| python抓取数据,pandas 处理并存储为excel | 您所在的位置:网站首页 › pandas写Excel › python抓取数据,pandas 处理并存储为excel |
python抓取数据,pandas 处理并存储为excel
|
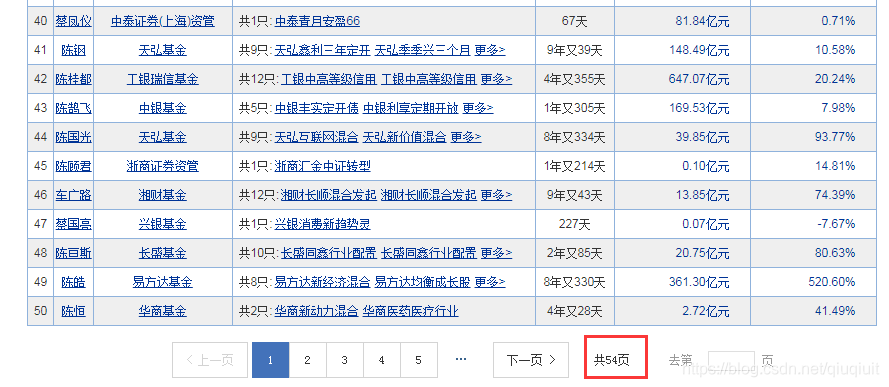
pandas书看了一段时间了,但是一直没有实践过,这周有空就来试试,先看网站:
总共有54页,每页50条数据,其实最简单的办法是:直接复制数据,然后粘贴到excel里面,只需要粘贴54次,也不算太复杂。因为写这个程序的时间绝对比复制粘贴的时间要多。 但是做技术的嘛,总容易陷入唯技术论,所以我们就来试试用python抓取数据,用pandas包装数据,然后存储为excel表格。 一、获取数据 首先,本人想到的是用requests框架获取这个网页的源代码,再把源代码内的表格数据通过BeautifulSoup框架提取出来,然而实际情况是,获取后的源代码中并没有数据,只有这个:
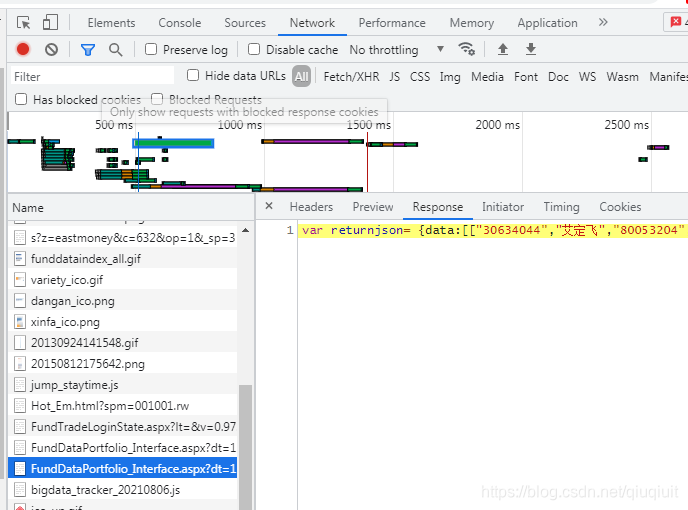
也就是说,表格里面的数据很可能是用 ajax类似的技术动态获取的,那么下一步我们就要找到获取数据的网址,在 chrome中按F12,刷新后查看延时稍微长一点的,很容易找到:
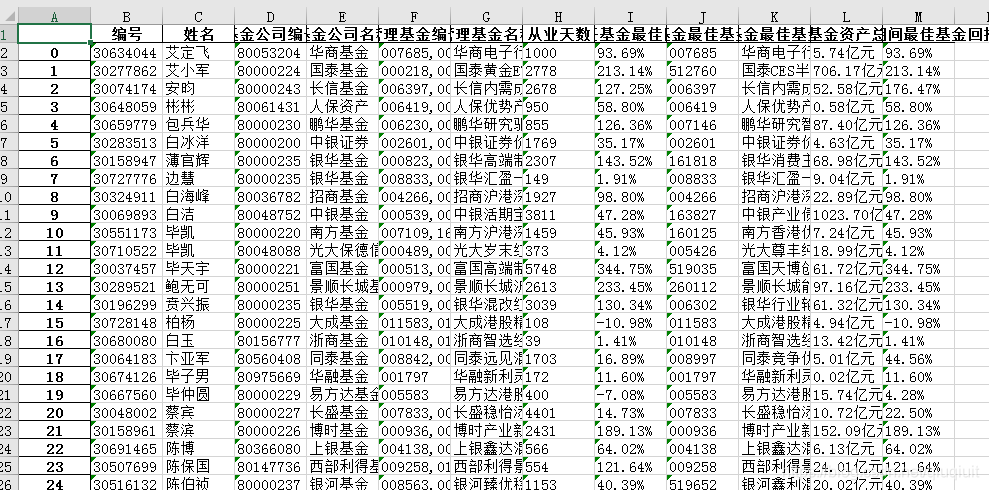
可以看出,上面的网址会返回一段js代码,data变量里面就包含当前页的数据,但是这个json数据格式不规范,在js里面可能可以解析,但是在pandas里面是不能解析的,因为类似data的变量,没有加引号。 二、解析数据 直接上代码: # -*- coding: UTF-8 -*- import requests import json import pandas as pd #创建一个DataFrame,用于保存到excel中 df = pd.DataFrame(columns=('编号','姓名','基金公司编号','基金公司名称','管理基金编号', '管理基金名称','从业天数','现任基金最佳回报','现任基金最佳基金编号', '现任基金最佳基金名称','现任基金资产总规模','任职期间最佳基金回报')) for pageNo in range(1,55):#一共54页 url='http://fund.********.com/Data/FundDataPortfolio_Interface.aspx?dt=14&mc=returnjson&ft=all&pn=50&pi={}&sc=abbname&st=asc'.format(pageNo) print(url) reponse = requests.get(url) _json = reponse.text start = _json.find("[[") end = _json.find("]]") list_str = _json[start:end+2]#只取[[ ]]及以内的数据,如[["30634044","艾定飞"]] datalist = eval(list_str)#把字符串解析成python数据列表 for i,arr in enumerate(datalist): index = i+(pageNo-1)*50 #插入新数据时要添加索引 df.loc[index] = arr #一次插入一行数据 df.to_excel("test.xlsx")上面代码虽然看起来简单,但是这个探索的过程却比较复杂,最终实现效果:
总结: 本人初次实践pandas,遇见了不少的困难。 1.数据抓取时,重在分析。用什么方式获取,用什么方式解析,这个思考的过程远大于写代码的过程。 2.pandas与excel相互结合。我也看过一些关于pandas与excel谁更好的文章,对大多数人来说excel更直观,单独说的话,pandas相对excel并没有什么明显的优势。但是如果pandas与python结合起来的话,更容易发挥优势。比如上面的例子,我用python获取数据,再用pandas解析,再存储为excel,把它们的优势结合起来,效果会更好。如果单独使用excel,实现起来要困难得多。 |

【本文地址】