| 线性回归的原理及Python实现 | 您所在的位置:网站首页 › python增加千位分隔符 › 线性回归的原理及Python实现 |
线性回归的原理及Python实现
|
完整实现代码请参考本人的p...哦不是...github:regression_base.pylinear_regression.pylinear_regression_example.py 1. 原理篇我们用人话而不是大段的数学公式来讲讲线性回归是怎么一回事。 1.1 线性方程组上小学或者中学的时候,很多人就接触过线性方程组了。举个栗子,如果x + y = 2且2x + y = 3,那么3x + 4y = ?。我们可以轻松地得出结论,解线性方程组得到x = 1且y = 1,所以3x + 4y = 3 + 4 = 7。 1.2 超定方程组对于方程组Ra=y,R为n×m矩阵,如果R列满秩,且n>m。则方程组没有精确解,此时称方程组为超定方程组。翻译成人话就是方程组里方程的个数n太多了,比要求解的变量数m还多,这个方程是没办法求出精确解的。比如x + y = 2, 2x + y = 3且x + 2y = 4,那么我们是无法求出x和y能够同时满足这三个等式的。 1.3 线性回归问题我们假设公司有n个同事(n = 10000),他们的年龄为A = [a1, a2...an],职级为B = [b1, b2...bn],工资为C = [c1, c2...cn],满足方程组Ax + By + z = C,我们想求出x, y 和z的值从而预测同事的工资,这样的问题就是典型的线性回归问题。我们有3个未知数x, y, z要求解,却有10000个方程,这显然是一个超定方程组。 1.4 最小二乘法如何求解这个超定方程组呢?当当当当,最小二乘法闪亮登场了。假设n个同事有m个特征(年龄、职级等),收集这些特征组成m行n列的矩阵X,同事的工资为m行1列的矩阵Y,且满足m > n。我们要求解n个未知数W = [w1, w2...wn]和1个未知数b,满足方程组W * X + b = Y。令预测值为 当我们的预测值完全等于真实值的时候,MSE等于0。根据上面的讲解,显然我们不太可能找到满足方程的精确解W,也就不可能准确地预测出Y,所以MSE不可能为0。但是我们想办法找出方程的近似解让MSE最小,这就是最小二乘法。 1.5 求近似解如何求让MSE为零的近似解W呢?前方小段数学公式低能预警。 1. 使用MSE作为损失函数L 3. 对w求偏导,得 4. 对b求偏导,得 所以,参数W的梯度就是式3,参数b的梯度就是式4。 1.6 梯度下降法请参考我的另一篇文章,在这里就不赘述。链接如下: 李小文:梯度下降的原理及Python实现zhuanlan.zhihu.com 1.7 批量梯度下降
1.7 批量梯度下降
遍历数据集中所有的样本,计算梯度并更新参数,记做1个epoch。经过若干个epochs之后,算法收敛或终止,计算量较大。 1.8 随机梯度下降使用数据集中随机的一个样本,计算梯度并更新参数,直至算法收敛或终止,计算量较小。 2. 实现篇本人用全宇宙最简单的编程语言——Python实现了线性回归算法,没有依赖任何第三方库,便于学习和使用。简单说明一下实现过程,更详细的注释请参考本人github上的代码。 2.1 创建RegressionBase类初始化,存储权重weights和偏置项bias。 class RegressionBase(object): def __init__(self): self.bias = None self.weights = None 2.2 创建LinearRegression类初始化,继承RegressionBase类。 class LinearRegression(RegressionBase): def __init__(self): RegressionBase.__init__(self) 2.3 预测一个样本 def _predict(self, Xi): return sum(wi * xij for wi, xij in zip(self.weights, Xi)) + self.bias 2.4 计算梯度根据损失函数的一阶导数计算梯度。 def _get_gradient_delta(self, Xi, yi): y_hat = self._predict(Xi) bias_grad_delta = yi - y_hat weights_grad_delta = [bias_grad_delta * Xij for Xij in Xi] return bias_grad_delta, weights_grad_delta 2.5 批量梯度下降正态分布初始化weights,外层循环更新参数,内层循环计算梯度。 def _batch_gradient_descent(self, X, y, lr, epochs): m, n = len(X), len(X[0]) self.bias = 0 self.weights = [normalvariate(0, 0.01) for _ in range(n)] for _ in range(epochs): bias_grad = 0 weights_grad = [0 for _ in range(n)] for i in range(m): bias_grad_delta, weights_grad_delta = self._get_gradient_delta( X[i], y[i]) bias_grad += bias_grad_delta weights_grad = [w_grad + w_grad_d for w_grad, w_grad_d in zip(weights_grad, weights_grad_delta)] self.bias += lr * bias_grad * 2 / m self.weights = [w + lr * w_grad * 2 / m for w, w_grad in zip(self.weights, weights_grad)] 2.6 随机梯度下降正态分布初始化weights,外层循环迭代epochs,内层循环随机抽样计算梯度。 def _stochastic_gradient_descent(self, X, y, lr, epochs, sample_rate): m, n = len(X), len(X[0]) k = int(m * sample_rate) self.bias = 0 self.weights = [normalvariate(0, 0.01) for _ in range(n)] for _ in range(epochs): for i in sample(range(m), k): bias_grad, weights_grad = self._get_gradient_delta(X[i], y[i]) self.bias += lr * bias_grad self.weights = [w + lr * w_grad for w, w_grad in zip(self.weights, weights_grad)] 2.7 训练模型使用批量梯度下降或随机梯度下降训练模型。 def fit(self, X, y, lr, epochs, method="batch", sample_rate=1.0): assert method in ("batch", "stochastic") if method == "batch": self._batch_gradient_descent(X, y, lr, epochs) if method == "stochastic": self._stochastic_gradient_descent(X, y, lr, epochs, sample_rate) 2.8 预测多个样本 def predict(self, X): return [self._predict(xi) for xi in X] 3 效果评估 3.1 main函数使用著名的波士顿房价数据集,按照7:3的比例拆分为训练集和测试集,训练模型,并统计准确度。 def main(): @run_time def batch(): print("Tesing the performance of LinearRegression(batch)...") reg = LinearRegression() reg.fit(X=X_train, y=y_train, lr=0.02, epochs=5000) get_r2(reg, X_test, y_test) @run_time def stochastic(): print("Tesing the performance of LinearRegression(stochastic)...") reg = LinearRegression() reg.fit(X=X_train, y=y_train, lr=0.001, epochs=1000, method="stochastic", sample_rate=0.5) get_r2(reg, X_test, y_test) X, y = load_boston_house_prices() X = min_max_scale(X) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=10) batch() stochastic() 3.2 效果展示批量梯度下降拟合优度0.784,运行时间12.6秒; 随机梯度下降拟合优度0.784,运行时间1.6秒。效果还算不错~ 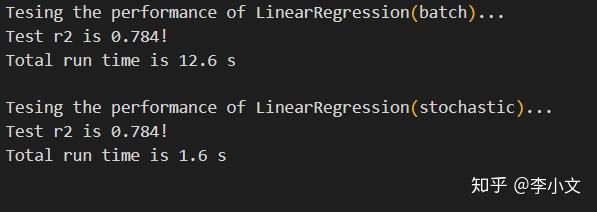 3.3 工具函数
3.3 工具函数
本人自定义了一些工具函数,可以在github上查看utils run_time - 测试函数运行时间 load_boston_house_prices - 加载波士顿房价数据 train_test_split - 拆分训练集、测试集 get_r2 - 计算拟合优度 总结线性回归的原理:求解超定方程组。 线性回归的实现:加减法,for循环。 梯度下降的原理及Python实现逻辑回归的原理及Python实现 |
【本文地址】