| Motion Matching的发展回顾(上) | 您所在的位置:网站首页 › motion的翻译 › Motion Matching的发展回顾(上) |
Motion Matching的发展回顾(上)
本文主要翻译自育碧的一篇博客(见原文),恰好motion matching 和learned motion matching都是育碧提出的,顺便就借着翻译这篇博客的机会来梳理一下motion matching的发展。 https://www.zhihu.com/video/1615847622249447424 https://www.zhihu.com/video/1615847622249447424动作匹配(Motion Matching)是一种简单而强大的游戏角色动画合成方法。与其他方法相比,它不需要太多的手工工作,只要有一个基本的设置:不需要在动作图中构造动画片段的结构,不需要仔细地切分或同步它们,也不需要在状态之间显式地创建新的转换。然而,动作匹配最适合与大量的运动捕捉数据结合使用,而当使用所有这些数据时都有一个代价:大量的内存占用,随着系统的增长和应用场景的增加情况会变得更糟。在这里,我们提出了一种称为学习动作匹配的解决方案,它利用机器学习来大幅减少基于动作匹配的动画系统的内存使用。 动作匹配(Motion Matching)首先,让我们试着理解动作匹配本身是如何工作的。一个好的入手点是先检查检查我们要处理的数据——长的、无结构的动画——通常来自一个运动捕捉数据集。一个典型的来自这样一个数据集的动画如下:  https://www.zhihu.com/video/1615848428788957185 https://www.zhihu.com/video/1615848428788957185同时考虑这样的一个问题,基于原数据的基础之上,我们如何让这个角色按照以下的路径运动? 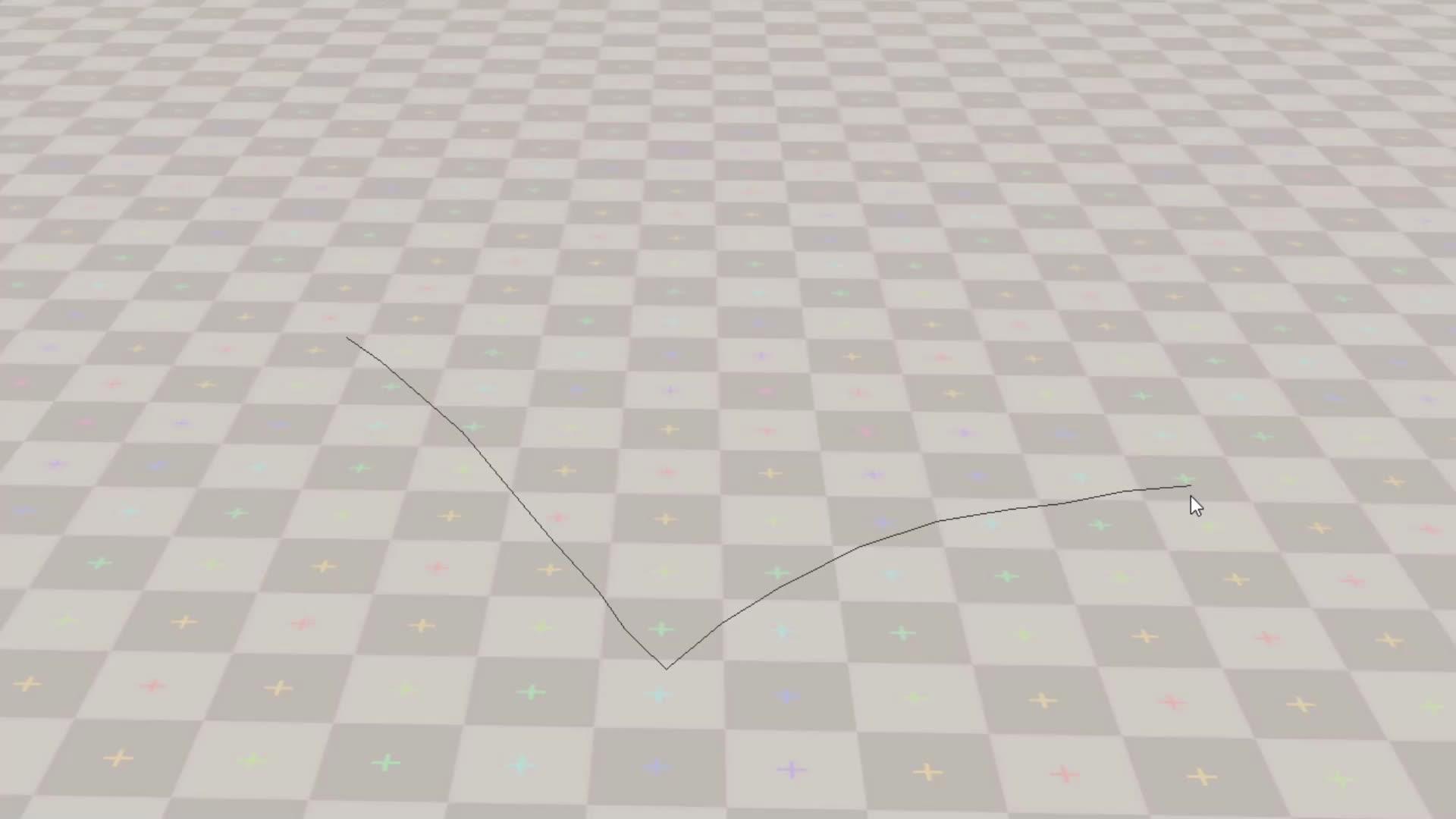 https://www.zhihu.com/video/1615848752467386368 https://www.zhihu.com/video/1615848752467386368当有了一个好的动画数据集之后,动作匹配就能够很好地解决这个问题。它的工作原理是反复搜索数据集重的片段,找到一个片段,如果从当前位置播放,它会比当前的片段更好地让角色保持在路径上。结果会是一个拼凑起来的动画片段,就像这样:  https://www.zhihu.com/video/1615850046082998272 https://www.zhihu.com/video/1615850046082998272决定何时开始播放一个新的动画,而不是继续播放现在你已经在播放的动画是关键。选择另一个片段,或者是说,跳转到我们数据集中的另一个动画帧,这需要我们能够衡量这种切换对我们的任务来说会有多好或多坏。决定具体如何做这件事很困难,因为一个动画帧包含了很多信息——而且其中一些信息可能对这个决策没有用处。  https://www.zhihu.com/video/1615851498990153728 https://www.zhihu.com/video/1615851498990153728一个好的解决方案是手动挑选一些我们称之为特征的信息,并用这些特征来决定一个特定的动画帧与任务的匹配程度。在这种情况下,我们需要能够表达两个方面的特征——角色将要遵循的路径,以便我们可以看到它与我们期望的路径有多相似——以及角色当前的姿势,以便如果我们开始播放新的剪辑,角色的姿势不会发生很大变化。通过一些实验,我们可以发现脚部位置、速度、角色髋部速度以及未来轨迹位置和方向的几个采样正是我们实现这个路径跟随任务所需要的特征。它们看起来是这样的: 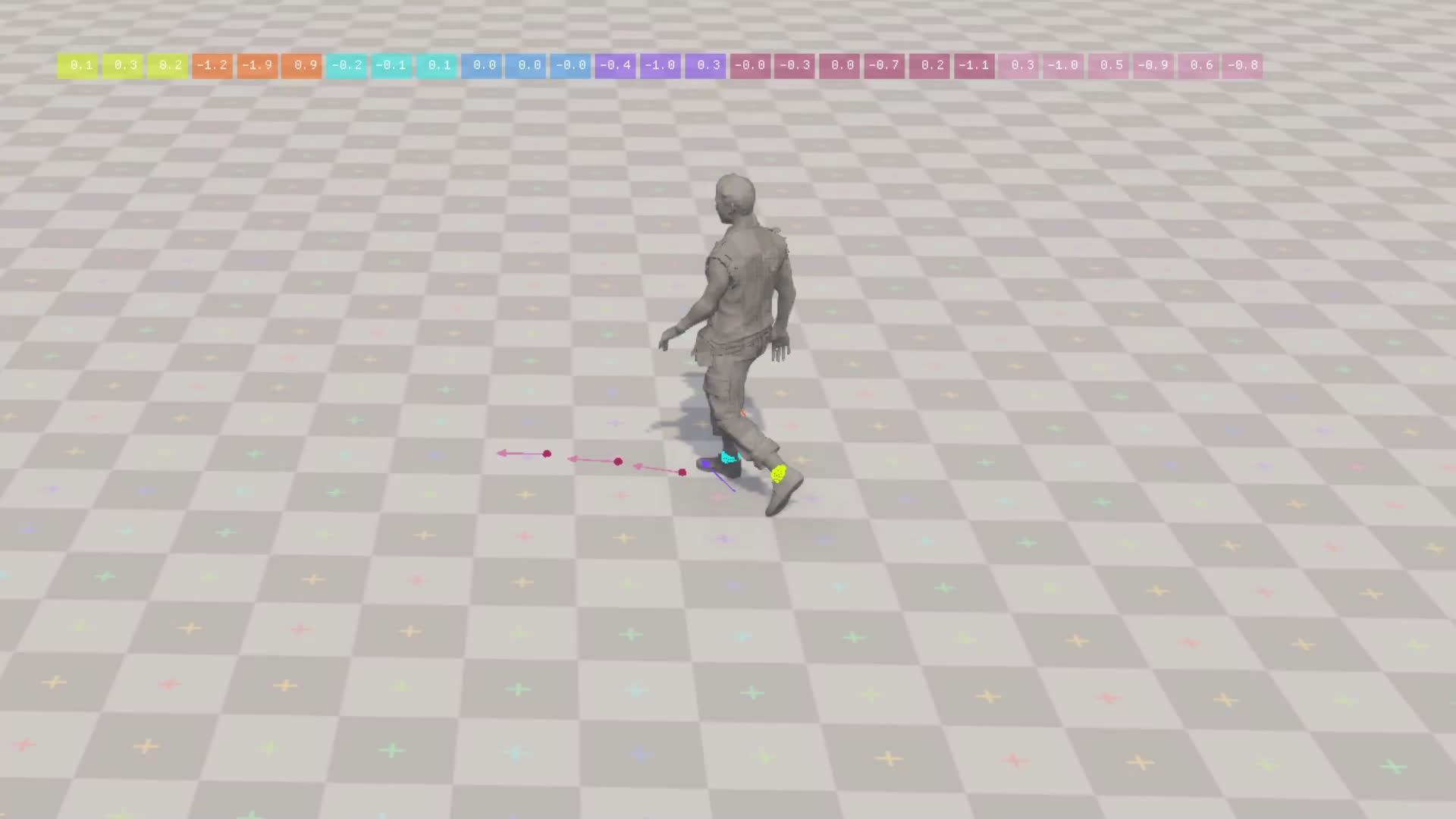 https://www.zhihu.com/video/1615852630965805056 https://www.zhihu.com/video/1615852630965805056这些信息不仅从我们直观上来讲,也对那些必须在运行时搜索最佳匹配的算法来说,更精简,更易于管理。如果从每一帧动画中收集所有的特征值到一个数组,得到一个向量,我们称之为特征向量(视频上方的彩色数组)。这是这一帧执行任务能力的精简数值表示。我们为数据集中的所有帧提取这些特征,并将得到的向量堆叠成一个大矩阵,称之为匹配特征数据库。当需要决定是否切换到新片段时,我们结合当前姿势和即将到来的期望路径部分构造成一个查询特征向量,并在匹配特征数据库中搜索与查询最匹配的条目。一旦找到,我们在动画数据集中查找相应的完整姿势,并从那里开始播放。下面是搜索和它找到的最佳匹配的展示:  https://www.zhihu.com/video/1616021393752936448 https://www.zhihu.com/video/1616021393752936448当我们切换到下一个动作片段那个烦人的突变该怎么处理呢?虽然我们有一些特征可以捕捉角色的当前姿势,我们也有一些表达未来轨迹的特征。包含那些轨迹的特征就接受为了保持沿着路径运动而牺牲动作的一些连贯性,如果姿势的变化不是太大,这种不连续性可以使用常见的技术轻松去除,例如短时间的交叉淡入淡出混合(cross fade),或者衰减过渡的源帧和目标帧之间的差异,也称为惯性化(inertialization)。这是我们应用了这种惯性化混合后的结果:  https://www.zhihu.com/video/1616025331026145280 https://www.zhihu.com/video/1616025331026145280最后,我们可以应用一些脚步锁定和逆向运动学方法可以得到一个更好的结果 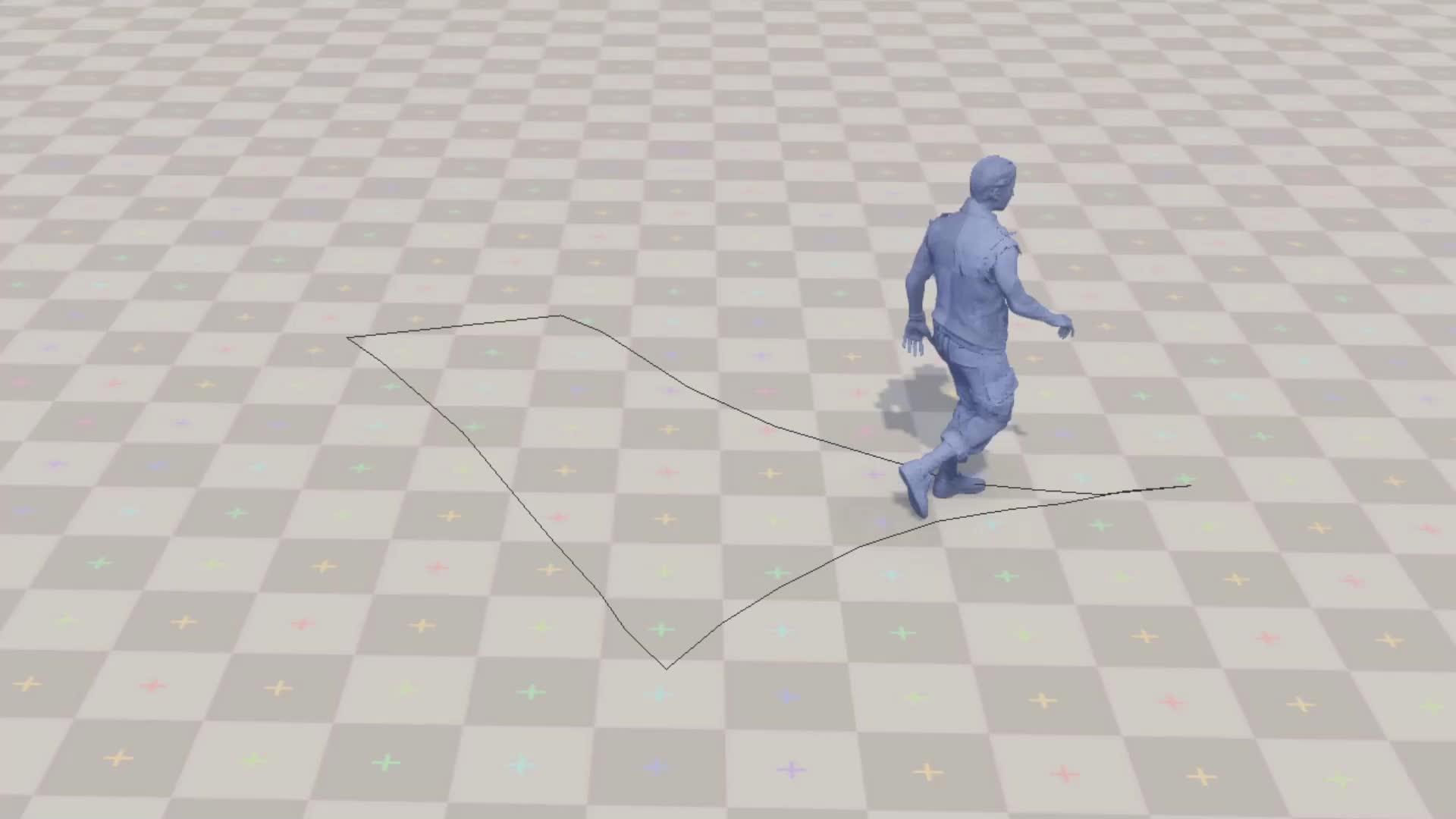 https://www.zhihu.com/video/1616025305189167104 https://www.zhihu.com/video/1616025305189167104并且这也就意味着,如果选择不同的用来匹配的特征,我们就可以实现一个完成不同任务的动画系统,例如和物件交互,在参差不齐的地面上面导航,或者甚至和其他的角色进行交互,这就是现在许多优秀的动画系统和游戏背后的成功秘诀。 扩展性问题(The Scalability Problem)现在你知道了运动匹配是如何工作的,想想一个3A作品可能需要多少动作数据。但确实,这取决于游戏的设计。这其中有很多因素要考虑,比如你想支持哪些类型的运动(静止、行走、慢跑、奔跑、冲刺、慢速侧移、快速侧移、跳跃、单脚跳、蹲伏等),可用的动作及其参数(打开门,坐到椅子上,拿起物体,骑马等),组合(比如走路,手持轻武器走路,手持重型双手武器走路),以及所有这些可能受到任务风格(比如平民和士兵的不同风格)和游戏状态(受伤,醉酒等)的影响。在你发现这个问题之前,你将会把许多MB级别,甚至GB级别的数据放入系统之中。并且让我们来强调一个动作匹配特别重要的地方:它并不能为你组合数据。如果你有一个走路和喝酒的数据,动作匹配并不能创造一个一边走路一边喝水的场景,动作匹配只能回放你提供给它的数据。 更具体地说,我们可以说一个动画片段是由一系列完整的姿势记录组成的,每个姿势都由帧索引(Frame Index)引用,它指向动画数据集中存储姿势的位置。播放一个片段意味着在每一帧上增加当前索引,并从动画数据集(Animation Dataset)中查找相应的完整姿势。运动匹配搜索每隔几帧就会进行一次,它通过将查询特征与匹配特征数据库(Feature Database)中的每个条目进行比较,返回最佳匹配的帧索引。将最佳帧索引替换当前索引,再从那里继续播放。下图总结了这个逻辑:  首先让我们考虑如何在这个过程中移除动画数据集查找这一步。一个想法是尝试重新利用之前为搜索计算的匹配特征数据库。毕竟,存储在这个数据库中的特征抓住了动画中许多关键的因素。让我们训练一个名为Decomposer的神经网络,它以匹配特征数据库中的特征向量作为输入,并产生相应的完整姿势作为输出。有了这个网络,每帧的逻辑现在看起来像这样:  让我们来看看这种方法和标准的姿态查找比起来表现的如何,下面你可以看到灰色的是标准的姿态查找生成的动作,红色的是用Decomposer生成的动作  https://www.zhihu.com/video/1616201096367415296 https://www.zhihu.com/video/1616201096367415296我们可以看到,虽然动画很相似,但偶尔会出现一些可见的错误(请看左侧骨架上的手部位置)。这是因为匹配特征并不能提供足够的信息,使我们能够在所有情况下重建姿势。尽管如此,重建动画的质量仍然令人惊讶地好。如果我们不仅仅依赖匹配特征数据库,而是给Decomposer提供一些额外的信息,比如更多的特征,会怎样呢? (知乎好像但篇文章的图片视频数量有限制,剩下内容可以见下篇) |
【本文地址】