| Mysql高级2 | 您所在的位置:网站首页 › mysql索引覆盖优化 › Mysql高级2 |
Mysql高级2
|
单表索引优化
建立的表 然后emp表插入了50万行,dept表插入了10万行数据 CREATE TABLE `dept` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAULT NULL, `address` VARCHAR(40) DEFAULT NULL, ceo INT NULL , PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; CREATE TABLE `emp` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `empno` INT NOT NULL , `name` VARCHAR(20) DEFAULT NULL, `age` INT(3) DEFAULT NULL, `deptId` INT(11) DEFAULT NULL, PRIMARY KEY (`id`) #CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; 全值匹配我最爱 EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 #解决方法 create index idx_age ON emp(age); EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4 #解决方法 create index idx_age_deptid ON emp(age,deptid); EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4 AND emp.name = 'abcd' EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE deptid=4 and emp.age=30 AND emp.name = 'abcd' #解决方法都是 create index idx_age_deptid_name ON emp(age,deptid,name); # 位置顺序变了 没关系,会进行优化 最佳左前缀法则如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
虽然可以正常使用,但是只有部分被使用到了。
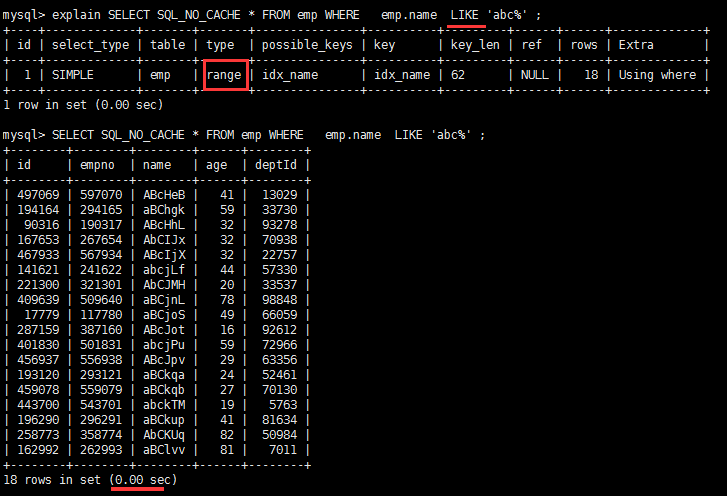
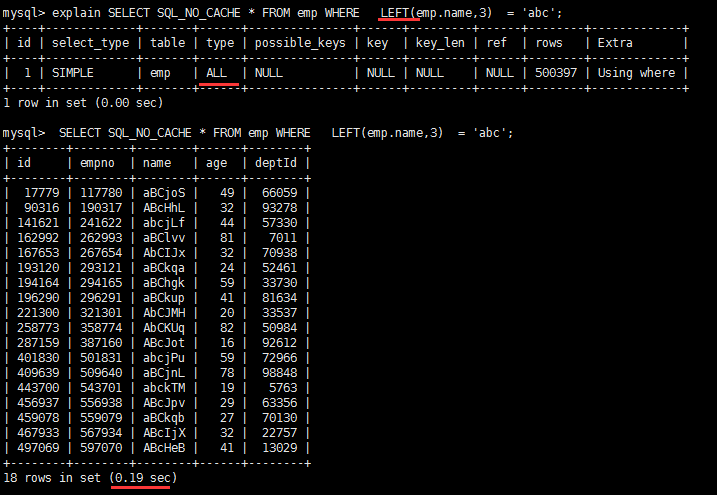
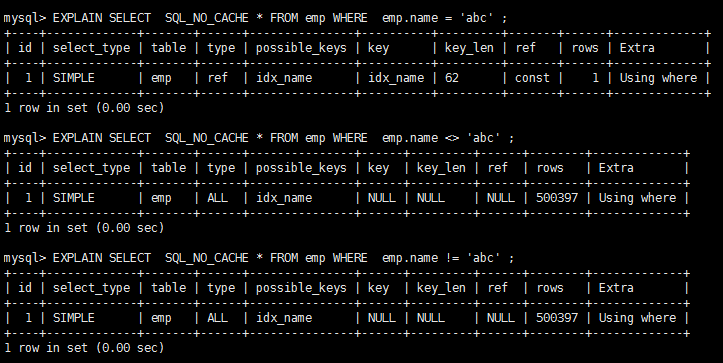
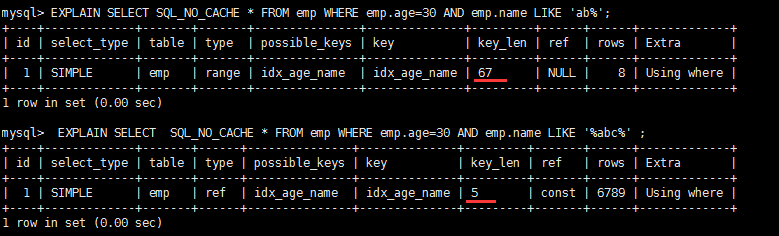
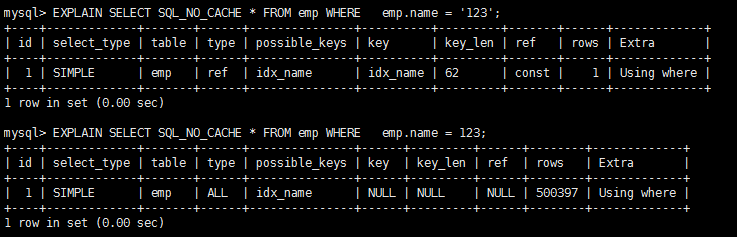
完全没有使用上索引。 #原始的select+索引 EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 and deptid=4 AND emp.name = 'abcd' create index idx_age_deptid_name ON emp(age,deptid,name); #命中了age字段 EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.age=30 AND emp.name = 'abcd' #一个都没命中 EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE deptid=4 AND emp.name = 'abcd' #最左指的是的索引的第一个字段 也就是age,从第一个开始 顺序命中 age->deptid->name结论:过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描这两条sql哪种写法更好 EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE emp.name LIKE 'abc%' #索引有效 EXPLAIN SELECT SQL_NO_CACHE * FROM emp WHERE LEFT(emp.name,3) = 'abc' #索引无效 CREATE INDEX idx_name ON emp(NAME)第一种
第二种
如果这种sql 出现较多 应该建立: # (这个 emp.deptId>20的索引关键字要放到最后) create index idx_age_name_deptid on emp(age,name,deptid)**和SQL里的顺序没关系 要索引的范围查询在最后就行了 ** 效果
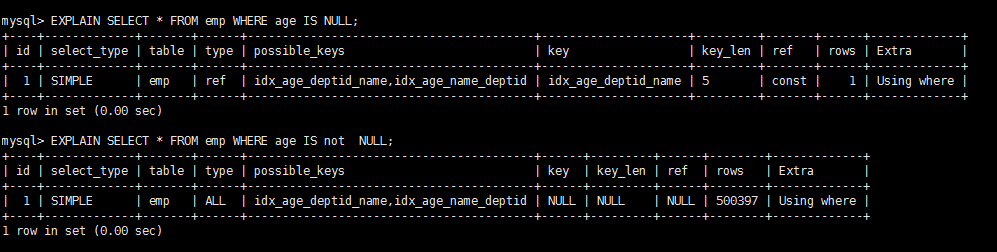
假设index(a,b,c) Where语句索引是否被使用where a = 3Y,使用到awhere a = 3 and b = 5Y,使用到a,bwhere a = 3 and b = 5 and c = 4Y,使用到a,b,cwhere b = 3 或者 where b = 3 and c = 4 或者 where c = 4Nwhere a = 3 and c = 5使用到a, 但是c不可以,b中间断了where a = 3 and b > 4 and c = 5使用到a和b, c不能用在范围之后,b断了where a is null and b is not nullis null 支持索引 但是is not null 不支持,所以 a 可以使用索引,但是 b不可以使用where a 3不能使用索引where abs(a) =3不能使用 索引where a = 3 and b like ‘kk%’ and c = 4Y,使用到a,b,cwhere a = 3 and b like ‘%kk’ and c = 4Y,只用到awhere a = 3 and b like ‘%kk%’ and c = 4Y,只用到awhere a = 3 and b like ‘k%kk%’ and c = 4Y,使用到a,b,c建议 对于单键索引,尽量选择针对当前query过滤性更好的索引(性别过滤性就不好)在选择组合索引的时候,当前Query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。在选择组合索引的时候,尽量选择可以能够包含当前query中的where字句中更多字段的索引在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面书写sql语句时,尽量避免造成索引失效的情况 关联查询优化建表 CREATE TABLE IF NOT EXISTS `class` ( `id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`id`) ); CREATE TABLE IF NOT EXISTS `book` ( `bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, `card` INT(10) UNSIGNED NOT NULL, PRIMARY KEY (`bookid`) ); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20))); INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));下面开始explain分析这时候还没建立索引 EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;以下是没用索引的情况
建立了索引之后 ALTER TABLE book ADD INDEX Y ( card);
给class表也添加索引 ALTER TABLE classADD INDEX Y ( card);
虽然type从all 变成了index,但是rows还是20行(总共就20行)还是全表扫描 # 第2次explain EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card; inner join中 mysql自己选择驱动表和被驱动表保证被驱动表的join字段已经被索引(前面的表是驱动表,后面的表是被驱动表) left join前面是驱动表后面是被驱动表 inner join 时,mysql会自己帮你把小结果集的表选为驱动表。 left join 时,选择小表作为驱动表,大表作为被驱动表。 子查询尽量不要放在被驱动表,有可能使用不到索引。 能够直接多表关联的尽量直接关联,不用子查询。 子查询优化 尽量不要使用not in 或者 not exists用left outer join on xxx is null 替代 SELECT * FROM emp a where a.id NOT IN (SELECT b.ceo FROM dept b where b.ceo IS NOT NULL) 优化 SELECT * FROM emp a LEFT JOIN dept b ON a.id = b.CEO WHERE b.id IS NULL; 排序分组优化ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序 create index idx_age_deptid_name on emp (age,deptid,name) #无过滤 不索引 以下 是否能使用到索引,能否去掉using filesort #这个不可以 1、explain select SQL_NO_CACHE * from emp order by age,deptid; #这个可以 2、explain select SQL_NO_CACHE * from emp order by age,deptid limit 10; #分页也是过滤 oder by一定需要过滤 #顺序错,必排序 简历索引 create index idx_age_deptid_name on emp (age,deptid,name) 3、 explain select * from emp where age=45 order by deptid; #用上过滤条件了:age->deptid 4、explain select * from emp where age=45 order by deptid,name; #用上过滤条件了:age->deptid->name
|








【本文地址】
公司简介
联系我们