|
我们爬取数据需要进行保存,还有一个介绍如何保存到txt文本的:文本保存 本次介绍如何保存到csv等Excel中,我以保存排行榜的部分信息为例: 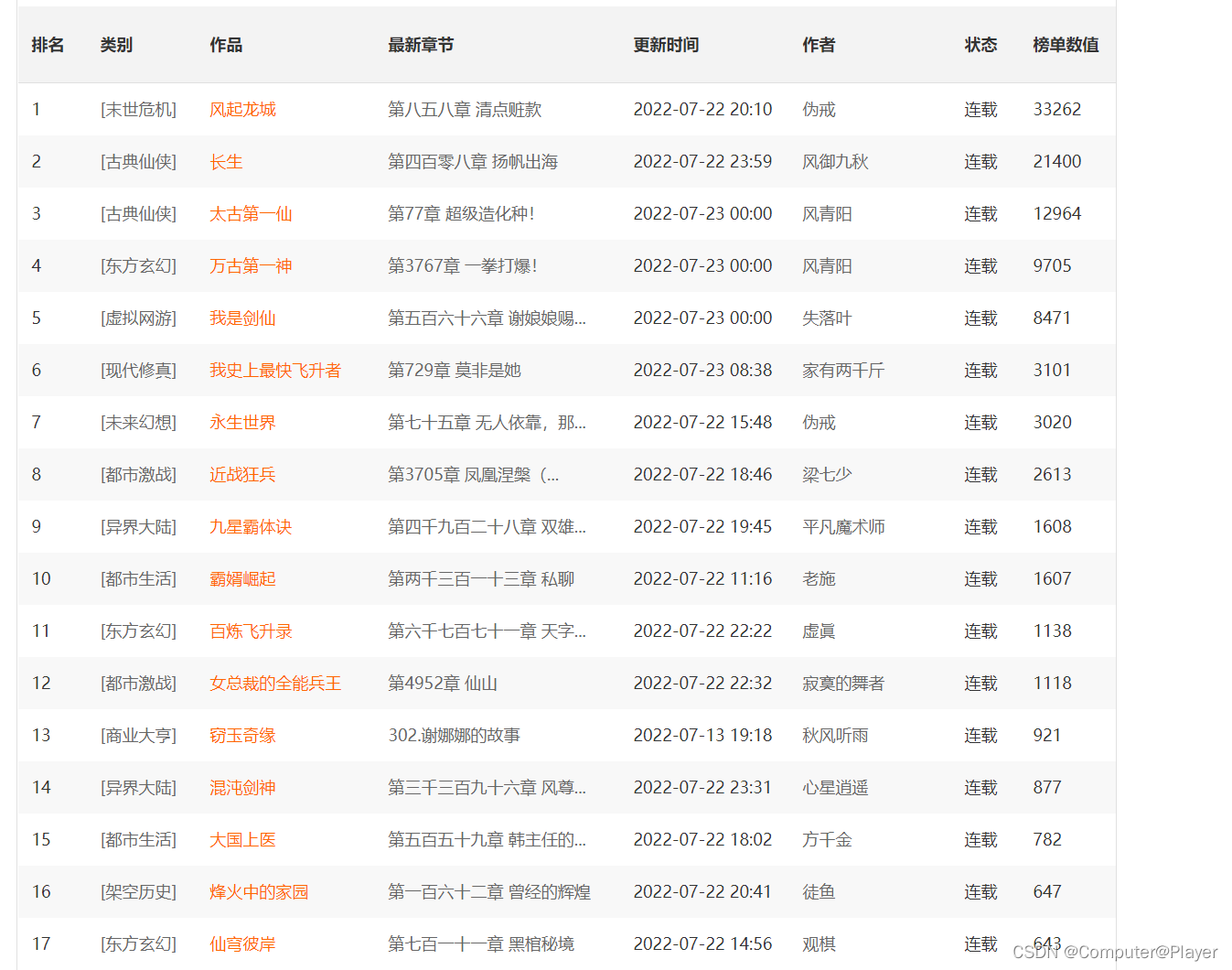 第一步设置ip代理,设置浏览器伪装,并且读取到html数据: 第一步设置ip代理,设置浏览器伪装,并且读取到html数据:
url = 'https://www.17k.com/top/refactor/top100/14_recommend/14_recommend_top_100_pc.html'
# 定义变量:URL 与 headers
headers = {'User-Agent': str(UserAgent().random)}
# 根据访问的网址为https选用“https”,选http用“http”
# proxies = {'协议': '协议://IP:端口号'}
ips = {"https": "https://58.20.232.245:9091"}
ip = {"http": "http://58.20.232.245:9091"}
get = requests.get(url, proxies=ip, headers=headers)
get.encoding = 'UTF-8'
我使用BeautifulSoup对网页的信息进行提取:
soup = BeautifulSoup(get.text, 'lxml')
div = soup.find(name='div', attrs={'class': "TYPE"})
a = div.find_all(name='a')
for i in a:
print(i.string)
 将对应的书名,作者,最新章节,类型分别保存到对于列表并且装入pd.DataFrame中: 将对应的书名,作者,最新章节,类型分别保存到对于列表并且装入pd.DataFrame中:
table = list()
for i in a:
table.append(i.string)
table0 = table[0::4]
for i in range(0, len(table0)):
table0[i] = table0[i].replace('[', '').replace(']', '')
table1 = table[1::4]
table2 = table[2::4]
table3 = table[3::4]
table_save = pd.DataFrame({
'书名':table1,
'作者':table3,
'类型':table0,
'最新章节':table2
})
print(table_save)
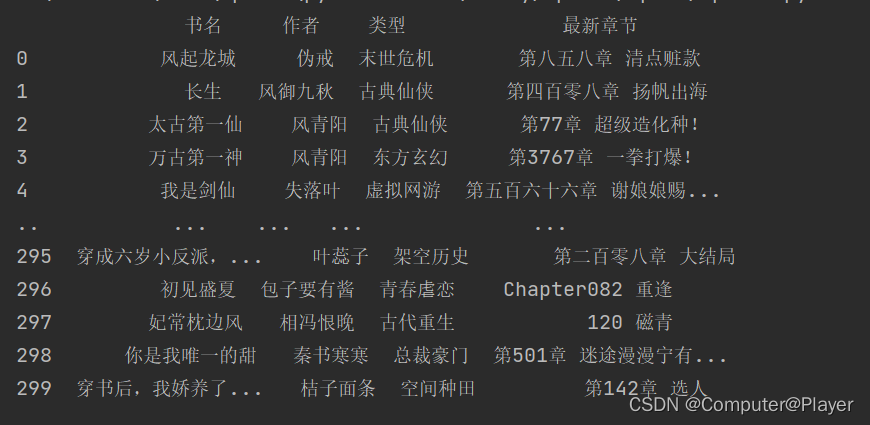 最后一部分继续保存,使用的是pandas中的.to_csv和.to_excel 最后一部分继续保存,使用的是pandas中的.to_csv和.to_excel
table_save.to_csv('排行榜.csv',index=None)
table_save.to_excel('排行榜.xlsx',index=None)
print('ok')
看一下保存的信息:  最终代码如下: 最终代码如下:
import requests
from fake_useragent import UserAgent
from lxml import html
import pandas as pd
etree = html.etree
from bs4 import BeautifulSoup
url = 'https://www.17k.com/top/refactor/top100/14_recommend/14_recommend_top_100_pc.html'
# 定义变量:URL 与 headers
headers = {'User-Agent': str(UserAgent().random)}
# 根据访问的网址为https选用“https”,选http用“http”
# proxies = {'协议': '协议://IP:端口号'}
ips = {"https": "https://58.20.232.245:9091"}
ip = {"http": "http://58.20.232.245:9091"}
get = requests.get(url, proxies=ip, headers=headers)
get.encoding = 'UTF-8'
soup = BeautifulSoup(get.text, 'lxml')
div = soup.find(name='div', attrs={'class': "TYPE"})
a = div.find_all(name='a')
table = list()
for i in a:
table.append(i.string)
table0 = table[0::4]
for i in range(0, len(table0)):
table0[i] = table0[i].replace('[', '').replace(']', '')
table1 = table[1::4]
table2 = table[2::4]
table3 = table[3::4]
table_save = pd.DataFrame({
'书名':table1,
'作者':table3,
'类型':table0,
'最新章节':table2
})
table_save.to_csv('排行榜.csv',index=None)
table_save.to_excel('排行榜.xlsx',index=None)
print('ok')
|