| 使用ABBYY FineReader PDF 15识别图片上的文本信息 | 您所在的位置:网站首页 › pdf怎么识别文字 › 使用ABBYY FineReader PDF 15识别图片上的文本信息 |
使用ABBYY FineReader PDF 15识别图片上的文本信息
|
ABBYY FineReader PDF 15作为一款专业OCR文字识别软件,可以轻松识别图片、PDF文件上的文字。今天,我就向大家演示一下,如何使用ABBYY FineReader PDF 15识别图片上的文本信息。 软件版本及系统:Camtasia 2021;Windows10系统 一、识别文字 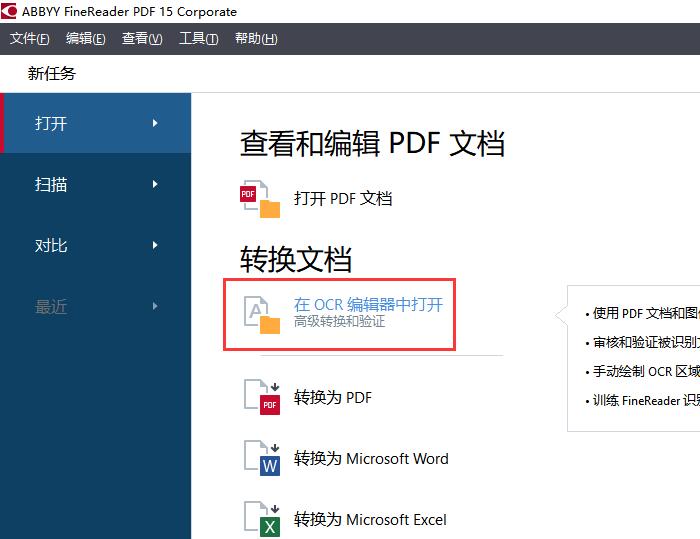 图1:在OCR编辑器中打开 图1:在OCR编辑器中打开如图1所示,进入ABBYY FineReader PDF 15,在界面中央,找到并点击“在OCR编辑器中打开”。 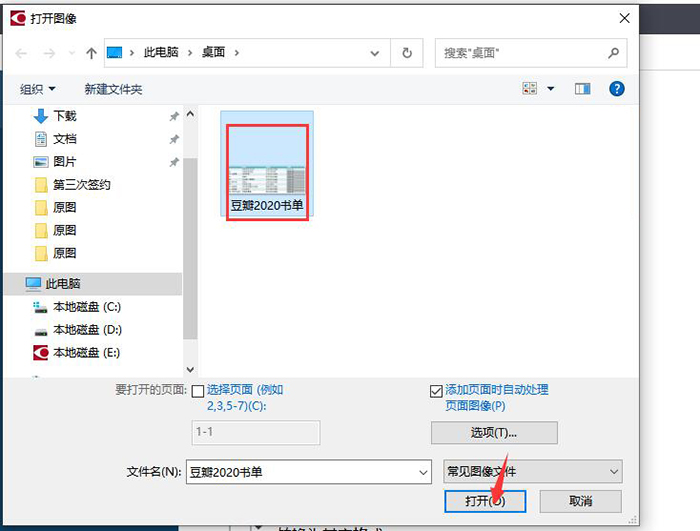 图2:导入识别图片(图片自制) 图2:导入识别图片(图片自制)如图2所示,找到需要识别的图片,点击打开即可。 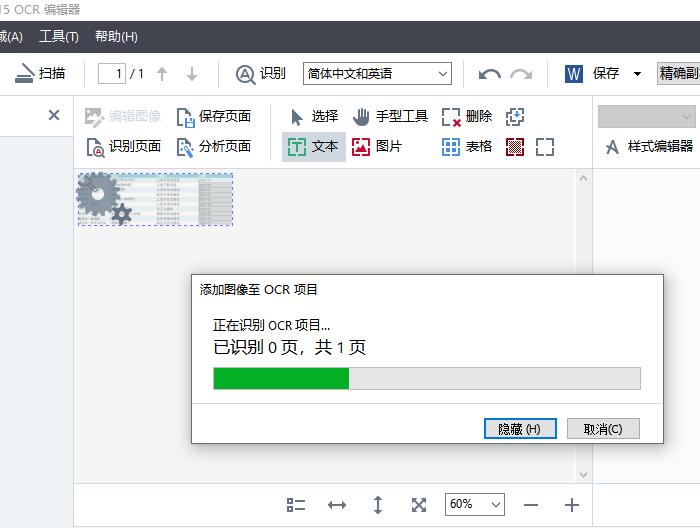 图3:正在识别OCR项目 图3:正在识别OCR项目如图3所示,导入图片后,软件会自动对图片上的文字进行识别。 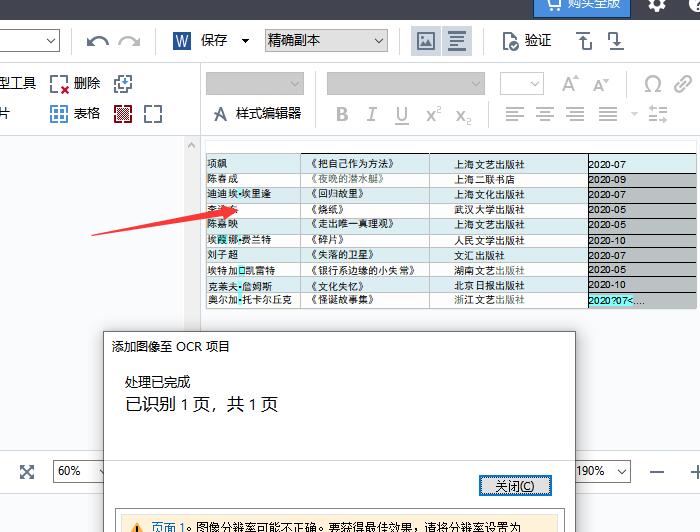 图4:显示完成的内容 图4:显示完成的内容识别完成后,在界面右侧可以看到处理完成的文本内容。我们可以看到,在识别结果中,有一部分文字带有蓝色底纹。这就表示此处所识别的信息存在争议,需要我们手动进行调整。 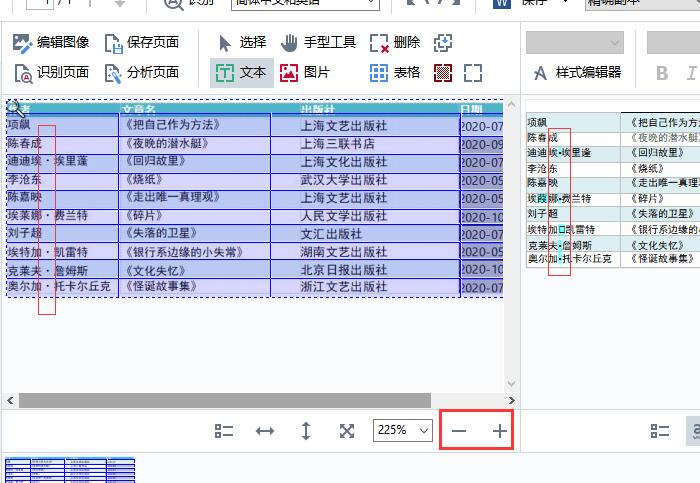 图5:左右对比调整 图5:左右对比调整界面左侧是原始图片的显示窗口,我们可以使用底部的“加号、减号”,调整图片的视图大小。通过对比图片,手动修改右侧的识别结果即可。 二、另存为文档 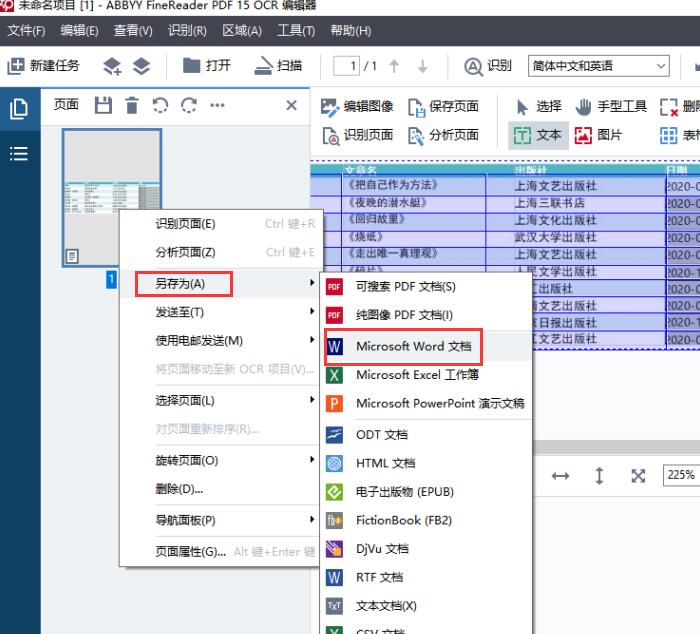 图6:存储为Word文档 图6:存储为Word文档识别完成后,可以直接将结果保存为word文档格式。如图6所示,选中左侧页面窗口中的图片,右键打开快进菜单栏,依次选择“另存为——Microsoft Word文档”。 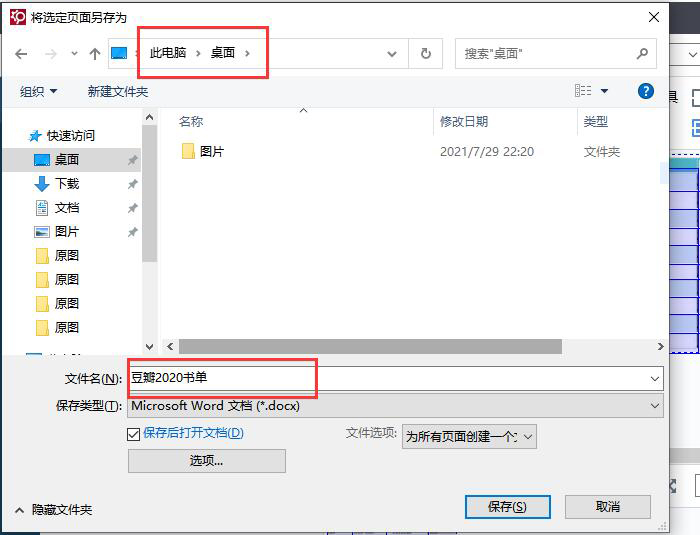 图7:选择存储位置 图7:选择存储位置随后,会弹出文件的另存窗口,在这里,我们可以设置文件的存储位置和文件的名称。设置完成后,点击“保存”即可。 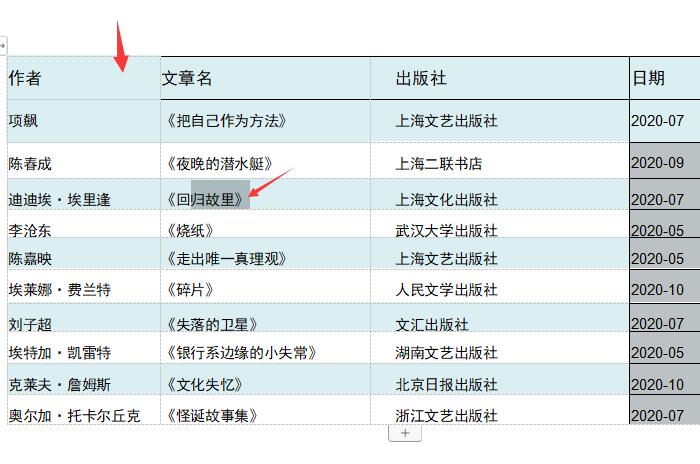 图8:Word文档内显示 图8:Word文档内显示保存完成后的Word文档会自动打开,如图8所示,不仅包括图片中的文字内容,同时还识别出了图片的边框底纹格式。我们可以在Word文档中进行进一步的编辑和修改。 以上,就是使用ABBYY识别图片文本信息的全过程了。通过这个方法,可以快速提取出图片上的文字,同时还能识别出图片上的文本格式,更加方便我们的后期编辑和修改。如此实用的软件,大家也快来试试吧! 作者:吴朗 |
【本文地址】