| Hadoop支持的文件格式之Parquet | 您所在的位置:网站首页 › parquet成就 › Hadoop支持的文件格式之Parquet |
Hadoop支持的文件格式之Parquet
|
文章目录
0x00 文章内容0x01 行存储与列存储1. Avro与Parquet
0x02 编码实现Parquet格式的读写1. 编码实现读写Parquet文件2. 查看读写Parquet文件结果3. 编码实现读写Parquet文件(HDFS)4. 查看读写Parquet文件(HDFS)结果
0x03 彩蛋0xFF 总结
0x00 文章内容
行存储与列存储编码实现Parquet格式的读写彩蛋
0x01 行存储与列存储
1. Avro与Parquet
a. 请参考文章:Hadoop支持的文件格式之Avro的0x01 行存储与列存储 0x02 编码实现Parquet格式的读写 1. 编码实现读写Parquet文件a. 引入Parquet相关jar包 org.apache.parquet parquet-column 1.8.1 org.apache.parquet parquet-hadoop 1.8.1b. 完整的写Parquet文件代码(写到HDFS) package com.shaonaiyi.hadoop.filetype.parquet; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.parquet.column.ParquetProperties; import org.apache.parquet.example.data.Group; import org.apache.parquet.example.data.GroupFactory; import org.apache.parquet.example.data.simple.SimpleGroupFactory; import org.apache.parquet.hadoop.ParquetWriter; import org.apache.parquet.hadoop.example.GroupWriteSupport; import org.apache.parquet.hadoop.metadata.CompressionCodecName; import org.apache.parquet.schema.MessageType; import org.apache.parquet.schema.MessageTypeParser; import java.io.IOException; /** * @Author [email protected] * @Date 2019/12/18 10:14 * @Description 编码实现写Parquet文件 */ public class ParquetFileWriter { public static void main(String[] args) throws IOException { MessageType schema = MessageTypeParser.parseMessageType("message Person {\n" + " required binary name;\n" + " required int32 age;\n" + " required int32 favorite_number;\n" + " required binary favorite_color;\n" + "}"); Configuration configuration = new Configuration(); Path path = new Path("hdfs://master:9999/user/hadoop-sny/mr/filetype/parquet/data.parquet"); GroupWriteSupport writeSupport = new GroupWriteSupport(); GroupWriteSupport.setSchema(schema, configuration); ParquetWriter writer = new ParquetWriter(path, writeSupport, CompressionCodecName.SNAPPY, ParquetWriter.DEFAULT_BLOCK_SIZE, ParquetWriter.DEFAULT_PAGE_SIZE, ParquetWriter.DEFAULT_PAGE_SIZE, ParquetWriter.DEFAULT_IS_DICTIONARY_ENABLED, ParquetWriter.DEFAULT_IS_VALIDATING_ENABLED, ParquetProperties.WriterVersion.PARQUET_1_0, configuration); GroupFactory groupFactory = new SimpleGroupFactory(schema); Group group = groupFactory.newGroup() .append("name", "shaonaiyi") .append("age", 18) .append("favorite_number", 7) .append("favorite_color", "red"); writer.write(group); writer.close(); } }c. 完整的读Parquet文件代码(从HDFS读) package com.shaonaiyi.hadoop.filetype.parquet; import org.apache.hadoop.fs.Path; import org.apache.parquet.example.data.Group; import org.apache.parquet.hadoop.ParquetReader; import org.apache.parquet.hadoop.example.GroupReadSupport; import java.io.IOException; /** * @Author [email protected] * @Date 2019/12/18 10:18 * @Description 编码实现读Parquet文件 */ public class ParquetFileReader { public static void main(String[] args) throws IOException { Path path = new Path("hdfs://master:9999/user/hadoop-sny/mr/filetype/parquet/parquet-data.parquet"); GroupReadSupport readSupport = new GroupReadSupport(); ParquetReader reader = new ParquetReader(path, readSupport); Group result = reader.read(); System.out.println("name:" + result.getString("name", 0).toString()); System.out.println("age:" + result.getInteger("age", 0)); System.out.println("favorite_number:" + result.getInteger("favorite_number", 0)); System.out.println("favorite_color:" + result.getString("favorite_color", 0)); } } 2. 查看读写Parquet文件结果a. 写Parquet文件 a. 引入Parquet与Avro关联的jar包 org.apache.parquet parquet-avro 1.8.1从上面的代码我们可以看出,以下面这种方式定义Schema很不友好: MessageType schema = MessageTypeParser.parseMessageType("message Person {\n" + " required binary name;\n" + " required int32 age;\n" + " required int32 favorite_number;\n" + " required binary favorite_color;\n" + "}");所以我们可以将Parquet与Avro关联,直接使用Avro的Schema即可。 b. 完整的写Parquet文件代码(HDFS) package com.shaonaiyi.hadoop.filetype.parquet; import com.shaonaiyi.hadoop.filetype.avro.Person; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.task.JobContextImpl; import org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl; import org.apache.parquet.avro.AvroParquetOutputFormat; import java.io.IOException; /** * @Author [email protected] * @Date 2019/12/18 10:47 * @Description 编码实现写Parquet文件(HDFS) */ public class MRAvroParquetFileWriter { public static void main(String[] args) throws IOException, IllegalAccessException, InstantiationException, ClassNotFoundException, InterruptedException { //1 构建一个job实例 Configuration hadoopConf = new Configuration(); Job job = Job.getInstance(hadoopConf); //2 设置job的相关属性 job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Person.class); job.setOutputFormatClass(AvroParquetOutputFormat.class); //AvroJob.setOutputKeySchema(job, Schema.create(Schema.Type.INT)); AvroParquetOutputFormat.setSchema(job, Person.SCHEMA$); //3 设置输出路径 FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9999/user/hadoop-sny/mr/filetype/avro-parquet")); //4 构建JobContext JobID jobID = new JobID("jobId", 123); JobContext jobContext = new JobContextImpl(job.getConfiguration(), jobID); //5 构建taskContext TaskAttemptID attemptId = new TaskAttemptID("attemptId", 123, TaskType.REDUCE, 0, 0); TaskAttemptContext hadoopAttemptContext = new TaskAttemptContextImpl(job.getConfiguration(), attemptId); //6 构建OutputFormat实例 OutputFormat format = job.getOutputFormatClass().newInstance(); //7 设置OutputCommitter OutputCommitter committer = format.getOutputCommitter(hadoopAttemptContext); committer.setupJob(jobContext); committer.setupTask(hadoopAttemptContext); //8 获取writer写数据,写完关闭writer RecordWriter writer = format.getRecordWriter(hadoopAttemptContext); Person person = new Person(); person.setName("shaonaiyi"); person.setAge(18); person.setFavoriteNumber(7); person.setFavoriteColor("red"); writer.write(null, person); writer.close(hadoopAttemptContext); //9 committer提交job和task committer.commitTask(hadoopAttemptContext); committer.commitJob(jobContext); } }c. 完整的读Parquet文件代码(HDFS) package com.shaonaiyi.hadoop.filetype.parquet; import com.shaonaiyi.hadoop.filetype.avro.Person; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.task.JobContextImpl; import org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl; import org.apache.parquet.avro.AvroParquetInputFormat; import java.io.IOException; import java.util.List; import java.util.function.Consumer; /** * @Author [email protected] * @Date 2019/12/18 10:52 * @Description 编码实现读Parquet文件(HDFS) */ public class MRAvroParquetFileReader { public static void main(String[] args) throws IOException, IllegalAccessException, InstantiationException { //1 构建一个job实例 Configuration hadoopConf = new Configuration(); Job job = Job.getInstance(hadoopConf); //2 设置需要读取的文件全路径 FileInputFormat.setInputPaths(job, "hdfs://master:9999/user/hadoop-sny/mr/filetype/avro-parquet"); //3 获取读取文件的格式 AvroParquetInputFormat inputFormat = AvroParquetInputFormat.class.newInstance(); AvroParquetInputFormat.setAvroReadSchema(job, Person.SCHEMA$); //AvroJob.setInputKeySchema(job, Person.SCHEMA$); //4 获取需要读取文件的数据块的分区信息 //4.1 获取文件被分成多少数据块了 JobID jobID = new JobID("jobId", 123); JobContext jobContext = new JobContextImpl(job.getConfiguration(), jobID); List inputSplits = inputFormat.getSplits(jobContext); //读取每一个数据块的数据 inputSplits.forEach(new Consumer() { @Override public void accept(InputSplit inputSplit) { TaskAttemptID attemptId = new TaskAttemptID("jobTrackerId", 123, TaskType.MAP, 0, 0); TaskAttemptContext hadoopAttemptContext = new TaskAttemptContextImpl(job.getConfiguration(), attemptId); RecordReader reader = null; try { reader = inputFormat.createRecordReader(inputSplit, hadoopAttemptContext); reader.initialize(inputSplit, hadoopAttemptContext); while (reader.nextKeyValue()) { System.out.println(reader.getCurrentKey()); Person person = reader.getCurrentValue(); System.out.println(person); } reader.close(); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } }); } } 4. 查看读写Parquet文件(HDFS)结果a. 写Parquet文件(HDFS)  HDFS上也有数据了 HDFS上也有数据了 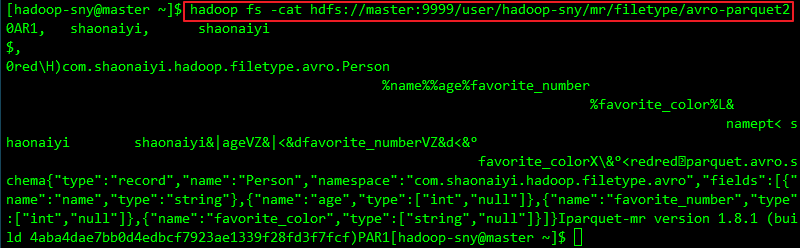 0xFF 总结
在MapReduce作业中如何使用:
job.setInputFormatClass(AvroParquetInputFormat.class);
AvroParquetInputFormat.setAvroReadSchema(job, Person.SCHEMA$);
job.setOutputFormatClass(ParquetOutputFormat.class);
AvroParquetOutputFormat.setSchema(job, Person.SCHEMA$);
文章:网站用户行为分析项目之会话切割(二) 中 9. 保存统计结果 时就是以Parquet的格式保存下来的。Hadoop支持的文件格式系列: Hadoop支持的文件格式之Text Hadoop支持的文件格式之Avro Hadoop支持的文件格式之Parquet Hadoop支持的文件格式之SequenceFile
0xFF 总结
在MapReduce作业中如何使用:
job.setInputFormatClass(AvroParquetInputFormat.class);
AvroParquetInputFormat.setAvroReadSchema(job, Person.SCHEMA$);
job.setOutputFormatClass(ParquetOutputFormat.class);
AvroParquetOutputFormat.setSchema(job, Person.SCHEMA$);
文章:网站用户行为分析项目之会话切割(二) 中 9. 保存统计结果 时就是以Parquet的格式保存下来的。Hadoop支持的文件格式系列: Hadoop支持的文件格式之Text Hadoop支持的文件格式之Avro Hadoop支持的文件格式之Parquet Hadoop支持的文件格式之SequenceFile
作者简介:邵奈一 全栈工程师、市场洞察者、专栏编辑 | 公众号 | 微信 | 微博 | CSDN | 简书 | 福利: 邵奈一的技术博客导航 邵奈一 原创不易,如转载请标明出处。 |
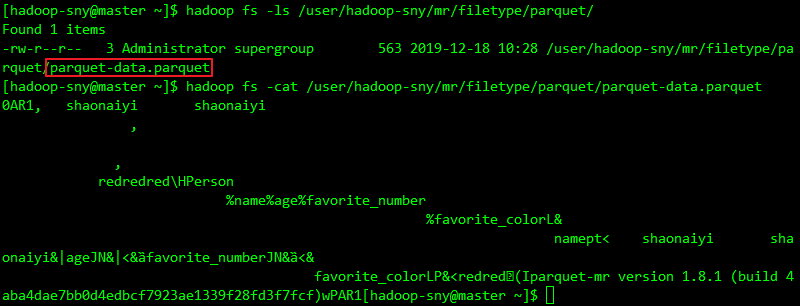 b. 读Parquet文件
b. 读Parquet文件 
 b. 读Parquet文件(HDFS),Key没有设置值
b. 读Parquet文件(HDFS),Key没有设置值 
【本文地址】
公司简介
联系我们