| 我总结了15个最新的数据科学面试题,助你拿到高薪Offer | 您所在的位置:网站首页 › pandas计算特征的方差 › 我总结了15个最新的数据科学面试题,助你拿到高薪Offer |
我总结了15个最新的数据科学面试题,助你拿到高薪Offer
|
介绍 在本文中,我整理了一份包含 15 个数据科学问题的列表,其中包括一个具有挑战性的问题,可以帮助您解决数据科学工作。这些数据科学问题是基于我参加各种采访的经验。 本文包含基于以下内容的数据科学问题: – 数据科学中的概率、统计和线性代数 – 机器学习的不同算法 这篇文章有什么特别之处? 在这篇文章中,我给出了一个具有挑战性的数据科学问题,它让你对数据科学概念有了更广泛的思考。 客观数据科学问题1.从给定的主成分中,应用主成分分析(PCA)后,以下哪个可以是前两个主成分? (a) [1,2] 和 [2,-1] (b) [1/2,√3/2] 和 [√3/2,-1/2] (c) [1,3] 和 [2,3] (d) [1,4] 和 [3,5] 答案:选项-(b) 主成分分析 (PCA)找到具有最大数据方差的方向。它找到相互正交的方向,并将计算的主成分归一化。因此,对于所有给定的选项,只有选项-b 将满足 PCA 算法中主成分的所有属性。 2. 以下哪些概率分布不能应用独立分量分析(ICA)? (a) 均匀分布 (b) 高斯分布 (c) 指数分布 (d) 以上都不是 答案:选项-(b) 我们不能将独立分量分析 (ICA) 应用于高斯或正态变量,因为这些分布是对称的。基本上,这是我们在应用独立分量分析 (ICA) 算法时必须牢记的约束。 3. 在线性判别分析(LDA)的情况下选择正确的选项: (a) LDA 最大化类之间的距离并最小化类内的距离 (b) LDA 最小化类距离之间和类内的距离 (c) LDA 最小化类之间的距离并最大化类内的距离 (d) LDA 最大化类距离之间和类内的距离 答案:选项-(a) LDA 试图通过线性判别函数最大化类间方差并最小化类内方差。它假设每个类中的数据都由具有相同协方差的正态分布描述。 4. 考虑以下关于分类变量的陈述: 陈述 1:一个分类变量有大量的类别 陈述 2:分类变量具有少量类别 以下内容哪些是对的? (a) 第一条语句的增益率优于信息增益 (b) 对于第二个陈述,增益率优于信息增益 (c) 类别不决定增益率和信息增益的偏好 (d) 以上都不是 答案:选项-(a) 当我们有大量特征时,会发生大量计算来计算信息增益,而另一方面,对于增益比,我们必须简单地计算比率而不是单独计算事物. 因此,对于我们手中的大量特征,我们在使用与分类变量相关的决策树相关的机器学习算法的同时,更倾向于增益比。 5. 考虑 2 个特征:特征 1 和特征 2 的值为 Yes 和 No 特点一:9 是和 7 否 特征 2:12 是和 4 否 对于所有这 16 个实例,哪个特征将具有更多熵? (a) 特色一 (b) 特色 2 (c) 特征 1 和特征 2 都具有相同的熵 (d) 数据不足,无法决定 答案:选项-(a) 对于二分类问题,熵定义为: 熵 = -(P(class0) * log 2 (P(class0)) + P(class1) * log 2 (P(class1))) 现在,该特征 X 中共有 7 个否和 9 个是。因此,通过将 7/16 和 9/16 的值放入上述公式,我们得到熵的值为 0.988。 同样,我们也可以计算其他特征,然后我们可以轻松进行比较。 6. 当 bagging 应用于回归树时,下列哪项是正确的: S1:每棵树都有高方差和低偏差 S2:我们取所有回归树的平均值 S3:n个引导样本有n个回归树 (a) S1 和 S3 是正确的 (b) 只有 S2 是正确的 (c) S2 和 S3 是正确的 (d) 全部正确 答案:选项-(d) Bagging 是一种集成技术,我们从训练数据中形成引导样本,对于每个样本,我们训练一个弱分类器,最后,对于测试数据集的预测,我们结合所有弱学习器的结果. 结果的平均有助于我们减少方差,同时保持偏差近似恒定。 7. 确定具有以下值的特征 (X) 的熵: X = [0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1] (一) -0.988 (b) 0.988 (c) -0.05 (d) 0.05 答案:选项-(b) 对于二分类问题(比如 A 和 B),熵定义为: 熵 = -(P(class-A) * log 2 (P(class-A)) + P(class-B) * log 2 (P(class-B))) 现在,该特征 X 中共有 7 个 0 和 9 个 1。因此,通过将 7/16 和 9/16 的值放入上述公式,我们得到熵值为 0.988。 8. 对于独立成分分析 (ICA) 估计,下列选项中哪些是正确的? (a) 变量的负熵和互信息总是非负的。 (b) 对于统计独立变量,互信息为零。 (c) 对于统计上的独立变量,互信息应该是最小的,并且 负熵应该是最大的 (d) 以上所有。 答案:选项-(d) 以下是 ICA 算法的真实情况: – 对于我们算法中涉及的任何变量,负熵和互信息的符号总是非负的。 – 但是如果我们有统计上的独立变量,那么互信息为零。 – 此外,对于统计独立变量,相互信息的值将是最小的,而另一方面,负熵应该是最大的。 9.在主成分分析(PCA)的情况下,如果所有特征向量都相同,那么我们不能选择主成分,因为, (a) 所有主成分为零 (b) 所有主成分相等 (c) 无法确定主成分 (d) 以上都不是 答案:选项-(b) 在 PCA 算法(一种无监督机器学习算法)的情况下,如果所有特征向量都相同,那么我们无法选择主成分,因为在这种情况下,所有主成分都相等。 主观数据科学问题10. 一个社会有 70% 的男性和 30% 的女性。每个人都有一个红色或蓝色的球。众所周知,5% 的男性和 10% 的女性有红色的球。如果随机选择一个人并发现有蓝色球。计算这个人是男性的概率。 解决方案:(0.711) 这里我们使用条件概率的概念。 P(b|m)*P(m)/[P(b|m)*P(m) + P(b|f)*p(f)] = 0.95*0.7 / (0.95*0.7+0.9*0.3 ) = 0.711 11. 您正在使用支持向量机 (SVM) 开发垃圾邮件分类系统。“垃圾邮件”是正类(y=1),“非垃圾邮件”是负类(y=0)。您已经训练了分类器,并且验证集中有 m=1000 个示例。预测类与实际类的混淆矩阵如下图所示: 实际班级:1实际等级:0预测等级:185890预测等级:015 10分类器的平均准确率和分类准确率是多少(基于上述混淆矩阵)? 提示:平均分类准确度:(TP+TN)/(TP+TN+FP+FN) 分类准确率:[TN/(TN+FP)+TP/(TP+FN)]/2 其中,TP = 真阳性,FP = 假阳性,FN = 假阴性,TN = 真阴性。 理解型题考虑一组具有坐标 {(-3,-3), (-1,-1),(1,1),(3,3)} 的二维数据点。我们希望使用主成分分析(PCA)算法将这些点的维度减少 1。假设 sqrt(2)=1.414 的值。现在,回答以下问题: 12.求数据矩阵XX T的特征值(X T表示X矩阵的转置) 13. 求权重矩阵 W。 14. 找到给定数据的降维。 解:这里原始数据驻留在R 2即二维空间中,我们的目标是将数据的维数降为1,即一维数据⇒K =1 我们尝试一步步解决这组问题,让你对PCA算法所涉及的步骤有一个清晰的认识: 步骤 1:获取数据集这里数据矩阵X由 [ [ -3, -1, 1 ,3 ], [ -3, -1, 1, 3 ] ] 步骤 2:计算平均向量 (µ)平均向量:[ {-3+(-1)+1+3}/4, {-3+(-1)+1+3}/4 ] = [ 0, 0 ] 步骤 3:从给定数据中减去均值由于这里的均值向量为 0, 0,因此在从均值中减去所有点时,我们得到相同的数据点。 第四步:计算协方差矩阵因此,协方差矩阵变为 XX T,因为均值在原点。 因此,XX T变为 [ [ -3, -1, 1 ,3 ], [ -3, -1, 1, 3 ] ] ( [ [ -3, -1, 1 ,3 ], [ -3, -1 , 1, 3 ] ] ) = [ [ 20, 20 ], [ 20, 20 ] ] Step-5:确定协方差矩阵的特征向量和特征值det(C-λI)=0 将特征值设为 0 和 40。 现在,从计算中选择最大特征值,并使用等式 CX = λX 找到对应于 λ = 40 的特征向量: 因此,我们得到特征向量为 (1/√ 2 ) [ 1, 1 ] 因此,矩阵 XX T的特征值为0 和 40。 Step-6:选择主成分并形成权重向量这里,U = R 2×1等于最大特征值对应的 XX T的特征向量。 现在,C=XX T的特征值分解 W(权重矩阵)是 U 矩阵的转置,并作为行向量给出。 因此,权重矩阵由 [1 1]/1.414 给出 步骤 7:通过对权重向量进行投影得出新数据集现在,得到降维数据为 x i = U T X i = WX i x 1 = WX 1 = (1/√ 2 ) [ 1, 1 ] [ -3, -3 ] T = – 3√ 2 x 2 = WX 2 = (1/√ 2) [ 1, 1 ] [ -1, -1 ] T = – √ 2 x 3 = WX 3 = (1/√ 2) [ 1, 1 ] [ 1, 1] T = – √ 2 x 4 = WX 4 = (1/√ 2 ) [ 1, 1 ] [ 3, 3 ] T = – 3√ 2 因此,降维将等于 {-3*1.414, -1.414,1.414, 3*1.414}。 具有挑战性的问题15. 给定一个数据集,包含 N 个数据点和 d=2 个特征,由输入 X ∈ Rn×d和标签 y ∈ ( -1, 1 } N组成,如图所示, 假设我们想学习以给定固定点 c 为中心的圆的(未知)半径 r,使得该圆以最小的误差将两个类分开。为此,我们需要找到使某个合适的成本函数 E(r) 最小化的参数 r(radius)。你将如何设计/定义这个成本函数 E(r)?另外,证明为什么/如何选择成本函数?
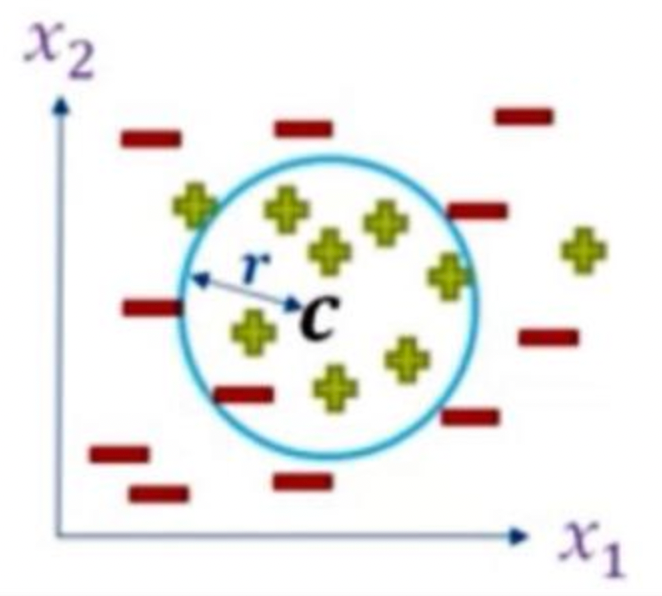 图片来源-1 一种可能的解决方案: E(r) = 1/N Σ max { ( ||x (i ) – c|| – r ) y (i) , 0 } 基本上,在这个可能的解决方案中,我们试图找到所有点与特定中心的距离,然后找到该距离与所提到圆的半径之间的差异,然后将其乘以该数据点的特定标签,然后然后尝试找到这个值和零之间的最大值,然后最后取我们在对所有数据点求和后得到的所有值的平均值。对于给定的问题陈述,这是我们可以想到的一个简单的解决方案。 开放讨论 注意:这个问题没有唯一的答案。我把这个问题放在这个部分,以便大家思考这个问题,我们将在评论框中讨论这个问题。 但是,我为这个问题提供了一种可能的解决方案,只是为了提供一条思考给定问题的一些不同解决方案的途径。 我希望你喜欢这篇关于数据科学问题的文章。如果你喜欢它,也分享给你的朋友。 没有提及或想分享您的想法?请随时在下面发表评论,我会尽快回复您。 参考: 图片来源 1- https://docs.google.com/document/d/1giE8zqn7O1LsM0CsXO9_QFdF4QW3VMQNEFlZsjY_QgA/edit?usp=sharing 原文标题:Data Science Interview Questions: Land to your Dream Job 原文作者:CHIRAG GOYAL 原文地址:https://www.analyticsvidhya.com/blog/2022/01/data-science-interview-questions-land-to-your-dream-job/ |
【本文地址】