| Python 3.X 乱码解决(一文搞定Python3.x 乱码问题) | 您所在的位置:网站首页 › python中文打印乱码 › Python 3.X 乱码解决(一文搞定Python3.x 乱码问题) |
Python 3.X 乱码解决(一文搞定Python3.x 乱码问题)
|
Python 升级到3.0之后,已经很少会有乱码的情形,尤其在源码中注解: # -*- coding: utf-8 -*- 但是如果我们读入的内容本来就是乱码的该如何是好? 举例: 从操作系统读取文件清单。在文件夹中查看,该文件名本来就是乱码。 (已知这个文件是繁体BIG5编码,所以在简体系统中显示是乱码)
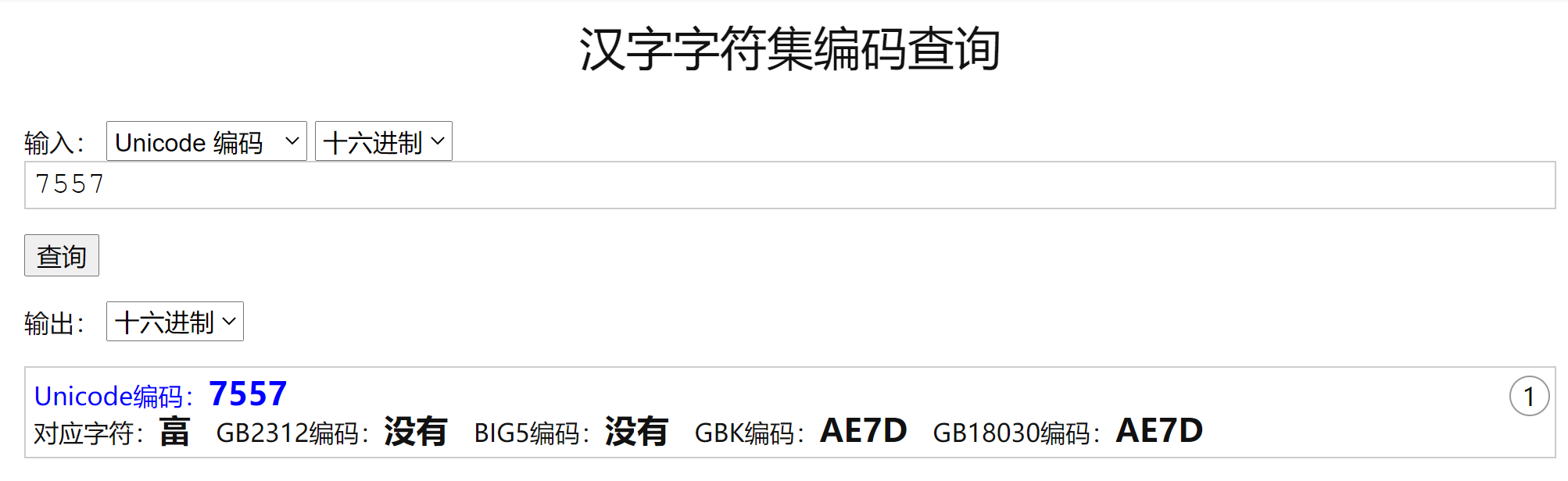
注意“畗”这个,对应的UTF-8的编码是\xe7\x95\x97,转换为unicode之后:\u7557 通过下面网站查看对应的字符编码https://www.qqxiuzi.cn/bianma/zifuji.php
徐 -(Big5 编码)-> AE7D -(GBK 解码)-> 畗 -(UTF-8/Unicode 编码)-> \xe7\x95\x97/\u7557(畗) 所以出现问题的环节还是在红字加粗的部分。 修复乱码 # coding: Utf-8 import os files = os.listdir('c:\\temp') print(files[9:10]) # 仅显示乱码的文件 str1 = files[9] print(str1.encode('utf-8')) print(str1.encode('GBK').decode('Big5'))
徐 -(Big5 编码)-> AE7D -(GBK 解码)-> 畗 -(UTF-8/Unicode 编码)-> \xe7\x95\x97/\u7557 -(UTF-8/Unicode 解码)-> 畗 -(GBK 编码)-> AE7D -(Big5 解码)-> 徐 红色字部分:之前在操作系统层面操作导致出问题 橙色字部分:Python3读取系统文件清单时候的默认操作 绿色字部分:Python3内部默认操作 黑色粗体部分:乱码矫正
附参考文档: https://www.qqxiuzi.cn/bianma/zifuji.php https://tool.oschina.net/hexconvert/ https://zhuanlan.zhihu.com/p/26261762 http://cenalulu.github.io/linux/character-encoding/
|



【本文地址】
公司简介
联系我们