| python爬虫:使用requests | 您所在的位置:网站首页 › python中的标签 › python爬虫:使用requests |
python爬虫:使用requests
|
在python 3.6版本及以上,引入了一个新的库:requests_html 。说实话,这个库是真的方便使用,它可以将爬虫变得很简单,话不多说,直接上手。我们想要爬取下面这个网站的代码部分: https://cpppatterns.com/patterns/copy-range-of-elements.html (代码部分指的是如下图黑框中的C++代码) 2.然后输入我们的网址,获取页面信息 session = HTMLSession() url = ' https://cpppatterns.com/patterns/copy-range-of-elements.html ' r = session.get(url)3.开始网页抓包,我们来到上面所说的网站后,按F12,会弹出如下图: 这是不是很很像是html中的标签呢,对,Copy selector就是把#include所在的标签路径复制了下来,上面的#line1是第一个span的id属性值。我们也可以不用去Copy selector,而直接去看它的标签路径,自己写出来,还是以#include所在标签为例,如图: 是不是发现和Copy selector的不太一样,没关系,这两种都是可以的,对于nth-child(2),它的意思是: 下面我们用一个函数获取网页中的元素: r_code = r.html.find(' tr > td:nth-child(2) > code > span:nth-child(1) > span:nth-child(2)')对,就是r.html.find()函数,可以找到我们提供的路径下的元素。这里得到的是一个list,如果我们想得到#include,可以使用.text print(r_code[0].text)可以看到输出为#include。 到这里,我们已经能爬出一个元素了,那一整个黑框中的C++代码也是这样操作,我们这里也进行讲解。 4.这部分我们就讲解如何爬取黑框中的全部代码,其实很简单,只需改一下标签路径,我们再次来到网页中。 这里的td有个后面部分:nth-child(2),这是因为tr中还有一个td,但是那个td中的内容我们并不需要,这里的span没有加:nth-child(2),意思是我们要取code下的所有span,因为得到的是一个list,所以我们需要一个for循环进行输出: mylist = [] for result in r_code: mylist.append(result.text) mylist = " ".join(mylist) #这个函数可以去掉list中的引号和中括号 print(mylist) mylist=[]我们可以在控制台看到输出整个黑框中的代码了 5.完整代码 from requests_html import HTMLSession session = HTMLSession() url = 'https://cpppatterns.com/patterns/copy-range-of-elements.html' r = session.get(url) def get(sel_title): #sel_title是代码名字的标签路径 r_title = r.html.find(sel_title) r_code = r.html.find('tr > td:nth-child(2) > code > span') # mylist = [] print(r_title[0].text) # 输出代码的名字 for result in r_code: mylist.append(result.text) mylist = " ".join(mylist) #这个函数可以去掉list中的引号和中括号 print(mylist) mylist=[] #清空mylist,便于接收下一个result if __name__ == "__main__": sel_title = 'head > title' #代码名字的路径 get(sel_title) #调用上面那个函数 |
 我们使用的变成工具是pycharm,接下来进行操作讲解: 1.首先要导入requests_html库
我们使用的变成工具是pycharm,接下来进行操作讲解: 1.首先要导入requests_html库 点击Elements,这是这个网页的前端代码,我们再点击下图红框的地方(左上角):
点击Elements,这是这个网页的前端代码,我们再点击下图红框的地方(左上角):  然后把鼠标放在黑框中的代码处,会出现如下情况:
然后把鼠标放在黑框中的代码处,会出现如下情况: 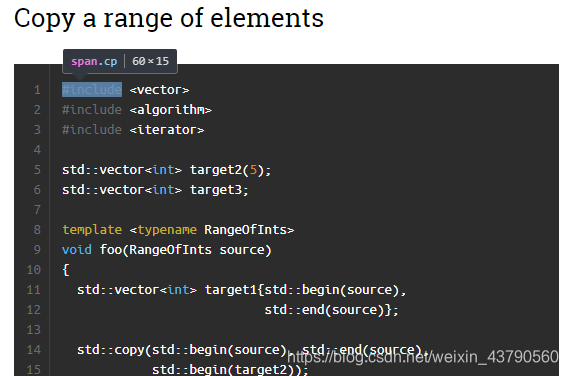 点击一下,在看看下方的前端代码部分,这时候就会定位到你所点击的那个#include的前端代码,如下蓝色部分:
点击一下,在看看下方的前端代码部分,这时候就会定位到你所点击的那个#include的前端代码,如下蓝色部分:  对着蓝色部分右键,选择copy—>Copy selector。 继续看代码,因为上面已经Copy selector了,我们来到pycharm中粘贴一下,会得到下面的内容:
对着蓝色部分右键,选择copy—>Copy selector。 继续看代码,因为上面已经Copy selector了,我们来到pycharm中粘贴一下,会得到下面的内容: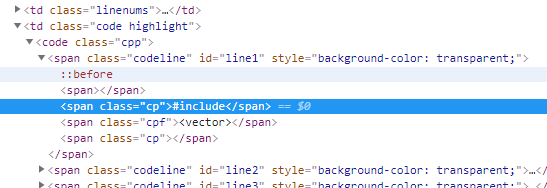 可以看到,蓝色部分的上一层标签还是span,再上一层是code,我们就取这两层就足够定位#include了,因此无需再往上找(当然,如果继续往上也没问题),我们就可以写出路径:
可以看到,蓝色部分的上一层标签还是span,再上一层是code,我们就取这两层就足够定位#include了,因此无需再往上找(当然,如果继续往上也没问题),我们就可以写出路径: 如果把nth-child(2)删掉,那就是选取所有的子元素 我们上面已经获取网页内容:
如果把nth-child(2)删掉,那就是选取所有的子元素 我们上面已经获取网页内容: 我们这次选择的是一整行,如上图蓝色部分(说明一下,并不是每个网站的代码都会有这种一整行让你来爬取)。
我们这次选择的是一整行,如上图蓝色部分(说明一下,并不是每个网站的代码都会有这种一整行让你来爬取)。  根据上图,我们可以写出标签路径:
根据上图,我们可以写出标签路径: 如果要爬取其他东西的话大致流程都是这样。
如果要爬取其他东西的话大致流程都是这样。【本文地址】