2. 将DOI另存在一个excel中,存为xlsx格式 二、利用python批量下载Excel表中文献2.代码 总结 前言利用web of science 批量获取doi至表格,之后通过运行python代码,自动批量下载文献 我用的python3.7,在Anaconda里运行的 提示:其中,python代码是根据WuGenQiang(《通过doi下载单个文献pdf》)的代码修改的(本人python没学多少,所以代码不规范,见谅)。 一、将选择的文献用excel导出 1.文献按Excel导出在web of science内检索完自己想要的文献后,选择自己需要的文献,然后点击,记录内容改为,点导出
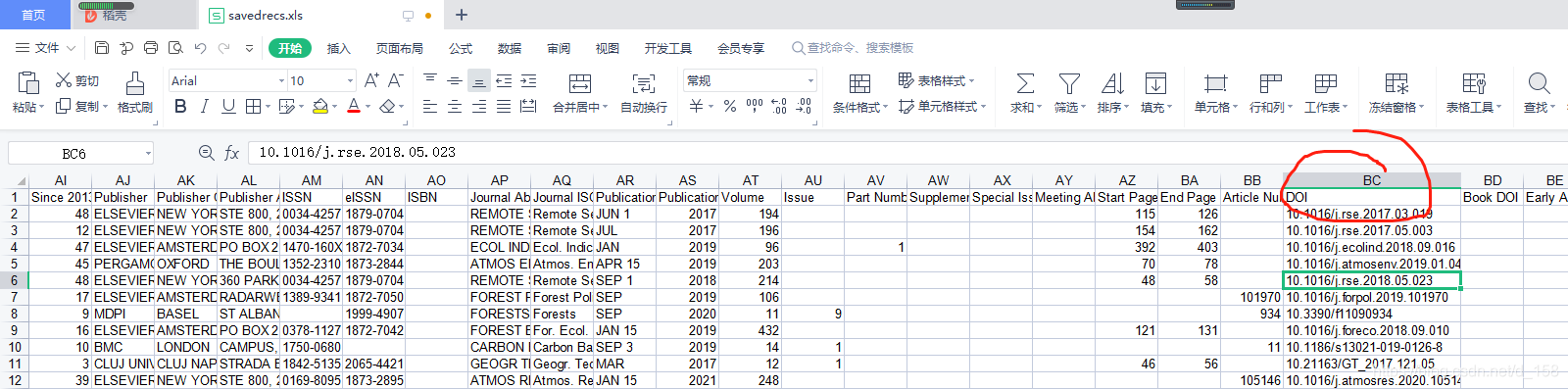
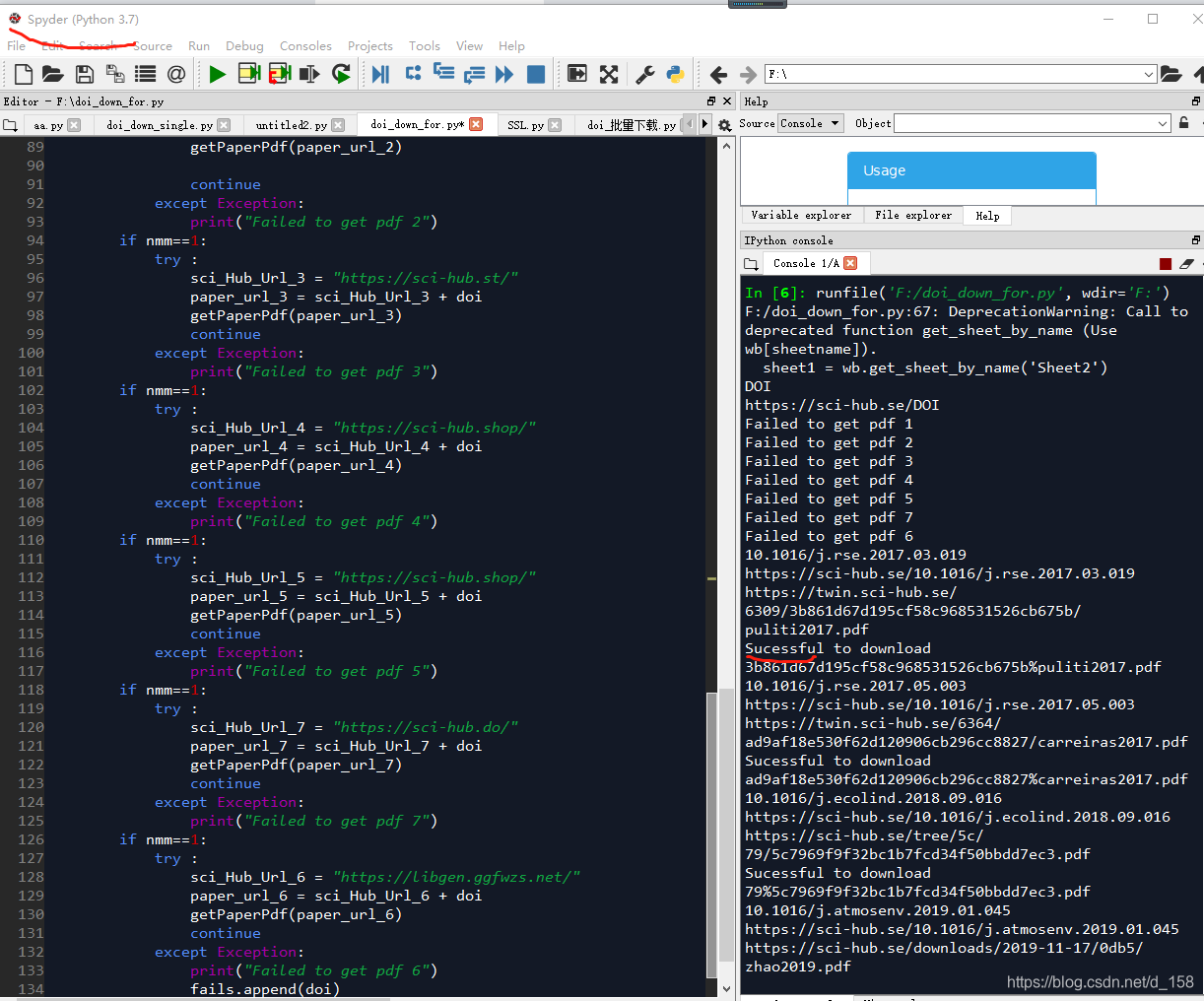
直接用导出的excel,会出错,可能是我调用excel的类型不对?只能读取xlsx?不太清楚,懒得试了,有兴趣的小伙伴可以自己试试 将代码保存至F:\doi_download.py(也可设为其他),将excel挪到F盘,将下面代码的doi所在列改成A列,然后运行就行了。 2.代码 # -*- coding: utf-8 -*- """ Created on Sun Jun 6 21:09:44 2021 @author: dell """ """ 这是原作者的信息 @File: version_1.1_doi_to_get_pdf.py @Time: 2021/4/20 10:10 下午 @Author: [email protected] @desc: 通过doi号下载文献pdf """ import requests import re import os import urllib.request import openpyxl # headers 保持与服务器的会话连接 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36', } ''' 根据doi,找到文献的pdf,然后下载到本地 ''' def getPaperPdf(url): pattern = '/.*?\.pdf' content = requests.get(url, headers=headers) download_url = re.findall(pattern, content.text) # print(download_url) download_url[1] = "https:" + download_url[1] print(download_url[1]) path = r"papers" if os.path.exists(path): pass else: os.makedirs(path) # 使用 urllib.request 来包装请求 req = urllib.request.Request(download_url[1], headers=headers) # 使用 urllib.request 模块中的 urlopen方法获取页面 u = urllib.request.urlopen(req, timeout=5) file_name = download_url[1].split('/')[-2] + '%' + download_url[1].split('/')[-1] f = open(path + '/' + file_name, 'wb') block_sz = 8192 while True: buffer = u.read(block_sz) if not buffer: break f.write(buffer) f.close() print("Sucessful to download" + " " + file_name) ''' 将表格放在代码保存和运行的路径内,将wb变量内的'n0606.xlsx'改为自己的excel文件名, 最后下载的论文在该路径下新建的papers文件夹内 ''' wb = openpyxl.load_workbook('n0606.xlsx') #doi在sheet1中 sheet1 = wb.get_sheet_by_name('Sheet1') #读取第A列 ''' 修改代码内,excel中DOI所在列,我的在BC,所以col_range变量后面的字符改为了‘BC’ ''' col_range = sheet1['A'] # 读取其中的第几行:row_range = sheet1[2:6] fails=[] #以下代码加入了我找的其他SCI-hub网址,不需要可以删除一些 for col in col_range: # 打印BC两列单元格中的值内容 doi=col.value print (doi) if __name__ == '__main__': sci_Hub_Url = "https://sci-hub.ren/" paper_url = sci_Hub_Url + doi print(paper_url) nmm=0 try: getPaperPdf(paper_url) # 通过文献的url下载pdf continue except Exception: nmm=1 print("Failed to get pdf 1" ) if nmm==1: try : sci_Hub_Url_2 = "https://sci-hub.se/" paper_url_2 = sci_Hub_Url_2 + doi getPaperPdf(paper_url_2) continue except Exception: print("Failed to get pdf 2") if nmm==1: try : sci_Hub_Url_3 = "https://sci-hub.st/" paper_url_3 = sci_Hub_Url_3 + doi getPaperPdf(paper_url_3) continue except Exception: print("Failed to get pdf 3") if nmm==1: try : sci_Hub_Url_4 = "https://sci-hub.shop/" paper_url_4 = sci_Hub_Url_4 + doi getPaperPdf(paper_url_4) continue except Exception: print("Failed to get pdf 4") if nmm==1: try : sci_Hub_Url_5 = "https://sci-hub.shop/" paper_url_5 = sci_Hub_Url_5 + doi getPaperPdf(paper_url_5) continue except Exception: print("Failed to get pdf 5") if nmm==1: try : sci_Hub_Url_7 = "https://sci-hub.do/" paper_url_7 = sci_Hub_Url_7 + doi getPaperPdf(paper_url_7) continue except Exception: print("Failed to get pdf 7") if nmm==1: try : sci_Hub_Url_6 = "https://libgen.ggfwzs.net/" paper_url_6 = sci_Hub_Url_6 + doi getPaperPdf(paper_url_6) continue except Exception: print("Failed to get pdf 6") fails.append(doi) #获取下载失败的doi print (fails)结果展示图在这里。 根据上面写的就可以根据excel的DOI批量下载论文了,不过有一些会失败,那种可能就要手动了,我自己感觉还可以,大家可以试试。 另:python实在不行,所以根据别人代码改的(强调!!!),我加的那些让代码看起来很啰嗦,有更好的写法,欢迎大家告诉我,感恩 |
【本文地址】
公司简介
联系我们