| PaddleOCR二次全流程 | 您所在的位置:网站首页 › ocr文字识别作用 › PaddleOCR二次全流程 |
PaddleOCR二次全流程
|
文章目录
0. 💖合集目录1. 👓 读PPOCR论文:PP-OCR: A Practical Ultra Lightweight OCR System1.1 🙄摘要1.2 😎其他部分1.3 👀涉及的知识点
2. 🐱🚀关于把握整体流程的推荐读物3. 🕶 题外话3.1 🎇光学识别字符集 OCR字符集印刷图像
0. 💖合集目录
二次全流程合集目录: paddleocr系统性了解 PPOCR论文,https://arxiv.org/pdf/2009.09941.pdf 数据合成工具StyleText,在此之前需要确定图片字体,可以参考我的方式: PaddleOCR二次全流程——1. 确定字体 字体+背景生成某种风格的图片(数据合成) github链接 这个参考博客:PaddleOCR二次全流程——2.使用StyleText合成图片 半自动标注工具PPOCRLabel 是一款适用于OCR领域的半自动化图形标注工具,内置PPOCR模型对数据自动标注和重新识别,github链接 个人使用经验博客:PaddleOCR二次全流程——3.使用TextRender合成图片 FAQ 提供一些关于模型训练等的常见问题回答,一些经验之谈,结合论文有助于模型选择和数据集的整理 github链接 个人筛选之后的博客:PaddleOCR二次全流程——5.FAQ记录 模型分析 只分析paddleocr支持的一些模型,去看看论文,动手测一测。OCR模型列表-github链接,算法介绍-github链接论文中用到的一些策略/trick/strategies收集。预处理和后处理方式的收集。迁移训练(加入自己的数据[真实或合成的],PaddleOCR二次全流程——6. finetune预训练模型来匹配自己的数据) 额外推荐,github上的awsome系列:https://github.com/kba/awesome-ocr 从PaddleOCR的说明手册:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/README_ch.md 近期更新中,看到: 2020.9.22 更新PP-OCR技术文章,, 直接进入论文地址:https://arxiv.org/pdf/2009.09941.pdf 1. 👓 读PPOCR论文:PP-OCR: A Practical Ultra Lightweight OCR System只摘录部分重点内容,不做全文翻译。也可以参考另一个微信文章,和我的风格不太一样,哈哈。OCR漫谈之PaddleOCR(PP-OCR) 1.1 🙄摘要摘要(作为一个读了三年论文的水硕,摘要一定是要好好看的!) OCR已经被广泛应用于办公自动化系统,工厂自动化,在线教育以及街景地图等场景。然而,OCR仍然面临文本显示的多样性,以及计算效率需求等挑战。本文提出了一种实用的超轻OCR系统,即PPOCR,PPOCR识别6622个汉字的模型只有3.5MB,识别63个英文数字的模型只有2.8MB。我们引入了许多策略来进行模型能力的提升,或者是减小模型的大小。提供了对应的真实数据上的消融实验(ablation study)。同时,还发布了一些用于中英文识别的预训练模型,包括一个文本检测器(使用了97k张图),一个方向分类器(用于进行检测框矫正,使用了600k张图),还有一个文本识别器(使用了17.9M张图)。除此之外,提出的PP-OCR也在包括法语、韩语、日语和德语等其他几种语言的识别任务上进行了验证。上述提到的所有模型都是开源的,代码可以在Github仓库上获取[消融实验,类似于控制变量法,为了说明单独模块确实发挥了作用,可以参考其他回答:什么是 ablation study? - SleepyBag的回答 - 知乎] 1.2 😎其他部分部分重点内容
主要说明目前的OCR工作存在的问题 文本有多种显示,比如:场景文本识别(Scene Text Recognition,STR)和文本图像分析和识别(Document Analysis and Recognition,DAR)计算效率,在实际应用中,CPU的使用一定是优先于GPU,所以这就对OCR系统的运行和效率有了限制,同时OCR系统需要在嵌入式的端侧(比如:手机)等设备上运行,就需要对模型尺寸和准确率进行权衡。文本检测,PPOCR使用了DB(差分二值化)作为文本检测器,其基于一个简单的分割网络,DB简单的后处理策略使得它非常有效。 此外,为了提高准确率的同时保证效率(模型尺寸),使用了六种策略,如图Figure2。 使用了97k张图训练,检测框矫正,主要通过几何变换实现,因为检测框就是四个点构成的。但是矫正后的图片可能是颠倒的,即水平方向正确,垂直方向相反,此时需要做进一步处理。训练了一个简单的文本方向分类器,来进行文本方向的矫正。 同样为了保证准确率和模型大小,使用了4种策略,如图Figure2 使用了600k图训练文本识别,PPOCR使用了CRNN作为文本检测器,其整合了特征提取(CNN)和序列建模(RNN),使用了CTC(Connectionist Temporal Classification) Loss来避免预测和标签之间不对齐的问题,换言之,其优点就是:计算一种损失值,对没有对齐的数据进行自动对齐。 同样,为了增强模型模型准确性同时减小模型尺寸,使用9种策略,如图Figure2 使用了17.9M图训练 Enhance or Slimming Strategies这部分就分别介绍PPOCR三个模型优化所使用的的一些策略,主要也是引用了非常多的论文,同时为PaddleClas和PaddleSlim打了广告。 涉及到的一些策略我给出了下面一些参考网站。 最后就是实验结果比较,看看就行,主要把握整体架构和一些策略的使用。 还有一个信息:通常的文本识别方法中,常规的图像是32(高)*100(宽),但是为了保证方向分类器的识别准确率,在PPOCR中,使用的是48*192。 1.3 👀涉及的知识点FPN(2017):【论文笔记】FPN —— 特征金字塔 CTC: 白话CTC(connectionist temporal classification)算法讲解CTC Algorithm Explained Part 1:Training the Network(CTC算法详解之训练篇)CTC(Connectionist Temporal Classification)介绍SE(2017/2018):如何评价 Squeeze-and-Excitation Networks ? cosine learning rate decay:Tensorflow 中 learning rate decay 的奇技淫巧 Learning Rate Warm-up(2019年):神经网络中 warmup 策略为什么有效;有什么理论解释么?,另外一个博客:预热学习率的作用warmup_proportion FPGM Pruner:模型剪枝,作者本人的知乎文章:【CVPR 2019 Oral】利用几何中位数(Geometric Median)进行模型剪枝 这个过程还看到了一个很有意思的话题,回答也很好玩:卷积神经网络有哪些大胆又新奇的网络结构?Data Augmentation:数据增强中,说到了百度的论文SRN:《Towards accurate scene text recognition with semantic reasoning networks.》,可以看看翻译:Towards Accurate Scene Text Recognition with Semantic Reasoning Networks 论文翻译 另外,还说到了一个专用于文本识别的数据增强方式:TIA,论文Learn to Augment: Joint Data Augmentation and Network Optimization for Text RecognitionTIA的意思大概就是:对每个输入图像配置一些控制点(贝尔赛曲线,角点类似),让这些角点变化一个特定的分布(简单来说,就是让文本变形,背景图不变)PACT Quantization:参考了一个大佬的博客:闲话模型压缩之量化(Quantization)篇 这个人的博客写的都不错,还有一个讲为什么现在要压缩模型,是为了进行端侧部署的文章,浅谈端上智能之计算优化另外,原来PaddlePaddle在知乎上有专栏文章:模型精度不降反升!飞桨是这样改进PACT量化算法的!另外,关于MobileNetV3中的激活函数:MobileNet V3激活函数之h-swish 2. 🐱🚀关于把握整体流程的推荐读物 PaddlePaddle知乎专栏:https://www.zhihu.com/column/c_1102261020604628992PaddlePaddle微信部分有关OCR的问题: 2020-08-17:GitHub Trending第一之后,PaddleOCR再发大招:百度自研顶会SOTA算法正式开源!2020-08-31 百家桨坛 | 第一期:OCR文字识别专题100问2021年1月28日 手把手教你用PaddleOCR与PyQT实现多语言文字识别的程序,大概试了一下这个的ocr软件,一般般,哈哈哈,在win10上基本不可用。github地址:https://github.com/zhangming8/Dango-ocr,截止到2021.4.6 虽然显示服务器已经过期,但是还是可以下载的,就是下载之后没法使用了,因为处理模型识别部分是发送到服务器上的,如果想要使用,需要自己搭建服务器服务。 三年磨一剑——微信OCR轻松提取图片文字。可以看到,微信这个ocr小程序,用的都是百度提出的StyleText 合成文本行识别数据以及之前用过的textRender工具。 3. 🕶 题外话终于肯静下心来深入研究下ocr,然后发现,想要找一些关于ocr的书籍, 在百度上搜索:ocr光学字符识别 pdf书籍 没有结果在当当上搜索,ocr文字识别,也只有一本深度实践ocr-基于深度学习的文字识别 这一本虚的书(买了,写的就是深度学习,和文字识别关系真的不是很大,不会的还是不会的) 换了个关键字光学字符识别,搜出来国标?? 换了个关键字光学字符识别,搜出来国标?? 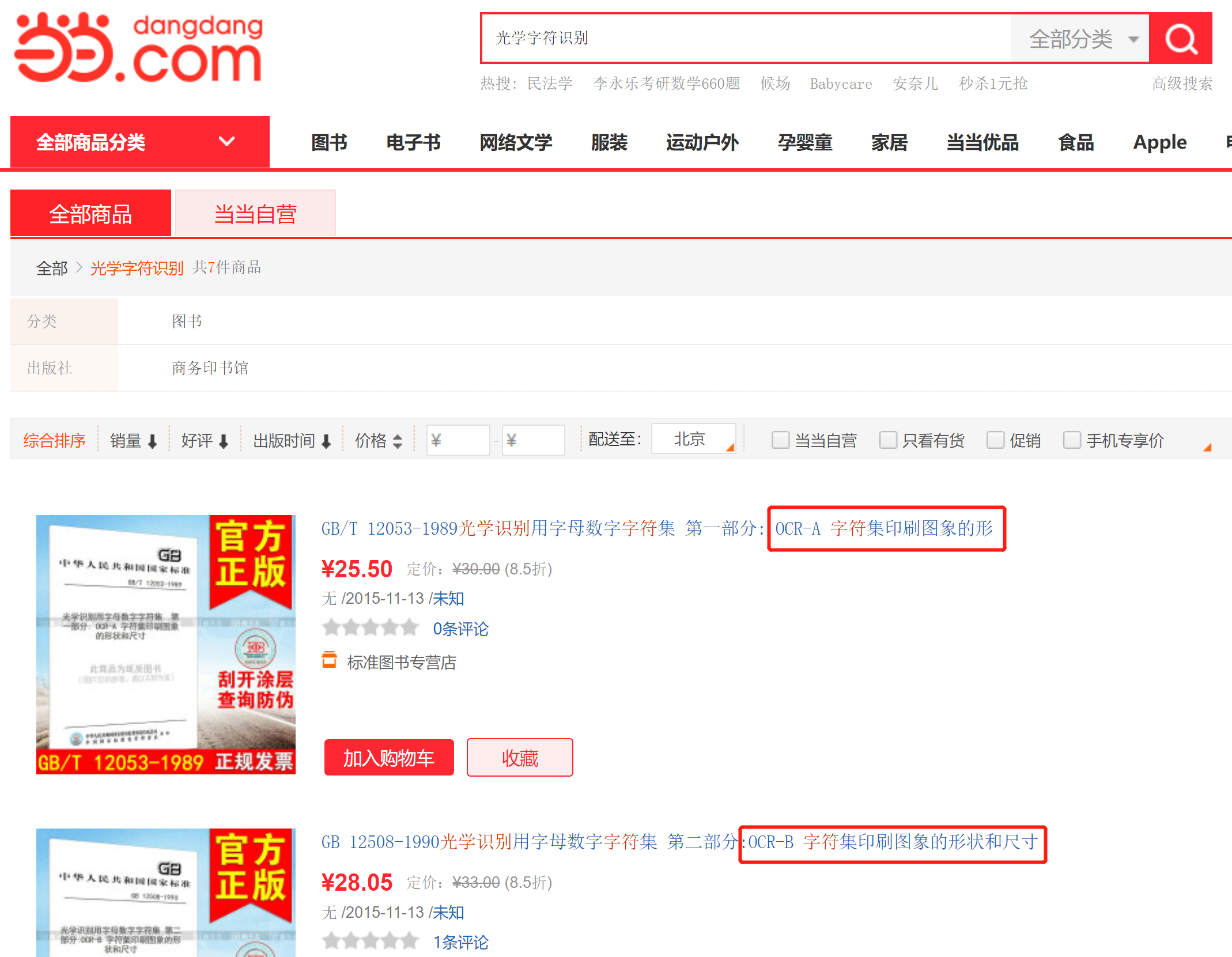
话说OCR这个领域,就是钱多哦,网上博客倒是很多,但是却没有一本正儿八经的书? 3.1 🎇光学识别字符集 OCR字符集印刷图像之前在一个介绍Halcon的OCR功能的博客上看到过类似的东西,来源:Halcon解决方案指南(18)OCR–字符识别 预训练字体 ’OCR-A’ 也有OCR-B,还有Semi等字体
我辈当自强! |
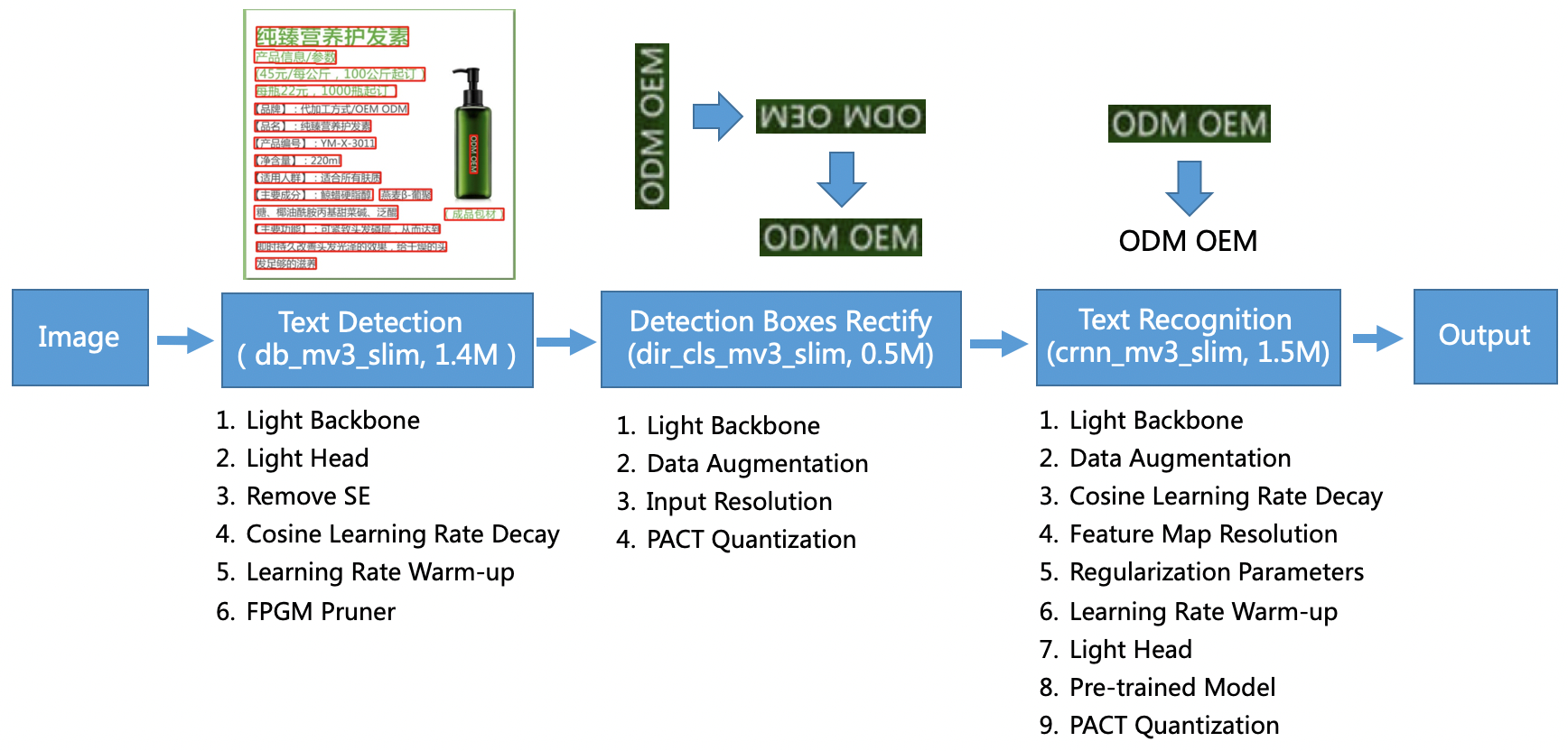 图自论文(Figure2)
图自论文(Figure2) 此外,关于这个东西,还有个论文,Don’t Decay the Learning Rate, Increase the Batch Size,以及一个知乎讨论:深度学习中的batch的大小对学习效果有何影响?
此外,关于这个东西,还有个论文,Don’t Decay the Learning Rate, Increase the Batch Size,以及一个知乎讨论:深度学习中的batch的大小对学习效果有何影响? 下载了一波国标文件,其中字间距各种都是有规定的,不用担心字间距这些,同时,我国的这些字体国标也是参考国际标准,等效于ISOXXXX,所以即便面对的仪器大多是外国产的,也安啦!
下载了一波国标文件,其中字间距各种都是有规定的,不用担心字间距这些,同时,我国的这些字体国标也是参考国际标准,等效于ISOXXXX,所以即便面对的仪器大多是外国产的,也安啦!【本文地址】