| PaddleOCR本地部署(安装,使用,模型优化/加速) | 您所在的位置:网站首页 › paddle训练很慢 › PaddleOCR本地部署(安装,使用,模型优化/加速) |
PaddleOCR本地部署(安装,使用,模型优化/加速)
|
文章目录
1. 安装1.1 还是需要paddle1.2 确认各种包和环境1.3 可能不需要paddle?
2. 使用2.1 配置摄像头,读取,识别,显示2.3 检测模型的问题2.3.1 换个模型2.3.2 限定检测位置
3. 性能改进3.0 基本情况X 自己模型的速度和全用默认的速度对比3.1 端侧部署3.2 加速3.2.1 CPU下使用mkldnn加速3.2.2 修改参数3.2.3 内存泄露3.2.4 内存泄漏的问题记录
3.3 剪枝3.4 其他可能的途径3.3 更换模型3.4 多进程
3.5 cpu占用问题3.5.1 paddle绑定cpu问题
3.6 推理部署文档
1. 安装
1.1 还是需要paddle
根据:paddleocr package使用说明 一开始以为: pip install "paddleocr>=2.0.1"但是果然: 安装好再去运行,遇到经典的shapely错误,参考:Win10 CPU环境,OSError: [WinError 126] 找不到指定的模块 #212 或者 更名为Shapely-1.7.0-cp39-cp39-win_amd64.rar,然后解压缩,从其子目录shapely\DLLs\中找到geos_c.dll,并将geos_c.dll拷贝到conda的环境(我的命名是ocr)目录 C:\Users\myusername\Miniconda3\envs\ocr\Library\bin中。问题解决 同时把geos.dll和geos_c.dll拷贝至你anaconda环境中的library\bin中 最简单的方案!!! 删除anaconda中之前装的shaply(文件夹和程序都删掉),重新安装, 参考:anaconda3+ paddleOCR安装使用 1.2 确认各种包和环境本机上,使用了anaconda默认环境,各种版本如下: python 3.7.6paddleocr 使用pip安装后看到的版本是: paddleocr-2.0.6-py3requirments文件中的内容: shapely scikit-image == 0.17.2 imgaug == 0.4.0 pyclipper lmdb opencv-python == 4.2.0.32 tqdm numpys visualdl python-Levenshtein 1.3 可能不需要paddle?根据paddleocr的FAQ文档 Q3.4.23:安装paddleocr后,提示没有paddle A:这是因为paddlepaddle gpu版本和cpu版本的名称不一致,现在已经在whl的文档里做了安装说明。 但是参考:预测示例 (Python) 可知,想使用paddle系列的模型,是必须要使用paddle的inference的。 所以还是老老实实安装上paddle吧 2. 使用改改路径就好了。 其中有一点需要注意: [[[[72.0, 149.0], [113.0, 151.0], [113.0, 166.0], [72.0, 163.0]], ('40', 0.7172388)], [[[62.0, 170.0], [237.0, 175.0], [233.0, 300.0], [58.0, 294.0]], ('1076', 0.9666834)]]可以看到输出文件的结构,每一个文本识别结果,都包括四个点的坐标,一个二位数组,以及一个最后识别结果的元组(识别的文字结果,置信度),结构就是一个数组涵盖这两部分内容。 如果是多个文本识别结果,会有再外层的一个数组。 2.1 配置摄像头,读取,识别,显示参考另一个文章:python opencv调用摄像头识别并绘制结果 发现一个神奇的事情,当你插着usb摄像头启动电脑时,cap = cv2.VideoCapture(0),usb摄像头的序号就是0;当启动电脑之后再插上usb摄像头,usb摄像头的序号就是2(我的电脑是一个前置+一个后置摄像头) 关于摄像头参数的调节,可以参考另一篇文章:Opencv摄像头相关参数 2.3 检测模型的问题由于使用了摄像头读取图像,图片背景比较杂,对检测有难度,发现使用DB效果不是很好。(由于还没怎么研究过检测模型,所以很难判断问题到底出在哪里) 2.3.1 换个模型参考: paddleocr文档 EAST高效,准确,但对弯曲文本检测较差。 在paddleocr.py文件中看到: parser.add_argument("--det_algorithm", type=str, default='DB') # 调用时修改为EAST,但是报错
结论: 发现下载的是预训练模型,不是推理模型,无法使用EAST算法。 2.3.2 限定检测位置设置一个按键,opencv摄像头有键盘响应,可以有相应的操作,参考:cv2.VideoCapture.get、set详解可以获取相机参数。 另外,参考:opencv python全屏显示、置窗口大小和位置 cap=cv2.VideoCapture(1) cv2.VideoCapture.get(3) # CV_CAP_PROP_FRAME_WIDTH 在视频流的帧的宽度 cv2.VideoCapture.get(4) # CV_CAP_PROP_FRAME_HEIGHT 在视频流的帧的高度 # 除了get,还有set capture.set(CV_CAP_PROP_FRAME_WIDTH, 1080); 宽度 capture.set(CV_CAP_PROP_FRAME_HEIGHT, 960); 高度 frame[top:bottom,left:right]参考:python cv2图片剪裁 3. 性能改进 3.0 基本情况
先查看一下模型的size,运行检测的时候会打印出模型的配置信息,可以从这里看到 Namespace(cls_batch_num=6, cls_image_shape='3, 48, 192', cls_model_dir='C:\\Users\\huangshan/.paddleocr/2.1/cls', cls_thresh=0.9, det=True, det_algorithm='DB', det_db_box_thresh=0.3, det_db_thresh=0.2, det_db_unclip_ratio=2.2, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_east_score_thresh=0.8, det_limit_side_len=960, det_limit_type='max', det_model_dir='C:\\Users\\huangshan/.paddleocr/2.1/det/ch', drop_score=0.5, enable_mkldnn=False, gpu_mem=8000, image_dir='', ir_optim=True, label_list=['0', '180'], lang='ch', max_text_length=25, rec=True, rec_algorithm='CRNN', rec_batch_num=6, rec_char_dict_path='C:/shaiic_work/ZhiNengKeJiOCR/digit.txt', rec_char_type='ch', rec_image_shape='3, 32, 320', rec_model_dir='C:/shaiic_work/ZhiNengKeJiOCR/rec_crnn_digit', use_angle_cls=False, use_dilation=False, use_gpu=False, use_pdserving=False, use_space_char=True, use_tensorrt=False, use_zero_copy_run=False)采用的检测模型是自带的,位置在:det_model_dir='C:\\Users\\yourname/.paddleocr/2.1/det/ch',检测模型只有3M ch_ppocr_mobile_v2.0_rec_infer.tar所以这个默认的模型目测已经是剪枝过的了。 同时,参考:PP-OCR 2.0系列模型列表文档 识别模型是自己训练之后转为推理模型的,有94MB,确实对于比较简单的一块数字仪表识别很重。 X 自己模型的速度和全用默认的速度对比上面已经给了几个自己模型的用时图,下面给几个全用默认的时间图 可知: 不使用mkldnn加速的情况下,使用默认的检测+自己的识别速度基本在0.7~1.2s 不使用mkldnn加速的情况下,使用默认的检测+默认的识别速度基本在0.7~0.9s 所以虽然识别时间本来就不到0.2s,但是可以变得更快,这样就只剩检测时间了。 个人猜测,是不是第一阶段检测模型是剪枝后的,比如是8位精度,第二阶段识别模型也是8位精度,这样系统处理是一致的。 如果两个阶段数据精度不一样,系统处理的时候不一致,是不是也会造成数据差异。 3.1 端侧部署参考文档:端侧部署 这种会帮助有效减小模型size,但是推理速度似乎没有强调会不会变快。 3.2 加速直接去FAQ文档中搜索加速,可以看到以下结果. Q3.1.73: 如何使用TensorRT加速PaddleOCR预测? A: 目前paddle的dygraph分支已经支持了python和C++ TensorRT预测的代码,python端inference预测时把参数–use_tensorrt=True即可, C++TensorRT预测需要使用支持TRT的预测库并在编译时打开-DWITH_TENSORRT=ON。 如果想修改其他分支代码支持TensorRT预测,可以参考PR。 注:建议使用TensorRT大于等于6.1.0.5以上的版本。 另外,搜索速度,可以看到: Q3.4.40: 使用hub_serving部署,延时较高,可能的原因是什么呀? A: 首先,测试的时候第一张图延时较高,可以多测试几张然后观察后几张图的速度;其次,如果是在cpu端部署serving端模型(如backbone为ResNet34),耗时较慢,建议在cpu端部署mobile(如backbone为MobileNetV3)模型。 这里建议在cpu端部署mobile模型 也可以只看预测部署部分,还可以看到以下比较有用的信息: Q3.4.1:如何pip安装opt模型转换工具? A:由于OCR端侧部署需要某些算子的支持,这些算子仅在Paddle-Lite 最新develop分支中,所以需要自己编译opt模型转换工具。opt工具可以通过编译PaddleLite获得,编译步骤参考lite部署文档 中2.1 模型优化部分。 🍱Q3.4.2:如何将PaddleOCR预测模型封装成SDK A:如果是Python的话,可以使用tools/infer/predict_system.py中的TextSystem进行sdk封装,如果是c++的话,可以使用deploy/cpp_infer/src下面的DBDetector和CRNNRecognizer完成封装 3.2.1 CPU下使用mkldnn加速由于慢的地方主要是检测,所以即便对剪枝进行优化也不是很有效,所以这里先尝试使用mkldnn来进行加速。 Q3.1.77: 使用mkldnn加速预测时遇到 ‘Please compile with MKLDNN first to use MKLDNN’ A: 报错提示当前环境没有mkldnn,建议检查下当前CPU是否支持mlkdnn(MAC上是无法用mkldnn);另外的可能是使用的预测库不支持mkldnn, 建议从这里下载支持mlkdnn的CPU预测库。 Q1.1.10:PaddleOCR中,对于模型预测加速,CPU加速的途径有哪些?基于TenorRT加速GPU对输入有什么要求? A:(1)CPU可以使用mkldnn进行加速;对于python inference的话,可以把enable_mkldnn改为true,参考代码,对于cpp inference的话,在配置文件里面配置use_mkldnn 1即可,参考代码 (2)GPU需要注意变长输入问题等,TRT6 之后才支持变长输入 直接在inference代码中将enable_mkldnn改为true,确实变快了一些。 想起来还有一些参数可以考虑修改,比如: parser.add_argument("--det_limit_side_len", type=float, default=960)根据FAQ文档 Q3.3.2:配置文件里面检测的阈值设置么? A:有的,检测相关的参数主要有以下几个: det_limit_side_len:预测时图像resize的长边尺寸 det_db_thresh: 用于二值化输出图的阈值 det_db_box_thresh:用于过滤文本框的阈值,低于此阈值的文本框不要 det_db_unclip_ratio: 文本框扩张的系数,关系到文本框的大小 这些参数的默认值见代码,可以通过从命令行传递参数进行修改。 det_limit_side_len默认是960,考虑改成32的倍数,但是改小一些,比如320。 另外,关于常见PaddleOCR包里给出的参数说明,参考:paddleocr package使用说明最后有一个参数说明表: 根据FAQ文档, Q3.4.43: 预测时显存爆炸、内存泄漏问题? A: 打开显存/内存优化开关enable_memory_optim可以解决该问题,相关代码已合入,查看详情。 可以看到这个代码的位置: https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/tools/infer/utility.py#L153 Q3.4.17: 预测内存泄漏问题 A:1. 使用hubserving出现内存泄漏,该问题为已知问题,预计在paddle2.0正式版中解决。相关讨论见issue A:2. C++ 预测出现内存泄漏,该问题已经在paddle2.0rc版本中解决,建议安装paddle2.0rc版本,并更新PaddleOCR代码到最新。 2021.6.3查看那个issue看到:
最后的结论 内存泄漏是因为开启了mkldnn,需要关闭。 同时cpu thread数量改为1,不然还是会有很高的内存占用率,同时改成1,其实速度影响并不大。 3.2.4 内存泄漏的问题记录发现paddle的issue中有很多说速度很慢的: 使用CPU下进行加速处理,但是识别的速度将近30S,请问有什么方法提高嘛? #2950 这个用的是服务器端的模型,看到了server 关于半自动标注工具PPOCRLabel运行速度由快逐渐变慢的问题 #1391 类似的也有:PPOCRLabel自动标注跑着跑着就自己闪退了 #2724 有说版本变慢的:2.x版本比1.x版本慢2倍 #2630 还有识别时内存一直涨 溢出 #303 在上面下载支持mlkdnn的CPU预测库的时候,看到了一个很有用的说明文档:https://paddle-inference.readthedocs.io/en/latest/index.html,就是针对paddle系列的推理模型的。 模型量化(主要就是剪枝)——X86 CPU 上部署量化模型 大概介绍一下,搬运 众所周知,模型量化可以有效加快模型预测性能,飞桨也提供了强大的模型量化功能。所以,本文主要介绍在X86 CPU部署PaddleSlim产出的量化模型。 对于常见图像分类模型,在Casecade Lake机器上(例如Intel® Xeon® Gold 6271、6248,X2XX等),INT8模型进行推理的速度通常是FP32模型的3-3.7倍;在SkyLake机器上(例如Intel® Xeon® Gold 6148、8180,X1XX等),INT8模型进行推理的速度通常是FP32模型的1.5倍。 X86 CPU部署量化模型的步骤: 产出量化模型:使用PaddleSlim训练并产出量化模型 转换量化模型:将量化模型转换成最终部署的量化模型 部署量化模型:使用Paddle Inference预测库部署量化模型 一开始其实不太想用剪枝的,因为慢的原因主要在于检测,但是检测的模型已经是剪枝后的了,在比较过全都使用默认的剪枝模型(检测+识别),和使用默认的检测+自己的识别模型之后,发现其实还是有些效果的。 但是相比于剪枝的代价,并不值得。 3.4 其他可能的途径 3.3 更换模型https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/doc/doc_ch/models_list.md FAQ-如何多进程运行paddleocr? Q3.4.33: 如何多进程运行paddleocr? A:实例化多个paddleocr服务,然后将服务注册到注册中心,之后通过注册中心统一调度即可,关于注册中心,可以搜索eureka了解一下具体使用,其他的注册中心也行。 Q3.4.44: 如何多进程预测 A: 近期PaddleOCR新增了多进程预测控制参数,use_mp表示是否使用多进程,total_process_num表示在使用多进程时的进程数。具体使用方式请参考文档。 parser.add_argument("--use_mp", type=str2bool, default=False) # 只能命令行调用 # 使用方向分类器 python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/det_db/" --cls_model_dir="./inference/cls/" --rec_model_dir="./inference/rec_crnn/" --use_angle_cls=true # 不使用方向分类器 python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/det_db/" --rec_model_dir="./inference/rec_crnn/" --use_angle_cls=false # 使用多进程 python3 tools/infer/predict_system.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/det_db/" --rec_model_dir="./inference/rec_crnn/" --use_angle_cls=false --use_mp=True --total_process_num=6
之前又说内存泄漏,还有个问题就是CPU抢占,默认会占到100%。 很多人也有这样的问题,比如:百度AI社区-ppocr部分 查看自己电脑核数 win10系统如何查看cpu核数 3.6推理部署文档里涉及了一点点,主要是: Docs » Python API 文档 » Config 类 » 3. 使用 CPU 进行预测 后来想到PaddleOCR的代码中有: 其实utility.py文件中,有一段代码,找到自己本机安装paddleocr的地方,C:\software\anaconda\Lib\site-packages\paddleocr\tools\infer,133行左右 if args.use_gpu: config.enable_use_gpu(args.gpu_mem, 0) if args.use_tensorrt: config.enable_tensorrt_engine( precision_mode=inference.PrecisionType.Half if args.use_fp16 else inference.PrecisionType.Float32, max_batch_size=args.max_batch_size) else: config.disable_gpu() # cpu设置的关键 🧡 config.set_cpu_math_library_num_threads(6) if args.enable_mkldnn: # cache 10 different shapes for mkldnn to avoid memory leak # mkldnn设置的关键 🧡 config.set_mkldnn_cache_capacity(10) config.enable_mkldnn() # TODO LDOUBLEV: fix mkldnn bug when bach_size > 1 #config.set_mkldnn_op({'conv2d', 'depthwise_conv2d', 'pool2d', 'batch_norm'}) args.rec_batch_num = 1根据文档Docs » Python API 文档 » Config 类 » 3. 使用 CPU 进行预测说明, 在 CPU 可用核心数足够时,可以通过设置 set_cpu_math_library_num_threads 将线程数调高一些,默认线程数为 1 所以如果想要限制这个使用cpu的核数量,可以设置代码中 config.set_cpu_math_library_num_threads(6) # 把6改成4好了另外,由于启用了mkldnn,还是根据上面那个文档: 启用 MKLDNN 的前提为已经使用 CPU 进行预测,否则启用 MKLDNN 无法生效 启用 MKLDNN BF16 要求 CPU 型号可以支持 AVX512,否则无法启用 MKLDNN BF16 # 设置 MKLDNN 的 cache 容量大小 config.set_mkldnn_cache_capacity(1)最后将cpu个数从6变成4,mkldnn从10变成5,需要重启电脑才生效,使用reload函数重新加载库似乎没什么用,关掉pycharm重新启动pycharm也没啥用。 但是检测速度又降低了。 而且重启电脑之后,第一次是控制在了50%左右,但是第二次再去进行的时候就不行了。 这是因为 python 把ppocr这个库缓存了,需要把它从 sys.modules 里删了再导入即可。 参考另一个博文:python3 reload 3.6 推理部署文档paddle有很多关于推理部署的专门的文档,其实可以看看。 推理部署 另外,从官网这里可以切到文档:Python预测部署示例 |
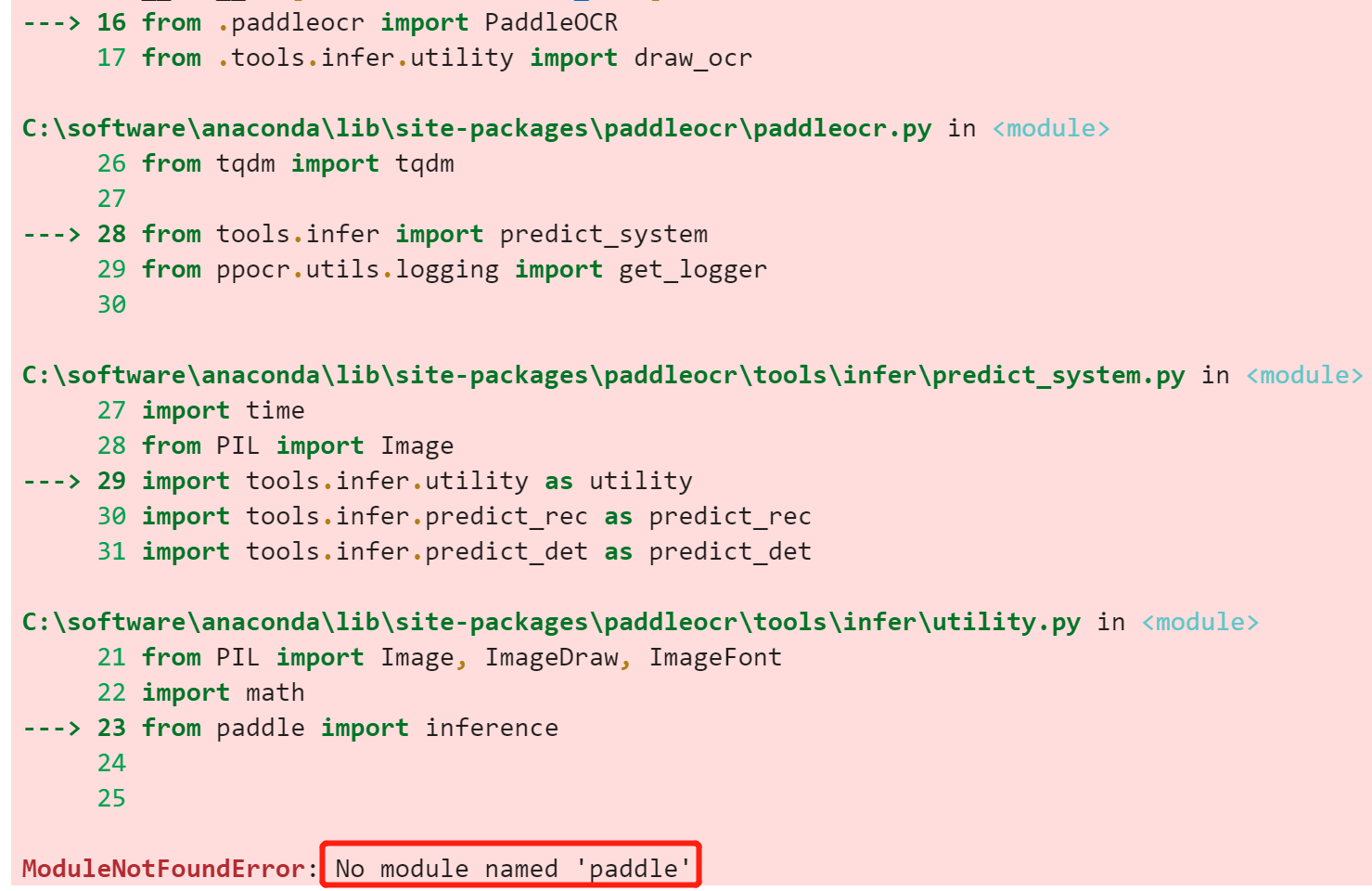 so就在本机安装一下paddle好了,但是也仅需要paddle,参考:快速安装
so就在本机安装一下paddle好了,但是也仅需要paddle,参考:快速安装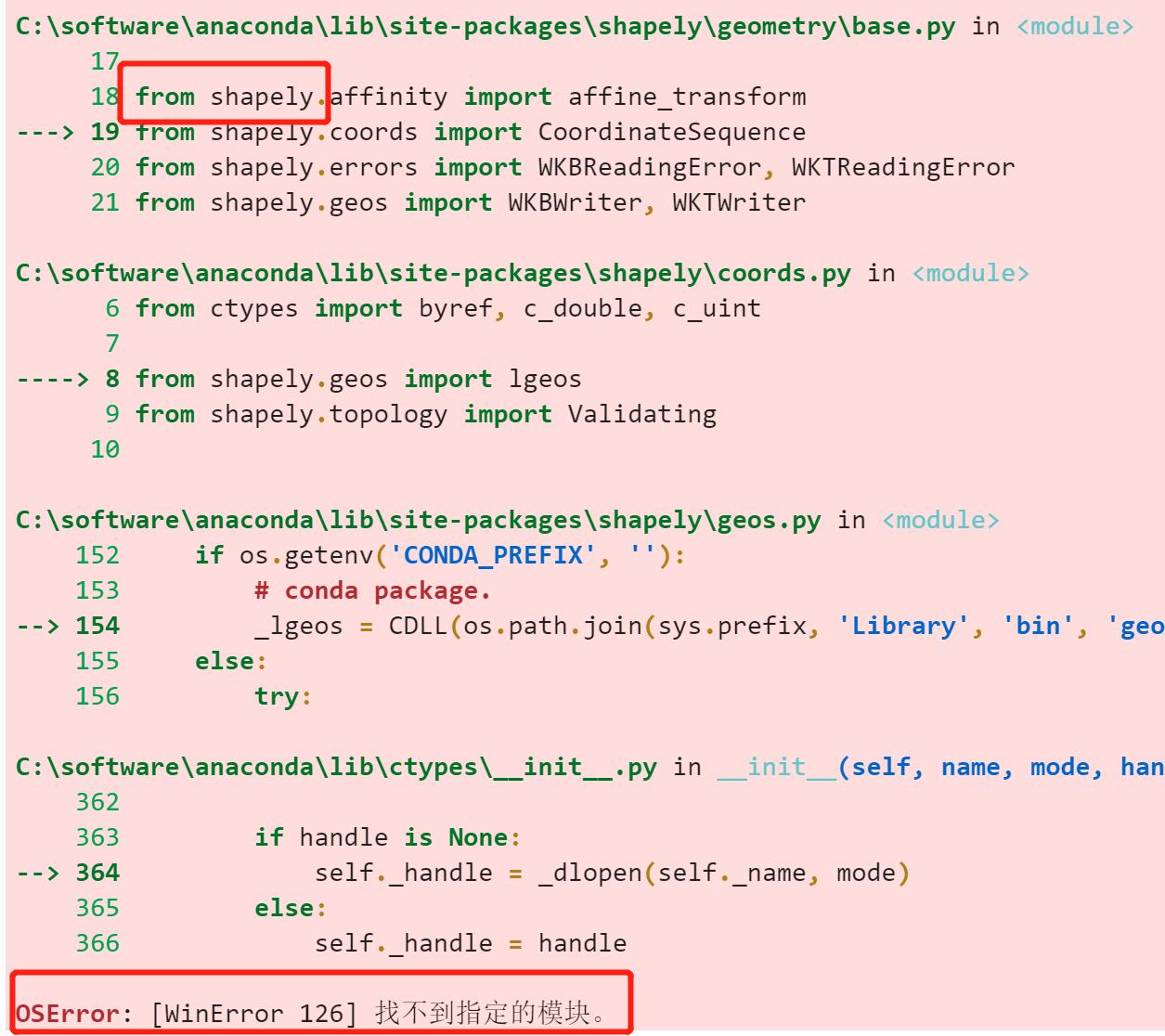 windows下安装shapely,需要从这里下载,然后再
windows下安装shapely,需要从这里下载,然后再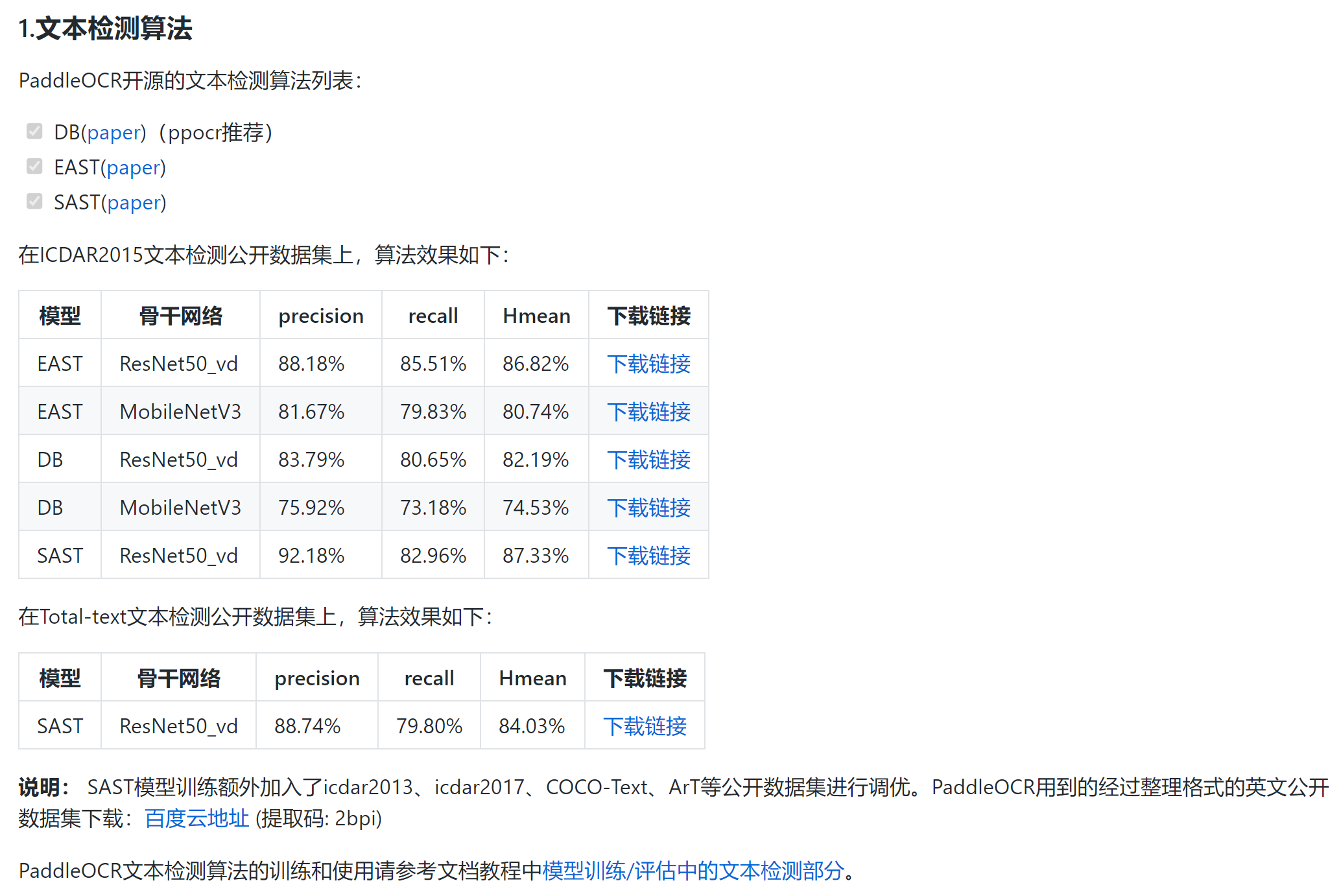 可以看到,其实EAST的准确率要比DB高,虽然存在过检。
可以看到,其实EAST的准确率要比DB高,虽然存在过检。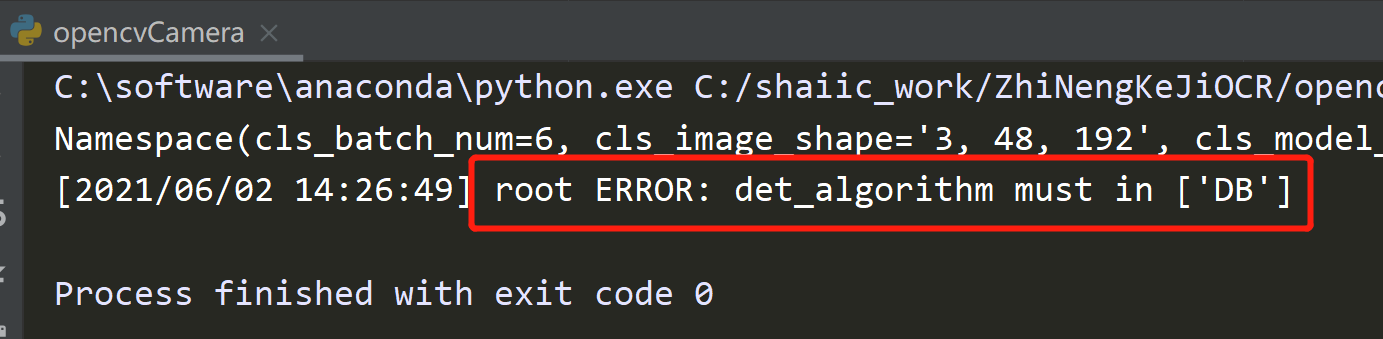 然后看到代码中有:
然后看到代码中有:

 检测时间比较久,检测+识别的时间差不多是0.7~1.2s,在cpu机器上,其实比较尴尬。
检测时间比较久,检测+识别的时间差不多是0.7~1.2s,在cpu机器上,其实比较尴尬。 先确认一下这个默认模型的信息,从代码中可以看到:
先确认一下这个默认模型的信息,从代码中可以看到: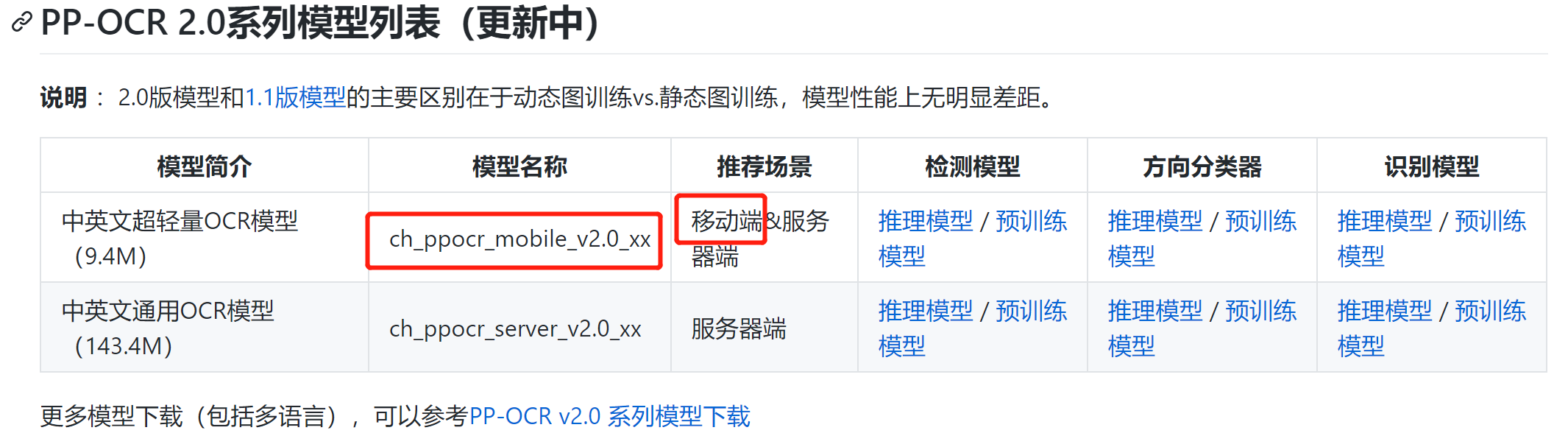








 之前是0.7~1.2,现在基本就是0.6-0.98,反正没有超过1s的,0.8的比较多。
之前是0.7~1.2,现在基本就是0.6-0.98,反正没有超过1s的,0.8的比较多。

 det_limit_side_len改的再小一些,256,识别部分最大长度max_text_length=5,rec_image_shape=(3,32,256),之前默认是(3,32,320)。 很奇怪,一开始速度是0.6,后来逐渐稳定再0.8~0.9之间。打开内存任务管理器发现,这个东西内存占用可以达到98%???? 我本机是32G的内存,无语。
det_limit_side_len改的再小一些,256,识别部分最大长度max_text_length=5,rec_image_shape=(3,32,256),之前默认是(3,32,320)。 很奇怪,一开始速度是0.6,后来逐渐稳定再0.8~0.9之间。打开内存任务管理器发现,这个东西内存占用可以达到98%???? 我本机是32G的内存,无语。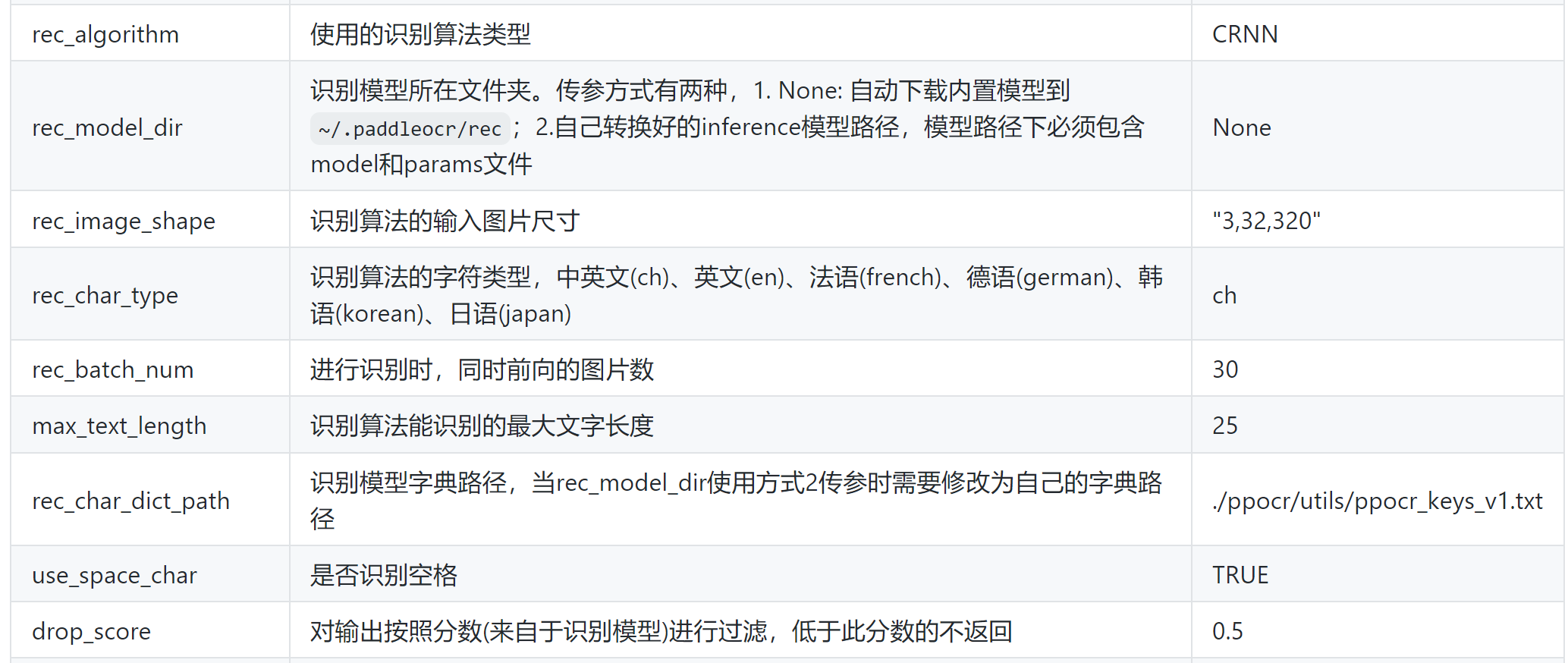 关于检测可控的参数有很多,但是关于识别,其实并没有很多可以进行调优的参数。
关于检测可控的参数有很多,但是关于识别,其实并没有很多可以进行调优的参数。 这个更新是26天前,查看自己的环境,似乎不是2.0rc,换。
这个更新是26天前,查看自己的环境,似乎不是2.0rc,换。  所以虽然找不到paddle2.0rc版本,但是可以直接去下载2.1版本,开始使用
所以虽然找不到paddle2.0rc版本,但是可以直接去下载2.1版本,开始使用 改了之后,内存依然占用量很高,而且推理速度还变慢了。。。。都超过1s了,但是效果好像好了一些,连一些虚的都变好了。换成自带的识别模型之后,也比之前时间长了,无语。 但是更新到2.1之后,打开mkldnn,速度变快了,基本控制在0.3-0.5s。。。但是内存占用是100%基本上。
改了之后,内存依然占用量很高,而且推理速度还变慢了。。。。都超过1s了,但是效果好像好了一些,连一些虚的都变好了。换成自带的识别模型之后,也比之前时间长了,无语。 但是更新到2.1之后,打开mkldnn,速度变快了,基本控制在0.3-0.5s。。。但是内存占用是100%基本上。 

 加速之后,超级快,但是内存占用非常高。
加速之后,超级快,但是内存占用非常高。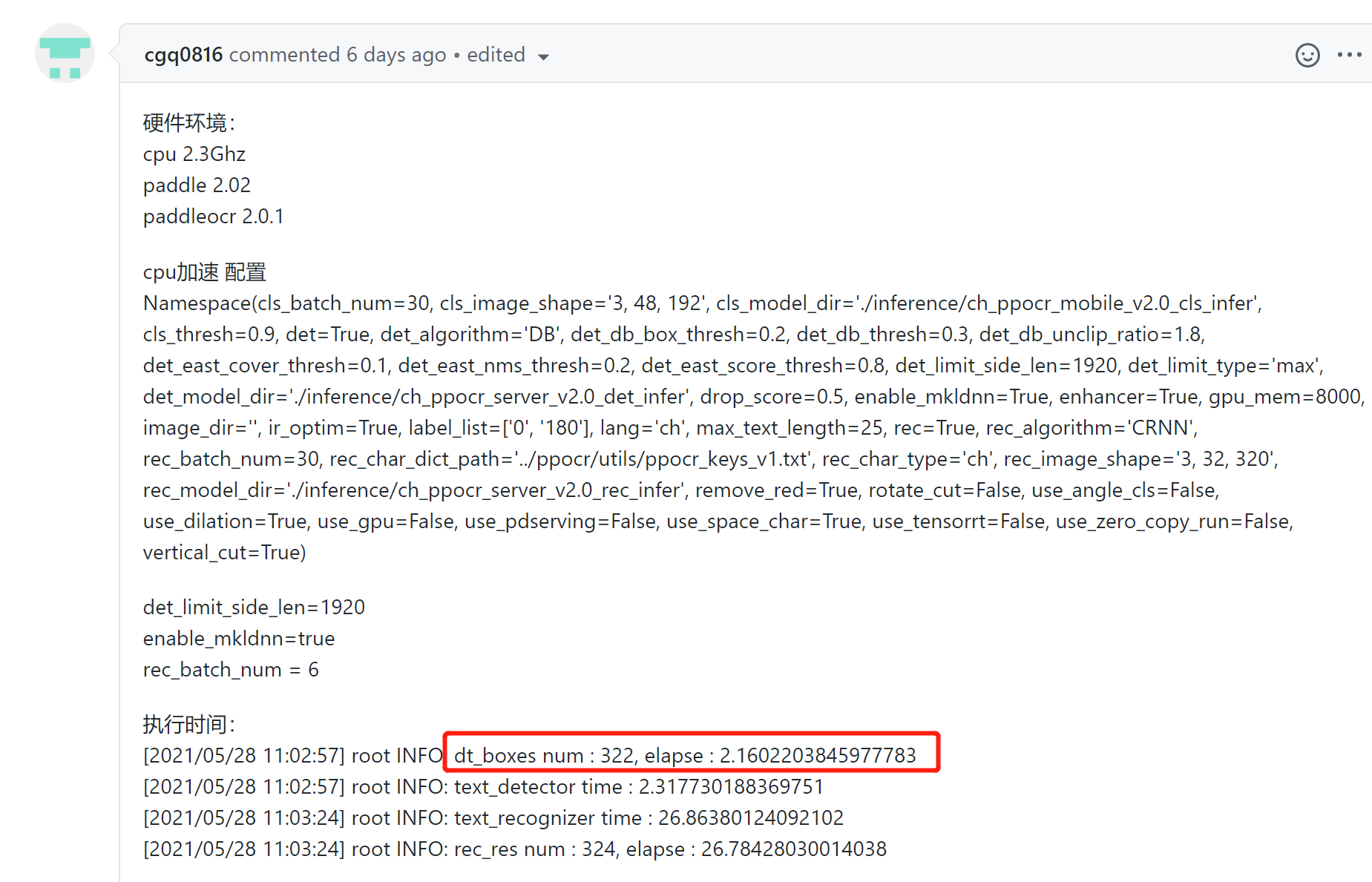 还有关于PPOCRLabel也是自动标记过程中由快到慢:
还有关于PPOCRLabel也是自动标记过程中由快到慢: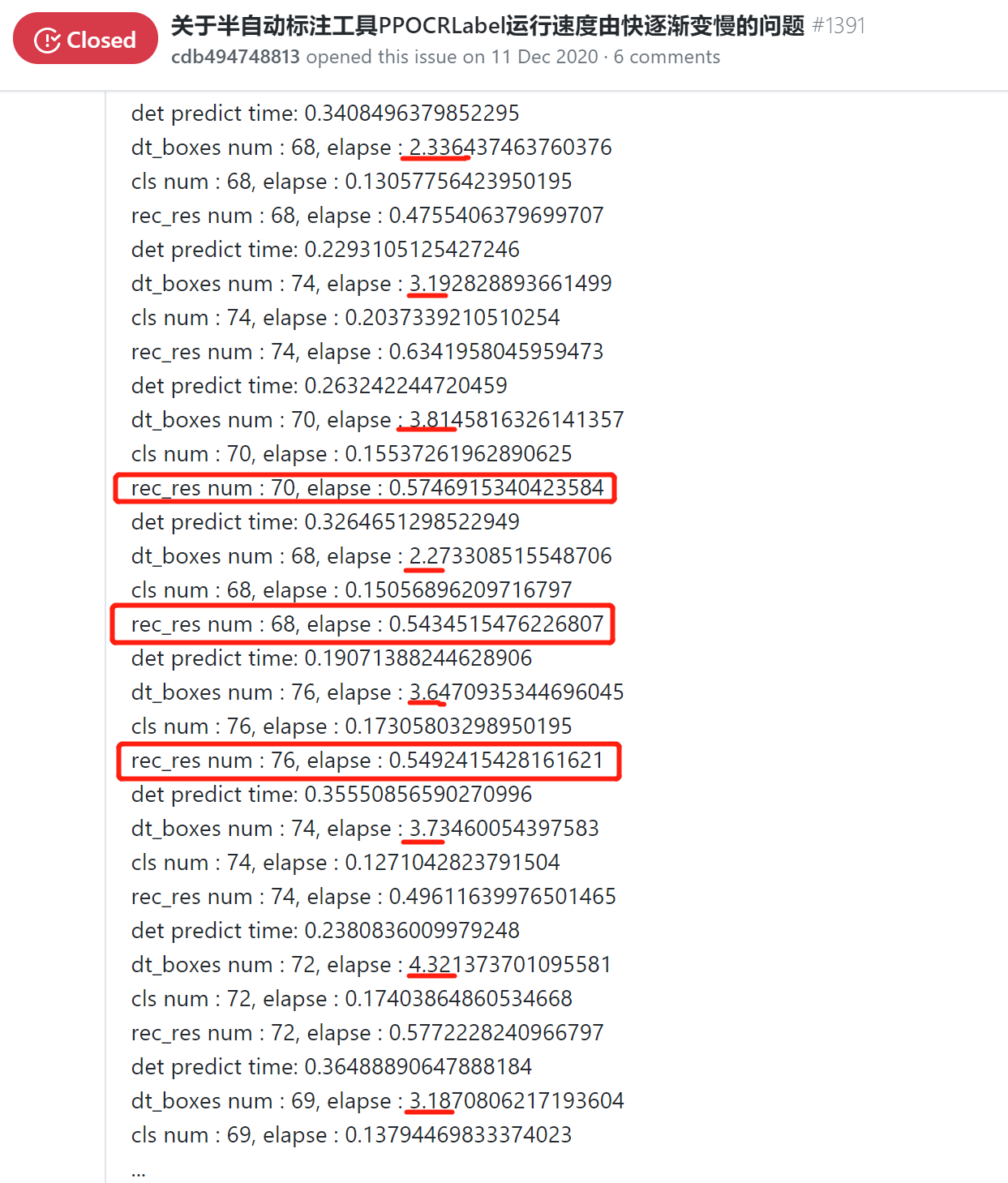
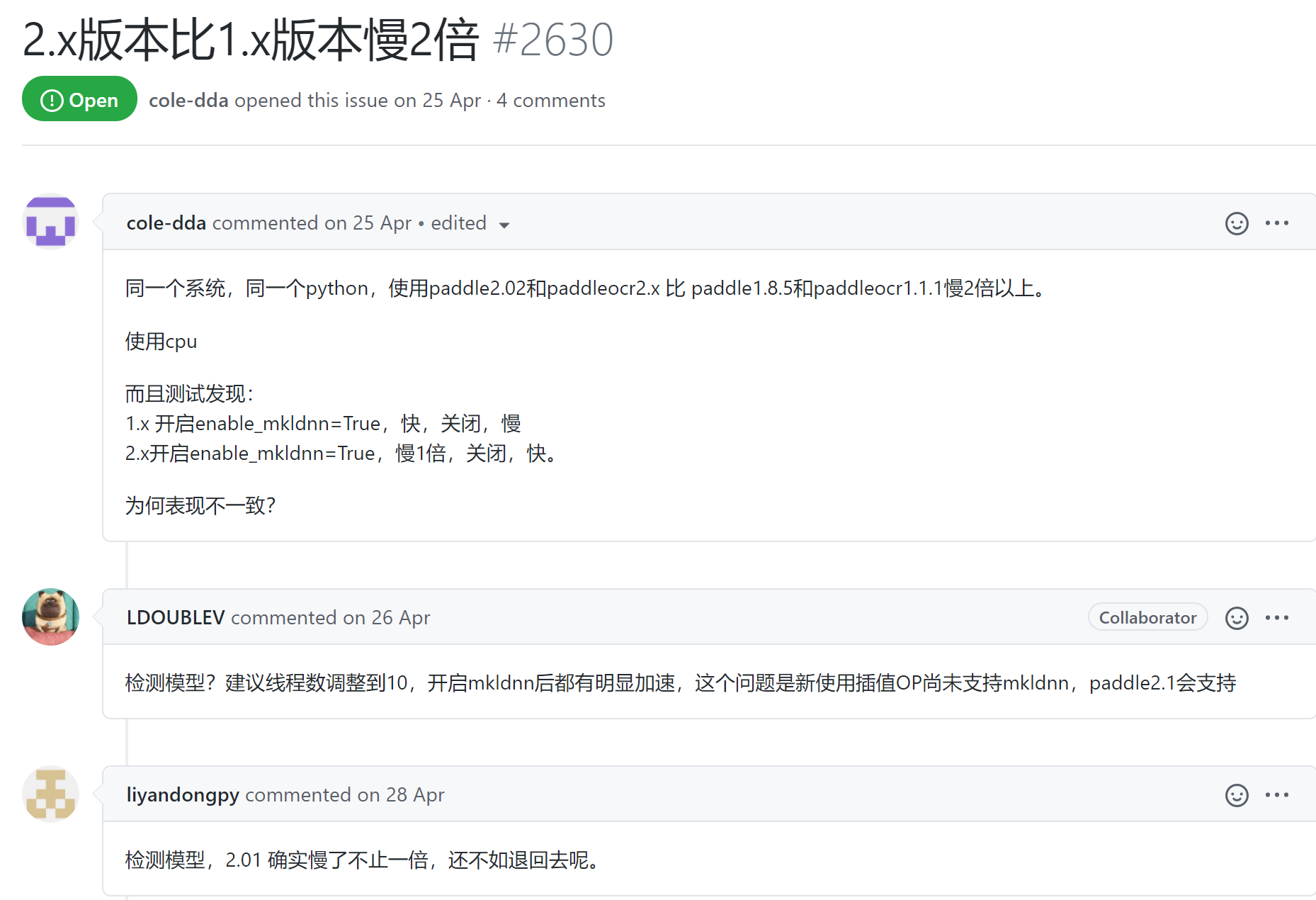
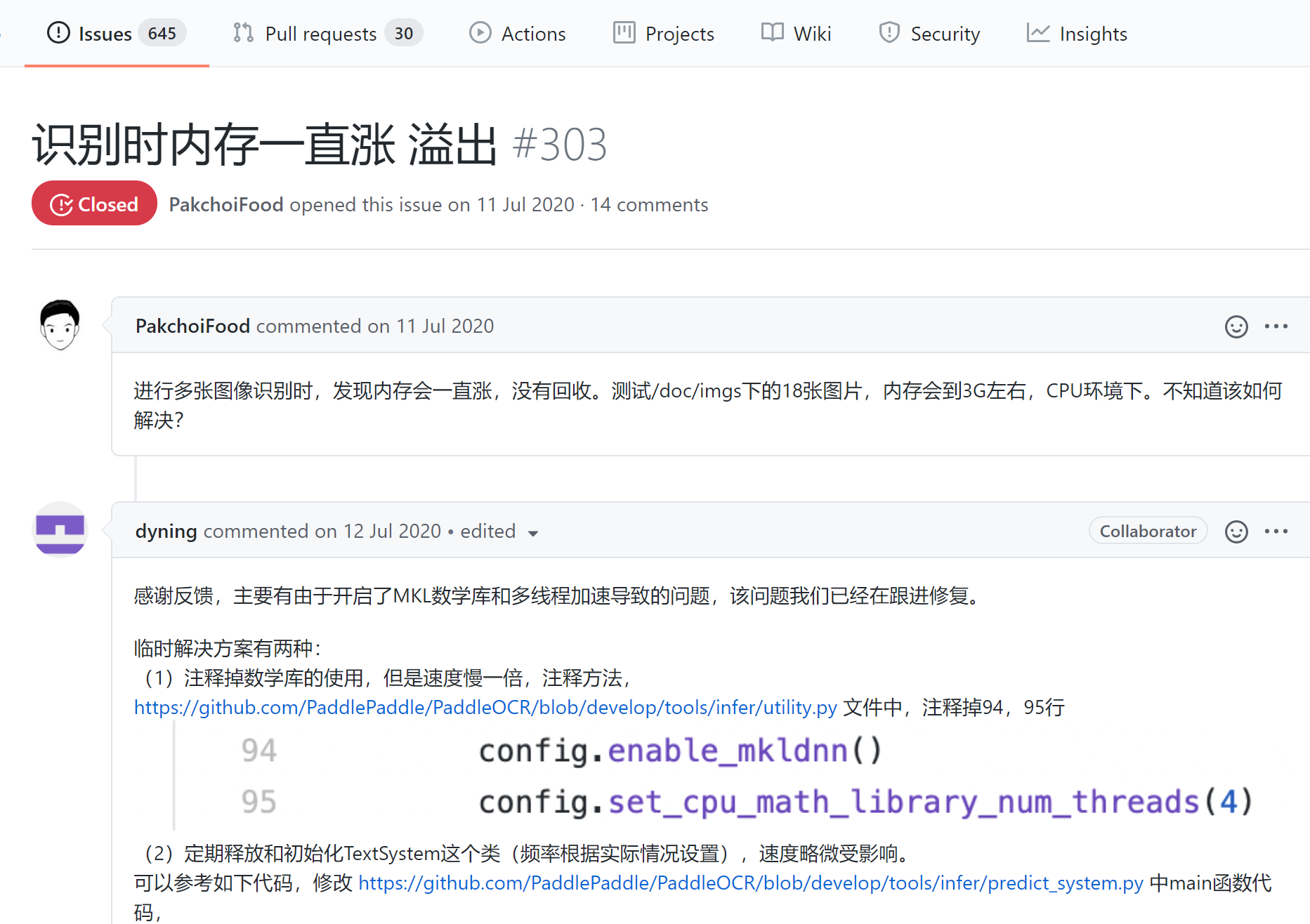 虽然这个issue关闭了,但是下面还是有人再报错。。。
虽然这个issue关闭了,但是下面还是有人再报错。。。 
 看了一下,其实这个文件https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/paddleocr.py 和另一个PaddleOCR/tools/infer/utility.py文件内容很像, wheel包里的那个paddleocr.py其实就是这个utility.py文件的一部分内容的简化,方便调用而已。
看了一下,其实这个文件https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/paddleocr.py 和另一个PaddleOCR/tools/infer/utility.py文件内容很像, wheel包里的那个paddleocr.py其实就是这个utility.py文件的一部分内容的简化,方便调用而已。 在FAQ文档中没有搜索到相关信息,移动端arm cpu优化学习笔记第3弹–绑定cpu(cpu affinity)
在FAQ文档中没有搜索到相关信息,移动端arm cpu优化学习笔记第3弹–绑定cpu(cpu affinity)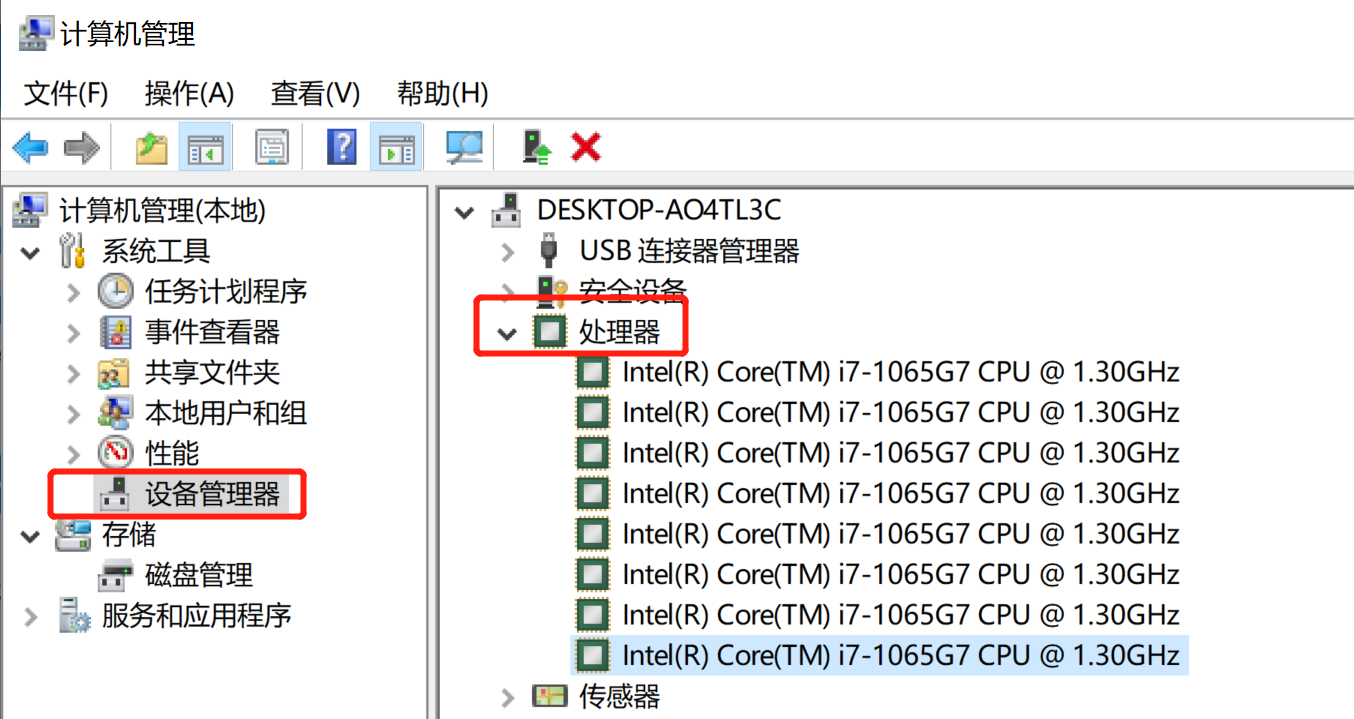 所以我这个电脑是8核。
所以我这个电脑是8核。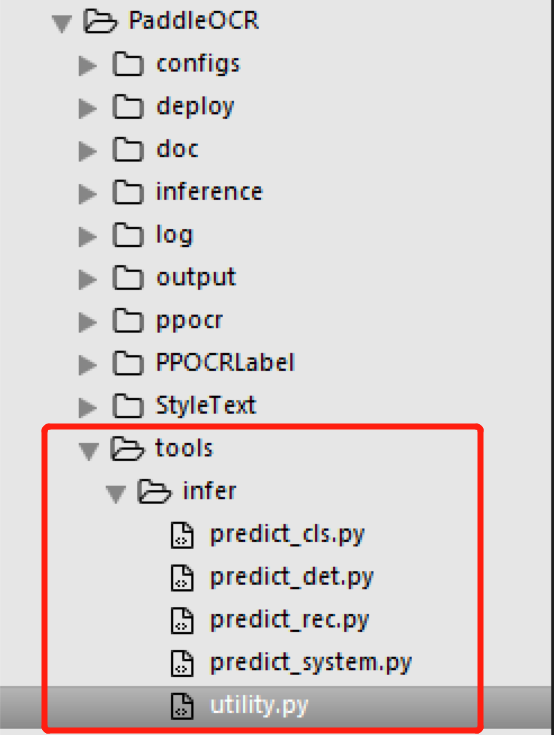 主要是这里的infer文件夹中的五个脚本文件,关键就是搞清楚utility.py中config文件配置的项目都是怎么搞的。 由于人工找太累了而且还没找到,所以直接在代码里调试来查看:把调用ocr的附近打个断点,然后看输出的变量,里面就有ocr对象(PaddleOCR类)
主要是这里的infer文件夹中的五个脚本文件,关键就是搞清楚utility.py中config文件配置的项目都是怎么搞的。 由于人工找太累了而且还没找到,所以直接在代码里调试来查看:把调用ocr的附近打个断点,然后看输出的变量,里面就有ocr对象(PaddleOCR类) 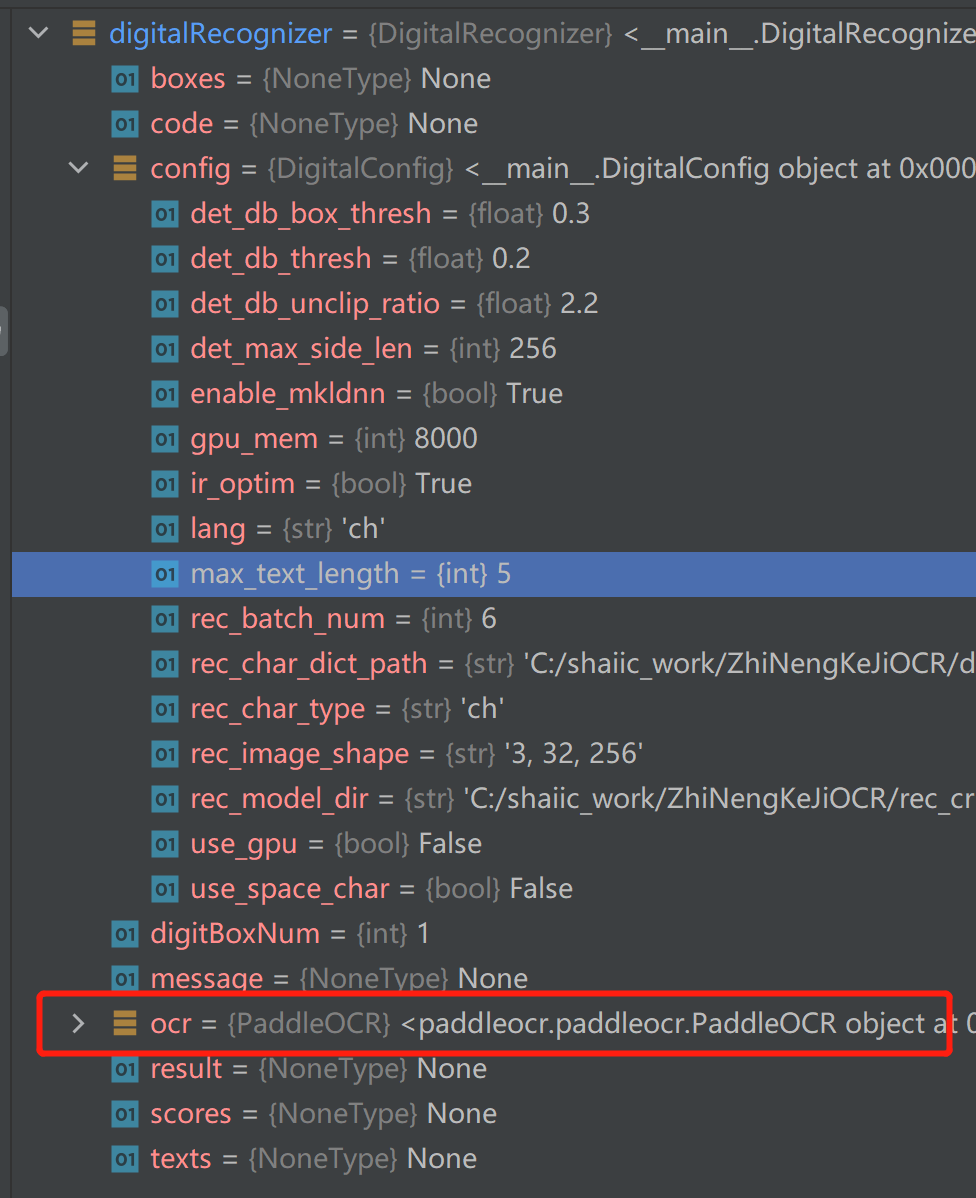 然后就可以看到,有一个文本检测和文本识别
然后就可以看到,有一个文本检测和文本识别  展开,可以看到大部分参数其实都是在文本检测那里配置的
展开,可以看到大部分参数其实都是在文本检测那里配置的 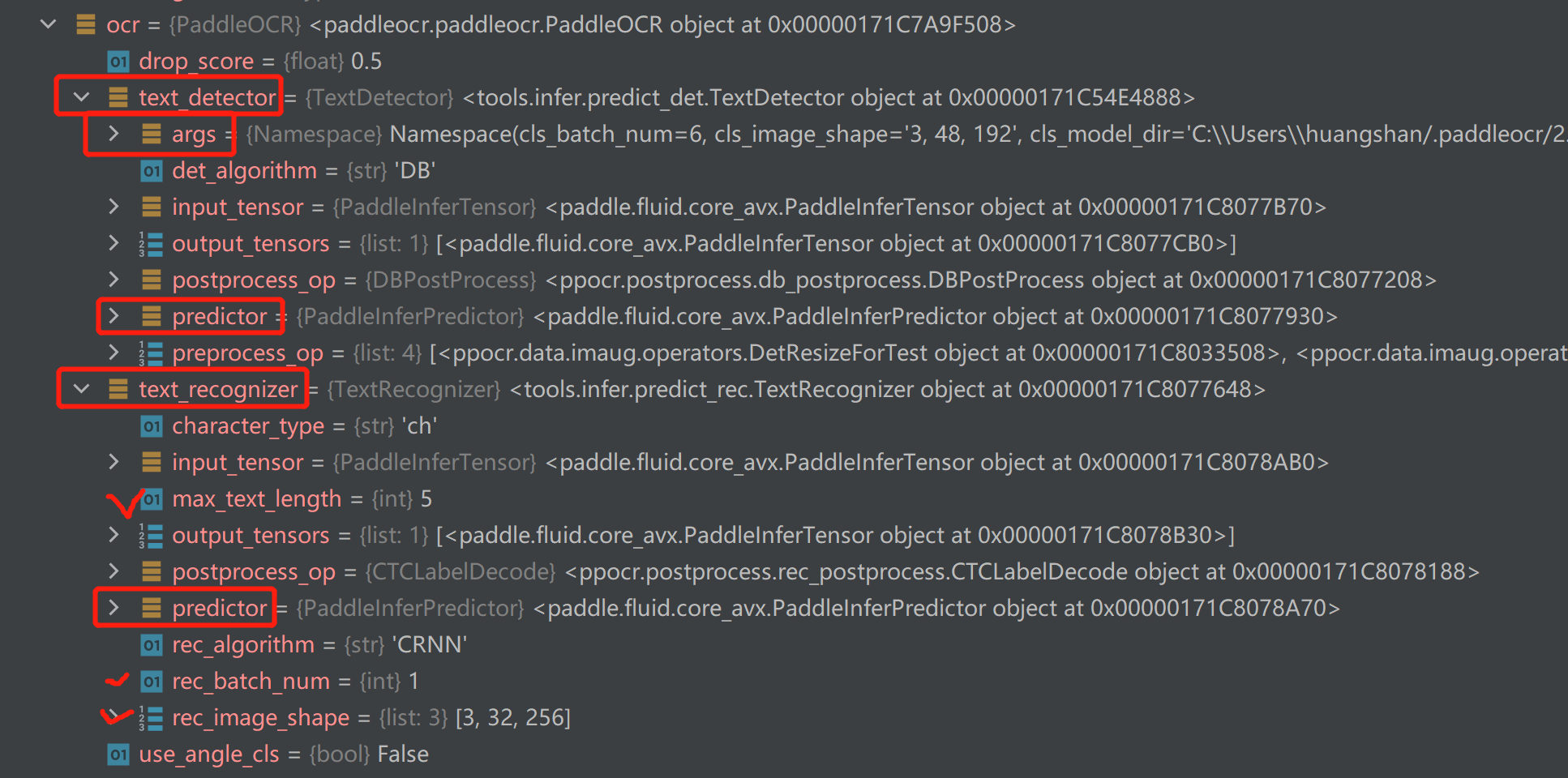 文本检测配置了很多东西,但是并没有cpu相关的配置。
文本检测配置了很多东西,但是并没有cpu相关的配置。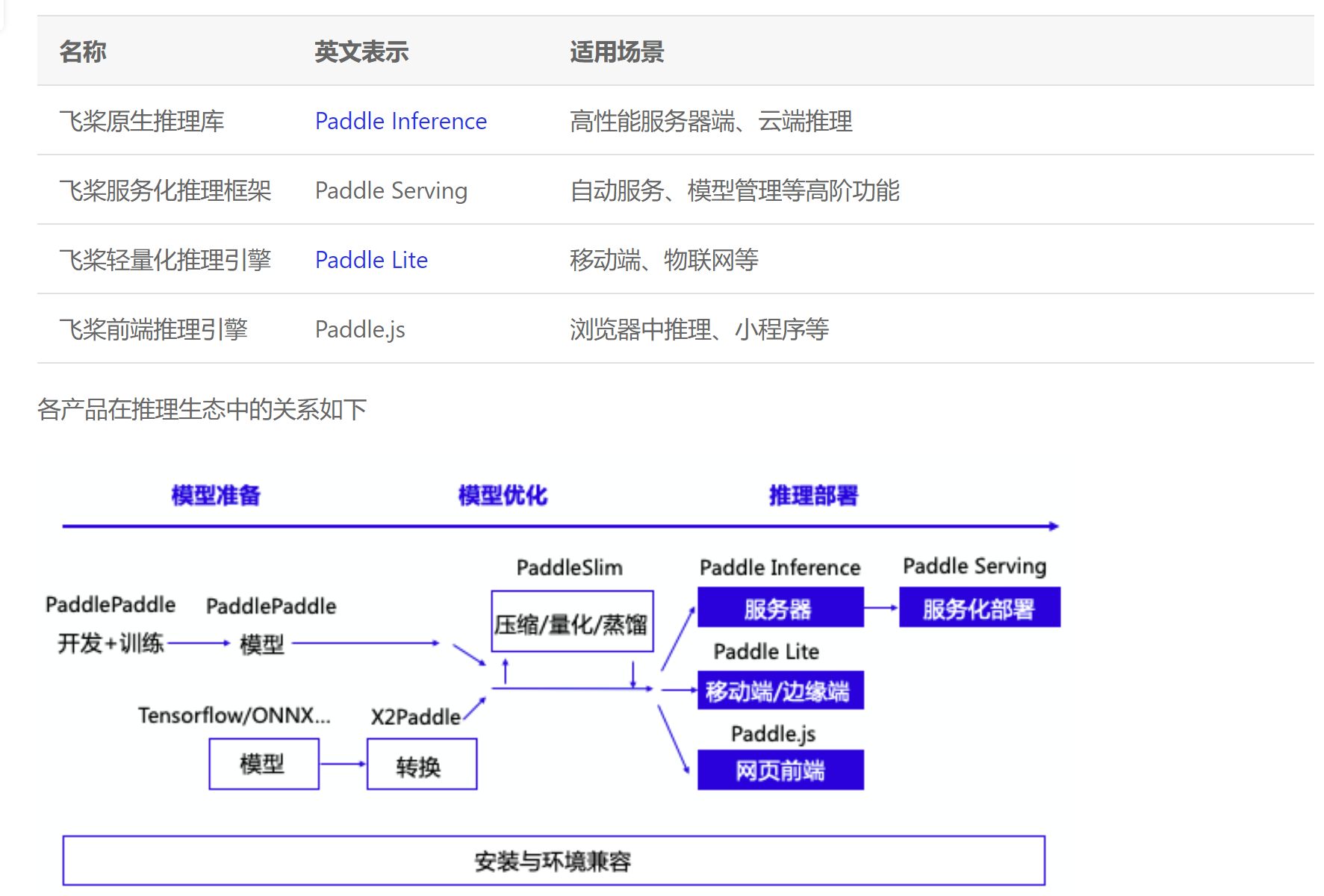 这附近文档还有个图,感觉不错
这附近文档还有个图,感觉不错 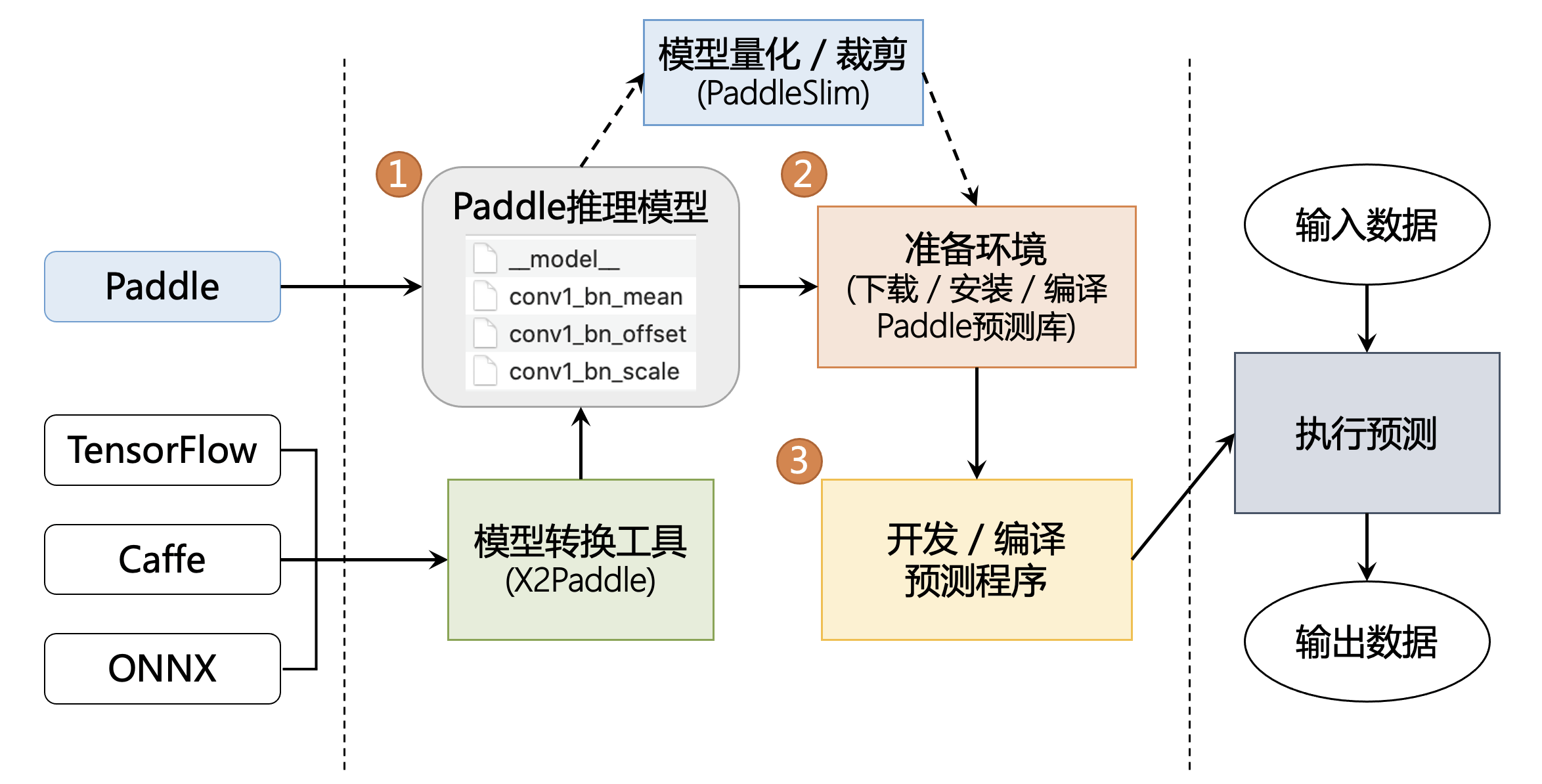
 还找到了一个使用Paddle inference进行口罩检测推理的: (二) 使用 Paddle Inference进行口罩检测
还找到了一个使用Paddle inference进行口罩检测推理的: (二) 使用 Paddle Inference进行口罩检测【本文地址】