| 解决Navicat 连接 数据库(Mysql)出现中文乱码问题 | 您所在的位置:网站首页 › navicat修改数据后怎么保存 › 解决Navicat 连接 数据库(Mysql)出现中文乱码问题 |
解决Navicat 连接 数据库(Mysql)出现中文乱码问题
|
要想实现连接不出现乱码 就必须保持两端字符集相同; 一般我们在使用编码时是指字符集为UTF-8; 为什么要使用UTF-8的字符集? 如果各个国家都搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码。当时的中国人想让电脑显示汉字,就必须装上一个”汉字系统”,专门用来处理汉字的显示、输入的问题,装错了字符系统,显示就会乱了套。这怎么办?就在这时,一个叫 ISO (国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号的编码!他们打算叫它”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “UNICODE”。 UNICODE 开始制订时,计算机的存储器容量极大地发展了,空间再也不成为问题了。于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于 ascii 里的那些”半角”字符,UNICODE 包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于”半角”英文符号只需要用到低8位,所以其高 8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。 但是,UNICODE 在制订时没有考虑与任何一种现有的编码方案保持兼容,他总共可以组合出65535不同的字符,这大概已经可以覆盖世界上所有文化的符号。 注意这里的unicode其实只是定义了所有字符的1-65536的表示,还没有考虑具体计算机怎么存储怎么解析的问题。 首先UTF-8是unicode的实现,适应全球所有字符。 其次UTF-8是变长的,可以根据字符不同用1-3个字节,unicode2是1-8个字节来存储相对utf-16、utf-32节省存储空间 回到主题 首先查看自己的mysql编码 进入mysql小黑框 输入查看字符集的命令 show variables like '%char%';
因为我的是修改过的 所以这里显示的是utf8,一般未设置的话显示的事latin1; 首先需要修改配置文件my.ini 在[client]下添加default-character-set=utf8 在[mysql]下添加default-character-set=utf8 在[mysqld]下添加/修改为character_set_server = utf8 ,重启服务后生效 然后就是Navicat端 设计表->修改字符集
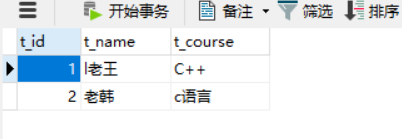
修改完毕后 显示为正确汉字。
|



【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |