| yolo如何画框、如何变换目标检测框的颜色和粗细、如何运行detect脚本 | 您所在的位置:网站首页 › ps查看颜色代码怎么用不了 › yolo如何画框、如何变换目标检测框的颜色和粗细、如何运行detect脚本 |
yolo如何画框、如何变换目标检测框的颜色和粗细、如何运行detect脚本
|
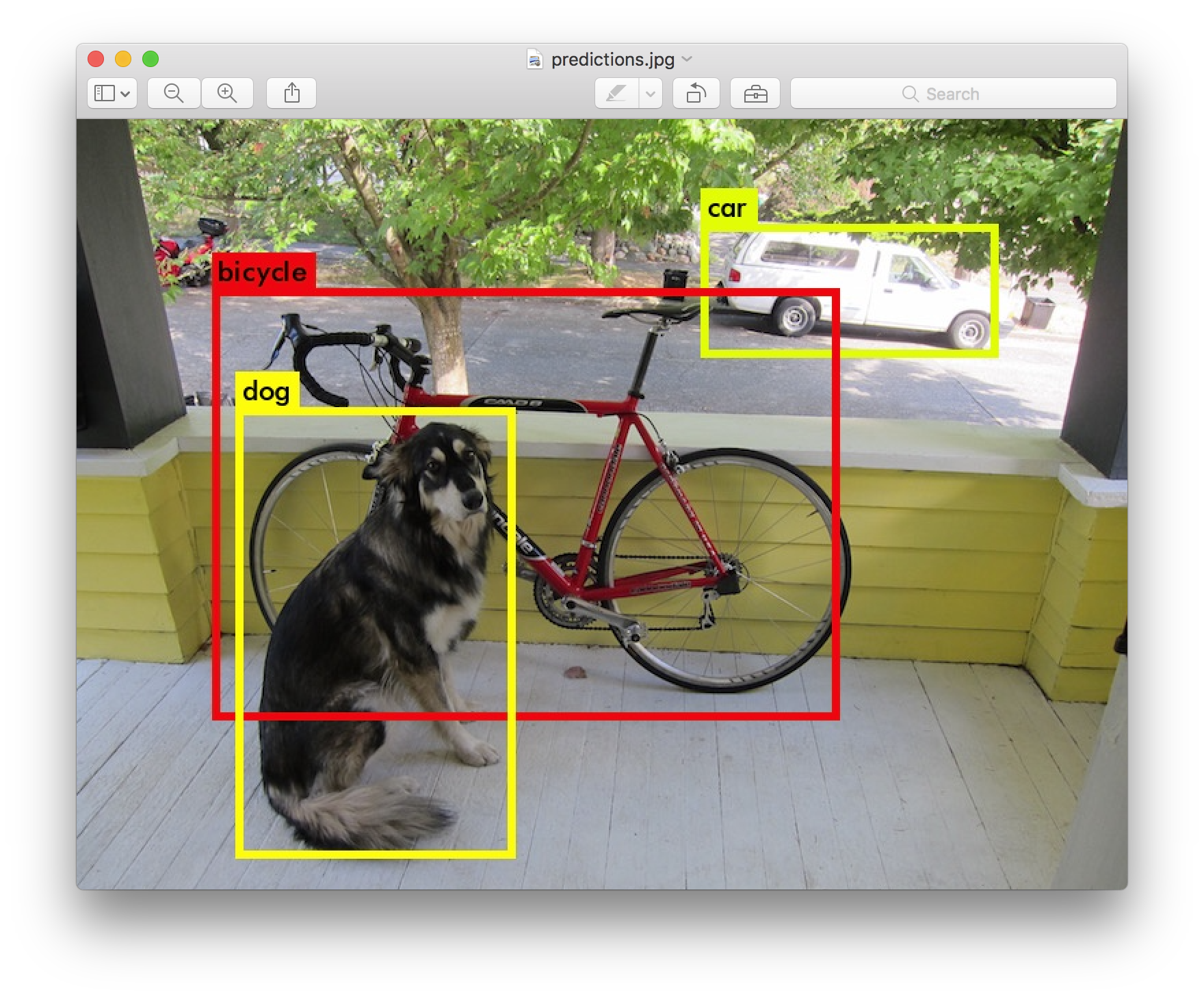
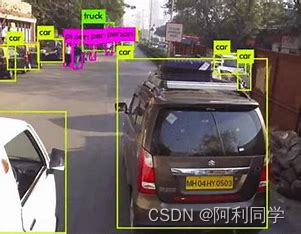
这段代码是一个使用YOLO模型进行目标检测的Python脚本。下面我将逐步解释脚本的主要部分,并提供一些关于超参数的使用方法。 这是一个使用示例,其中--weights指定了模型权重文件的路径,--source指定了输入图像的路径,--img-size设置了输入图像的尺寸,--conf-thres和--iou-thres分别设置了目标置信度和NMS的IOU阈值。--view-img用于显示检测结果图像。 在这段代码中,目标框的颜色和单目测距取点的逻辑主要集中在draw_boxes()函数和plot_one_box()函数中。这两个函数用于在图像上绘制检测到的目标框,并根据条件确定框的颜色以及添加单目测距的信息。 draw_boxes()函数: def draw_boxes(detections, image, colors): for detection in detections: x, y, w, h = detection[2][0], detection[2][1], detection[2][2], detection[2][3] label = detection[0] color = colors[label] cv2.rectangle(image, (int(x - w/2), int(y - h/2)), (int(x + w/2), int(y + h/2)), color, 2) cv2.putText(image, label, (int(x), int(y)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)在这个函数中,detections是目标检测的结果,其中包含了每个目标的坐标、大小、置信度等信息。colors是一个列表,包含了不同类别的目标框颜色。函数通过遍历detections,为每个目标框绘制矩形和标签,并使用colors中的颜色。 plot_one_box()函数: def plot_one_box(xyxy, im0, label=None, color=None, line_thickness=None): tl = line_thickness or round(0.002 * max(im0.shape[0:2])) + 1 # line/font thickness color = color or [random.randint(0, 255) for _ in range(3)] c1, c2 = (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])) cv2.rectangle(im0, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA) if label: tf = max(tl - 1, 1) # font thickness t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0] c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3 cv2.rectangle(im0, c1, c2, color, -1, cv2.LINE_AA) # filled cv2.putText(im0, label, (c1[0], c1[1] - 2), cv2.FONT_HERSHEY_SIMPLEX, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)这个函数用于在图像上绘制一个目标框,它接受目标框的坐标(xyxy)、原始图像(im0)、标签(label)、颜色(color)和线条厚度(line_thickness)作为输入。它会在图像上绘制一个矩形框,填充矩形内的标签,并根据条件设置矩形的颜色。 在这里,color参数可以手动设置,也可以根据目标的测距结果(distance)来动态设置,以区分不同的距离范围,从而实现目标框颜色的动态变化。 YOLO(You Only Look Once)是一种实时目标检测算法,detect.py文件是YOLO的一个脚本,用于在图像或视频上运行已经训练好的YOLO模型并检测目标。 以下是对detect.py主要部分的简要解释,包括目标框颜色、单目测距取点等方面。 1. 导入必要的库和模块 import cv2 import numpy as np from darknet import Darknet from util import *这部分代码导入了需要的Python库和自定义的模块。darknet模块通常包含YOLO的网络结构,而util模块包含一些工具函数。 2. 加载配置文件和权重文件 def load_network(cfgfile, weightfile): net = Darknet(cfgfile) net.load_weights(weightfile) return net这个函数用于加载YOLO的配置文件(.cfg)和权重文件(.weights)并返回一个YOLO网络。 3. 运行目标检测 def detect(cfgfile, weightfile, imgfile): net = load_network(cfgfile, weightfile) image = cv2.imread(imgfile) sized = cv2.resize(image, (net.width, net.height)) detections = detect_image(net, imgfile) return detections这个函数调用load_network加载YOLO网络,然后调用detect_image进行目标检测。detect_image函数通常包含了YOLO的前向传播过程,根据模型输出的预测框和类别信息,返回检测到的目标。 4. 处理检测结果 detections = detect(cfgfile, weightfile, imgfile) draw_boxes(detections, image, colors) cv2.imshow('predictions', image) cv2.waitKey(0) cv2.destroyAllWindows()这里调用了detect函数获取目标检测结果,然后使用draw_boxes函数将检测结果绘制在原图上,给不同的类别框上不同的颜色。 5. 目标框颜色和单目测距取点具体实现可能会在draw_boxes函数中进行。这个函数通常会遍历检测到的目标框,为每个目标框绘制矩形,并根据目标的类别给框上不同的颜色。单目测距和取点的功能通常不在YOLO的基础代码中,可能需要根据具体需求在其他函数中实现。 以下是一个简化的例子: def draw_boxes(detections, image, colors): for detection in detections: x, y, w, h = detection[2][0], detection[2][1], detection[2][2], detection[2][3] label = detection[0] color = colors[label] cv2.rectangle(image, (int(x - w/2), int(y - h/2)), (int(x + w/2), int(y + h/2)), color, 2) cv2.putText(image, label, (int(x), int(y)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)在这个例子中,假设detections是一个包含目标信息的列表,colors是一个字典,将不同的类别映射到不同的颜色。draw_boxes函数遍历检测到的目标框,绘制矩形和类别标签,并根据类别选择颜色。这里只是一个简化的例子,实际应用中可能需要更复杂的处理逻辑。 需要注意的是,根据测距结果设置颜色的逻辑可能需要根据具体的测距方法和要求进行修改。在这个例子中,通过比较distance和阈值来判断目标的距离,并选择相应的颜色进行标记。在实际应用中,可能需要更复杂的逻辑来处理不同的距离范围。 |

【本文地址】