| Python代码实现Canny算法 | 您所在的位置:网站首页 › ps怎么提取图片外轮廓填充颜色 › Python代码实现Canny算法 |
Python代码实现Canny算法
|
Python代码实现Canny算法——图像边缘轮廓提取
一、Canny算法主要思路:
1.通过高斯核进行滤波,去除噪声点,使图像平滑 2.通过求取偏导,使用梯度强度和方向来提取边缘轮廓 3.采用非极大值抑制的方法,将提取到的粗犷的边缘轮廓细化 4.采用双阈值来进一步过滤噪声即过滤掉不想要的线条,同时保证轮廓的连续性 1.高斯核滤波众所周知,正态分布又叫做高斯分布,高斯核滤波其实就是正态分布的一个应用。 高斯分布:(和标准的二维正态分布有点差别) G σ = 1 / ( 2 π σ 1 σ 2 ) ∗ e − ( x − μ ) 2 / σ 1 2 + ( y − μ ) 2 ) / σ 2 2 G_σ=1/(2πσ_1σ_2)*e^{-(x-μ)^2/σ_1^2+(y-μ)^2)/σ_2^2} Gσ=1/(2πσ1σ2)∗e−(x−μ)2/σ12+(y−μ)2)/σ22 我们假设一个3*3的高斯核:(我用Excel画的)
将高斯核中每个小格子的坐标带入到高斯分布公式中,就可以得到每个小格子的值。 高斯核中的所有值得核应该为1,因此需要进行归一化处理,即求出每个小格子占所有小格子总和的权重。 高斯核的应用——卷积图像是以像素值来表示的。 如图为一个36*36的灰度图像,每个小格子中都有一个像素值,将高斯核覆盖到图像上,如图红色和黑色格子。计算图像和高斯核对应格子的值,并求其总和,即为黑色格子进行高斯卷积之后所对应的像素值。理论上计算时,通常会对高斯核进行上下镜像,之后再进行计算,但实际应用中通常不考虑该镜像操作。 以此类推,可计算整个图像中所有格子进行卷积后的值。再将这些值输出,即可得到进行高斯卷积之后的图像。 高斯卷积会使得图像丢失最外围的像素。因此通常会在卷积之前,在图像的周围填充一些像素,来保证图像卷积后大小不变。 为什么要求偏导或者梯度? 图像的边缘是由于像素值的突变引起的,因此我们需要通过求偏导或者梯度来获取到突变值发生的位置,提取轮廓。 (公式不好打,上图吧) 常用的几个求偏导和梯度的模板: Prewitt模板算子: M x = [ − 1 0 1 − 1 0 1 − 1 0 1 ] M y = [ 1 1 1 0 0 0 − 1 − 1 − 1 ] M_x = \left[ \begin{array}{ccccc} -1 & 0 & 1\\ -1 & 0 & 1\\ -1 & 0 & 1 \end{array} \right] M_y = \left[ \begin{array}{ccccc} 1 & 1 & 1\\ 0 & 0 & 0\\ -1 & -1 & -1 \end{array} \right] Mx=⎣⎡−1−1−1000111⎦⎤My=⎣⎡10−110−110−1⎦⎤ Sobel模板算子: M x = [ − 1 0 1 − 2 0 2 − 1 0 1 ] M y = [ 1 2 1 0 0 0 − 1 − 2 − 1 ] M_x = \left[ \begin{array}{ccccc} -1 & 0 & 1\\ -2 & 0 & 2\\ -1 & 0 & 1 \end{array} \right] M_y = \left[ \begin{array}{ccccc} 1 & 2 & 1\\ 0 & 0 & 0\\ -1 & -2 & -1 \end{array} \right] Mx=⎣⎡−1−2−1000121⎦⎤My=⎣⎡10−120−210−1⎦⎤ 3.非极大值抑制法由于图像的像素是逐渐进行过渡的,因此我们通过上述过程提取到的边缘会很粗,我们想要得到的图像的边缘应该只有一个像素的粗细。因此我们要提取突变最大的地方作为图像的边缘。 非极大值抑制法,即沿梯度方向,选取梯度强度最大的一个像素块进行保留,将其余像素块舍弃的方法。 比较方法通常为:沿梯度方向,取一像素点,和该像素点前后各一像素的像素点,进行比较,保留最大值。
假设梯度方向是沿x轴方向的,我们需要比较点(-1,0)和点(0,0)两处的梯度强度,若点(0,0)的梯度强度大于(-1,0),则比较(0,0)和(1,0)的梯度强度,若(0,0)小于(1,0),则继续比较(1,0)和(2,0),若(0,0)大于(-1,0)且大于(1,0)则(0,0)最大,可保留,其余的均丢弃,即像素值设为0. 然而实际应用中,梯度方向和边垂直,并不都是水平或者垂直的,因此我们可以选取其所靠近的值,采用不同的权重来计算该点的梯度强度。 如下图。 双阈值滤波是基于如下的假设进行的: 假设,所有噪声所产生的线条与图像的轮廓是不发生连接的。 这样,我们就可以设置两个阈值,一个高阈值,一个低阈值。低阈值用来过滤噪声和突变不明显的线条,高阈值用来保留轮廓线。在低阈值和高阈值之间,且和轮廓线相邻的线条可保留,否则舍弃。 二、代码实现(代码仅供学习参考使用,尚有不足和待优化之处) import math import numpy as np import matplotlib.pyplot as plt # 生成高斯核 def gaussian_create(): sigma1 = sigma2 = 1 gaussian_sum = 0 g = np.zeros([3, 3]) for i in range(3): for j in range(3): g[i, j] = math.exp(-1 / 2 * (np.square(i - 1) / np.square(sigma1) + (np.square(j - 1) / np.square(sigma2)))) / ( 2 * math.pi * sigma1 * sigma2) gaussian_sum = gaussian_sum + g[i, j] g = g / gaussian_sum # 归一化 return g # 产生灰度图 def gray_fuc(rgb): return np.dot(rgb[..., :3], [0.299, 0.587, 0.114]) # 高斯卷积 def gaussian_blur(gray_img, g): ''' gray_img:灰度图 g:高斯核 ''' gray_img = np.pad(gray_img, ((1, 1), (1, 1)), constant_values=0) # 填充 h, w = gray_img.shape new_gray_img = np.zeros([h - 2, w - 2]) for i in range(h - 2): for j in range(w - 2): new_gray_img[i, j] = np.sum(gray_img[i:i + 3, j:j + 3] * g) return new_gray_img # 求高斯偏导 def partial_derivative(new_gray_img): ''' new_gray_img:高斯卷积后的灰度图 ''' new_gray_img = np.pad(new_gray_img, ((0, 1), (0, 1)), constant_values=0) # 填充 h, w = new_gray_img.shape dx_gray = np.zeros([h - 1, w - 1]) # 用来存储x方向偏导 dy_gray = np.zeros([h - 1, w - 1]) # 用来存储y方向偏导 df_gray = np.zeros([h - 1, w - 1]) # 用来存储梯度强度 for i in range(h - 1): for j in range(w - 1): dx_gray[i, j] = new_gray_img[i, j + 1] - new_gray_img[i, j] dy_gray[i, j] = new_gray_img[i + 1, j] - new_gray_img[i, j] df_gray[i, j] = np.sqrt(np.square(dx_gray[i, j]) + np.square(dy_gray[i, j])) return dx_gray, dy_gray, df_gray # 非极大值抑制 def non_maximum_suppression(dx_gray, dy_gray, df_gray): ''' dx_gray:x方向梯度矩阵 dy_gray:y方向梯度矩阵 df_gray:梯度强度矩阵 ''' df_gray = np.pad(df_gray, ((1, 1), (1, 1)), constant_values=0) # 填充 h, w = df_gray.shape for i in range(1, h - 1): for j in range(1, w - 1): if df_gray[i, j] != 0: gx = math.fabs(dx_gray[i - 1, j - 1]) gy = math.fabs(dy_gray[i - 1, j - 1]) if gx > gy: weight = gy / gx grad1 = df_gray[i + 1, j] grad2 = df_gray[i - 1, j] if gx * gy > 0: grad3 = df_gray[i + 1, j + 1] grad4 = df_gray[i - 1, j - 1] else: grad3 = df_gray[i + 1, j - 1] grad4 = df_gray[i - 1, j + 1] else: weight = gx / gy grad1 = df_gray[i, j + 1] grad2 = df_gray[i, j - 1] if gx * gy > 0: grad3 = df_gray[i + 1, j + 1] grad4 = df_gray[i - 1, j - 1] else: grad3 = df_gray[i + 1, j - 1] grad4 = df_gray[i - 1, j + 1] t1 = weight * grad1 + (1 - weight) * grad3 t2 = weight * grad2 + (1 - weight) * grad4 if df_gray[i, j] > t1 and df_gray[i, j] > t2: df_gray[i, j] = df_gray[i, j] else: df_gray[i, j] = 0 return df_gray # 双阈值过滤 def double_threshold(df_gray, low, high): ''' df_gray:梯度强度矩阵 low:低阈值 high:高阈值 ''' h, w = df_gray.shape for i in range(1, h - 1): for j in range(1, w - 1): if df_gray[i, j] high: df_gray[i, j] = 1 elif (df_gray[i, j - 1] > high) or (df_gray[i - 1, j - 1] > high) or ( df_gray[i + 1, j - 1] > high) or (df_gray[i - 1, j] > high) or (df_gray[i + 1, j] > high) or ( df_gray[i - 1, j + 1] > high) or (df_gray[i, j + 1] > high) or (df_gray[i + 1, j + 1] > high): df_gray[i, j] = 1 else: df_gray[i, j] = 0 return df_gray if __name__ == '__main__': # 读取图像 img = plt.imread('C:/Users/Administrator/Desktop/zhongqiu.jpg') # 生成高斯核 gaussian = gaussian_create() # 生成灰度图 gray = gray_fuc(img) # 高斯卷积 new_gray = gaussian_blur(gray, gaussian) # 求偏导 d = partial_derivative(new_gray) dx = d[0] dy = d[1] df = d[2] # 非极大值抑制 new_df = non_maximum_suppression(dx, dy, df) # 双阈值过滤,并将图像转换成转化二值图 low_threshold = 0.15 * np.max(new_df) high_threshold = 0.2 * np.max(new_df) result = double_threshold(new_df, low_threshold, high_threshold) # 输出图像 plt.imshow(result, cmap="gray") plt.axis("off") plt.show() 运行结果(不晓得为啥上次上传的图片显示违规。。。换了张图)上图为原图,下图为提取到的轮廓。运行时间大约44s 上述代码中采用的双阈值过滤函数,是判断弱边周围是否存在强边,来进而确定该弱边是否是我们所需要的边,是否进行滤除。该方法的缺陷: 强边为H,其上有一点a与弱边相连。该弱边为L,其上有一点b和一点c,b点和a点相连。 如果,在判断弱边是否滤除的时候,先判断b点,后判断c点,得知b点和a点相连,b点设为1值保留,c点和b点相连,因此c点也设为1值保留 如果,先判断c点,后判断b点,那么得出的结论是:c点周围没有1值,丢弃。这将导致我们丢失掉我们想要的点 因此改变双阈值过滤函数的算法思想,判断强边周围是否存在弱边,即通过强边延伸弱边。这样可以使我们提取到的边更加的完整。 # 双阈值过滤 def double_threshold(dx_gray, dy_gray, df_gray, low, high): ''' dx_gray:x方向梯度矩阵 dy_gray:y方向梯度矩阵 df_gray:梯度强度矩阵 low:低阈值 high:高阈值 ''' h, w = df_gray.shape for i in range(1, h - 1): for j in range(1, w - 1): if df_gray[i, j] = high: df_gray[i, j] = 1 if dy_gray[i-1, j-1] * dx_gray[i-1, j-1] > 0: # dx,dy同向 if df_gray[i - 1, j + 1] > low: df_gray[i - 1, j + 1] = high if df_gray[i + 1, j - 1] > low: df_gray[i + 1, j - 1] = high if dy_gray[i-1, j-1] > dx_gray[i-1, j-1]: if df_gray[i, j + 1] > low: df_gray[i, j + 1] = high if df_gray[i, j - 1] > low: df_gray[i, j - 1] = high else: if df_gray[i - 1, j] > low: df_gray[i - 1, j] = high if df_gray[i + 1, j] > low: df_gray[i + 1, j] = high else: if df_gray[i - 1, j - 1] > low: df_gray[i - 1, j - 1] = high if df_gray[i + 1, j + 1] > low: df_gray[i + 1, j + 1] = high if math.fabs(dy_gray[i-1, j-1]) > math.fabs(dx_gray[i-1, j-1]): if df_gray[i, j + 1] > low: df_gray[i, j + 1] = high if df_gray[i, j - 1] > low: df_gray[i, j - 1] = high else: if df_gray[i - 1, j] > low: df_gray[i - 1, j] = high if df_gray[i + 1, j] > low: df_gray[i + 1, j] = high else: df_gray[i, j] = 0 return df_gray 优化结果:优化后,运行时间增加了 ̄□ ̄||,为46s,不过值得一提是,提取的轮廓质量更好了。原先想要的但是没能够输出的边,竟然输出了! 而且花瓣的轮廓提取更加连续了。 如下上图为未优化前提取的轮廓,下图为优化后提取的轮廓。效果还是不错的。 基本实现了图像轮廓的提取,但是运行时间较长,代码还需要优化。 参考资料:canny 算子python实现 |
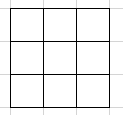 设高斯核中小格子的坐标为(x,y), 高斯核中间的小格子为(0,0),左上角的小格子为(-1,-1),以此类推。
设高斯核中小格子的坐标为(x,y), 高斯核中间的小格子为(0,0),左上角的小格子为(-1,-1),以此类推。
 求偏导或者梯度函数,其本质上还是和高斯卷积是类似的。
求偏导或者梯度函数,其本质上还是和高斯卷积是类似的。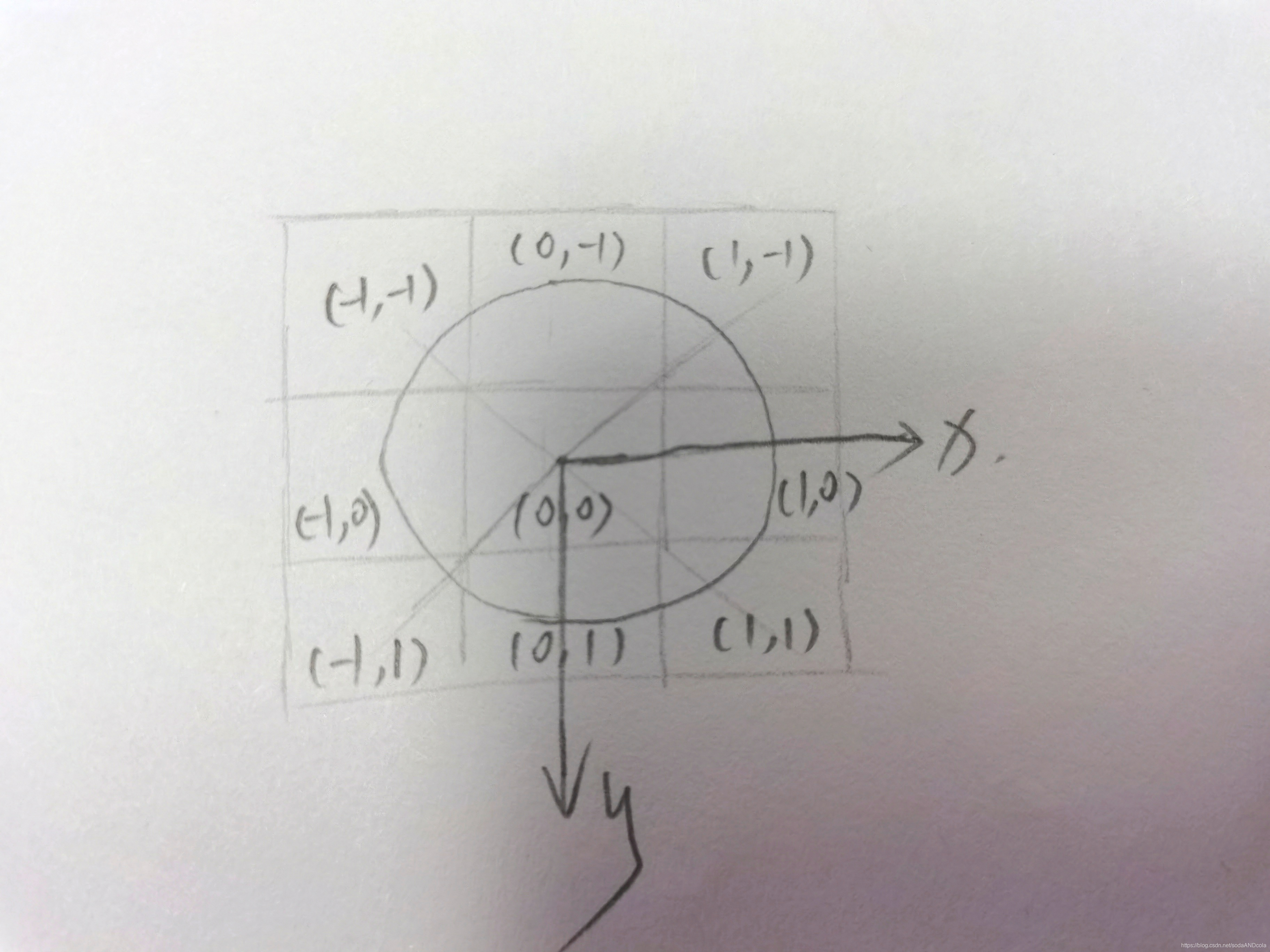 如图,假设该3*3的核的每一个格子均在所提出的轮廓线上。
如图,假设该3*3的核的每一个格子均在所提出的轮廓线上。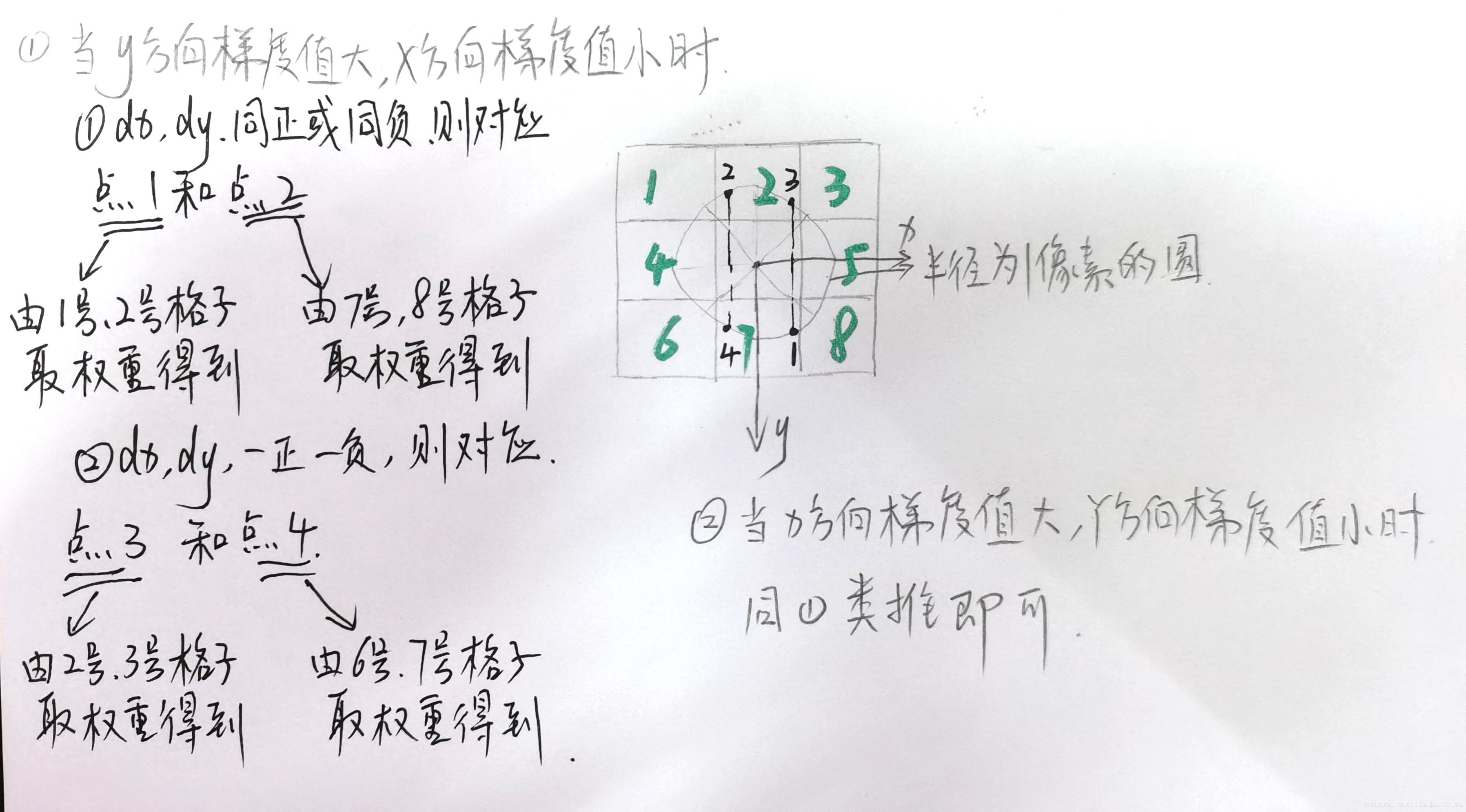
 更换图片,则要根据需要调整双阈值滤波的高低阈值大小,来获得满意的输出。
更换图片,则要根据需要调整双阈值滤波的高低阈值大小,来获得满意的输出。

【本文地址】