| [论文阅读]时序数据中的异常检测 | 您所在的位置:网站首页 › majority中文 › [论文阅读]时序数据中的异常检测 |
[论文阅读]时序数据中的异常检测
|
Title: Revisiting Time Series Outlier Detection: Definitions and BenchmarksConference: NIPS 2021论文代码: https://github.com/datamllab/tods/tree/benchmark一、研究问题 时间序列异常检测问题中,很少有文献对现有的模型进行深入对比与分析。尽管有文献利用synthetic data对模型内在机理做出了探究,但整体而言缺乏对异常样本种类统一的定义。这篇文章旨在利用统一的范式去定义异常种类,并通过该范式生成的synthetic data更好的评价模型。 文章的主要贡献之一是将时序问题中的异常样本重新进行了归类,我们先来看一下以往学术文章中是怎么定义的: point outliers:如字面意思,这种异常样本往往以单个点的形式存在,其数值相较于整体样本而言是明显异常的(例如异常的大或异常的小);contextual outliers:区别于point outlier这种global outlier,contextual outlier的异常体现在某一段时间区间。例如下图的第二幅子图,该异常点相对于整体样本而言并无异常,但如果考虑其相邻时间内的样本,其有明显的异常特性;collective outliers:collective outlier是指的一段时间序列数据为异常。且该段数据中单独看每个样本点都不是异常的,样本的异常性体现在该段数据整体而言是异常的。 以往学术文章中对于异常样本的归类 以往学术文章中对于异常样本的归类尽管以往文献中已经对异常的类别有了比较好的归纳,文章指出异常的类别可以进一步细分。例如collective outliers,实际上可以进一步细分为shapelet, seasonal以及trend outliers三种形态,如下图所示。其中shapelet outliers指的是某段时间序列有unusual shape,seasonal outliers指的是某段序列有变现的季节性变化,而trend outliers则是序列有明显的趋势变化。  由于这三种形态的时序异常在现实生活中是真实存在的,将其笼统的全部划分为collective outliers是有问题的,比如某个算法发现其对collective outliers的检测效果不好,实质上有可能该算法对于shaplet outliers识别效果还不错,只是对于其他两类的异常(seasonal outliers以及trend outliers)识别有问题,笼统的对异常进行划分不利于探究模型的本质特性。 综上,文章的贡献主要是将collective outliers进行了更加细粒度的划分。相较于以往学术paper的定义,文章将其提出的定义范式命名为“Behavior-Driven Taxonomy”,如下图所示。其中point-wise outliers的定义基本没有变化,仍然是分为global以及contextual outliers,pattern-wise outliers进一步细分为shapelet, seasonal以及trend outliers。  二、理论逻辑 二、理论逻辑那么在对异常样本的种类进行了定义之后,核心问题就归结到如何根据定义的异常种类生成synthetic data,以及如何用synthetic data对模型进行深入探究。按照文章定义的名称,每种异常可以根据如下范式产生: Global outliers:global outliers生成的公式比较通俗易懂——既是我们常说的“多少倍标准差之外视为异常”的通用范式x_{t}=\mu(X)\pm\lambda\sigma(X) \\ 其中 \mu 为均值, \sigma 为标准差, X 代表整体样本。 Contextual outliers:contextual outliers指的是结合一段时间区间来看,某个点是异常的(注意contextual outliers仍属于point-wise outliers的范畴),那么上述的公式自然变化为:x_{t}=\mu(X_{t-k},X_{t+k})\pm\lambda\sigma(X_{t-k},X_{t+k}) \\ Shapelet outliers/ Seasonal outliers/ Trend outliers:对于这三种异常而言,文章通过下述公式产生:X=\rho(2\pi\omega T)+\tau(T)=\sum_{n}^{}{[Asin(2\pi\omega_{n} T)+Bcos(2\pi\omega_{n} T)]}+\tau(T) \\ 上述公式既是通过谱分析(spectral analysis)的方法将某个序列看成是由 n 个子序列的线性组合以及一个趋势项所构成的。其中shapelet outliers通过控制 sin(\cdot) 以及 cos(\cdot) 之间凸组合的系数来改变序列的形状;seasonal outliers通过控制频率参数 \omega_{n} 来生成;trend outliers则通过趋势项 \tau(T) 来生成,例如可以简单的取 \tau(T)=1 ,即整体的序列有一个水平上升的趋势。 三、实验结果1. Datasets依据上述理论,作者共涉及了35个模拟数据集(20个univariate datasets,15个multivariate datasets)。此外,作者还结合了4个真实数据集共同对异常检测算法进行比较。 2. Baselines作者比较的算法大体上可以分为三类: Prediction Deviation:主要是通过模型预测值与实际观测值之间的差距来判断是否为异常。该类别包括的算法有Autoregression(AR)、Gradient boosting regression Trees (GBRT)以及long short-term memory (LSTM)Majority Modeling:majority modeling假设正常样本在高维空间中应该是聚集的。该类别包括的算法有One-class SVM(OCSVM)、Isolation Forest(IForest)、Autoencoder(AE)以及Generative adversarial network(GAN)[1]。Discords Analysis:该方法将整体序列通过sliding window的方式划分为一个个的子序列,进而通过比较子序列之间的相似度来判断某个区间内的数据是否整体为异常。该类别包括的算法有Matric profile (MP)以及两个基于OCSVM和IForest的subsequence clustering方法(分别记为 \triangle OCSVM以及 \triangle IForest)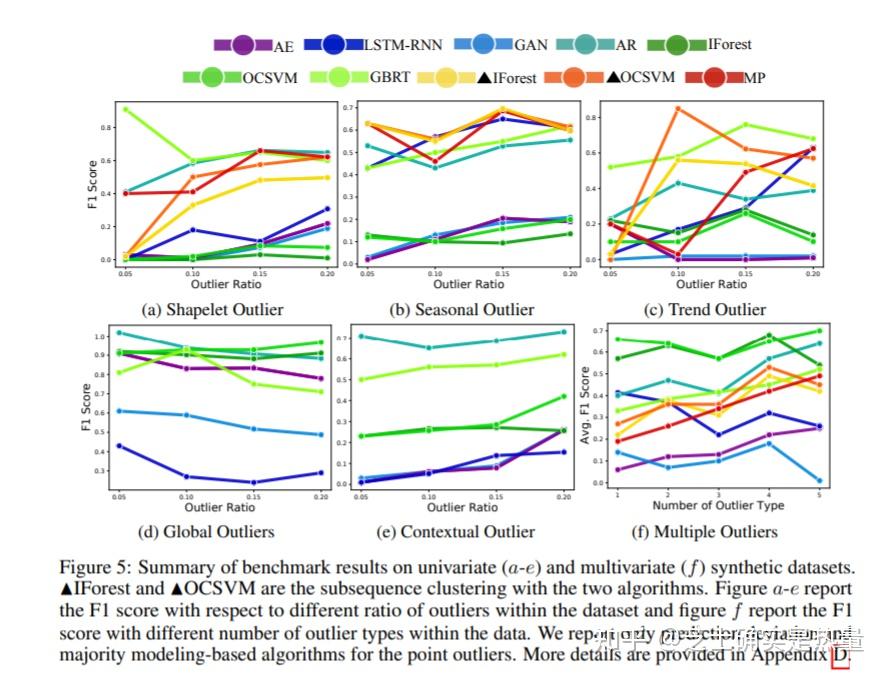 上述所有算法在synthetic datasets中的表现如上图所示,几个重要的结论可以根据图中得出: classical algorithms整体上要比deep learning methods要好;contextual outlier的检测整体而言要更难,各个模型的F1-score都比较低。值的注意的是简单的线性模型AR表现还不错,原因可能是AR模型的输入为观测值的几阶滞后项,天然对contextual outlier的检测更具优势;像AR、GBDT以及LSTM这种prediction-based algorithms,不仅天然对point-wise outliers检测的比较好,对于pattern-wise outliers也意外的检测效果不错;一些深度学习的模型,例如LSTM和GAN,效果并没有预想中的好,只对于某几类的异常识别的效果较好。该结论可以通过最后一幅子图得到,随着异常种类的增加,deep learning的模型效果普遍变差。 在此之外,作者还在4个真实数据集中探究了不同算法对于异常的识别效果,实验结果如上表所示。该部分实验结果反映出classical algorithms还是总体比deep learning models要好,例如AR、GBRT、IForest以及OCSVM相较于LSTM以及GAN[2]而言指标都明显要高。 写在最后这篇文章对时序数据中的异常检测问题重新进行了定义,并且根据定义范式生成模拟数据,对不同的baseline models进行了探究,文章整体而言清晰易懂。个人认为可以对不同模型为什么表现不好再做深入展开,例如用可解释性模型的框架进行分析,进一步明晰模型的内部机理。参考^注意这里的GAN并不是goodfellow提出的原生GAN,而是针对于异常检测算法所提出的GAN,详见链接中的论文内容 https://arxiv.org/abs/1809.10816^作者在表中没有列出GAN的相关结果,因为GAN几乎在真实数据集中无法有效检测出任何异常。作者分析这可能是由于真实数据比较复杂,GAN模型难以拟合这种较为复杂的真实数据 |
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |