| RNN结构有什么问题?LSTM解决了RNN什么问题?怎么解决的? | 您所在的位置:网站首页 › lstm为什么不用relu › RNN结构有什么问题?LSTM解决了RNN什么问题?怎么解决的? |
RNN结构有什么问题?LSTM解决了RNN什么问题?怎么解决的?
|
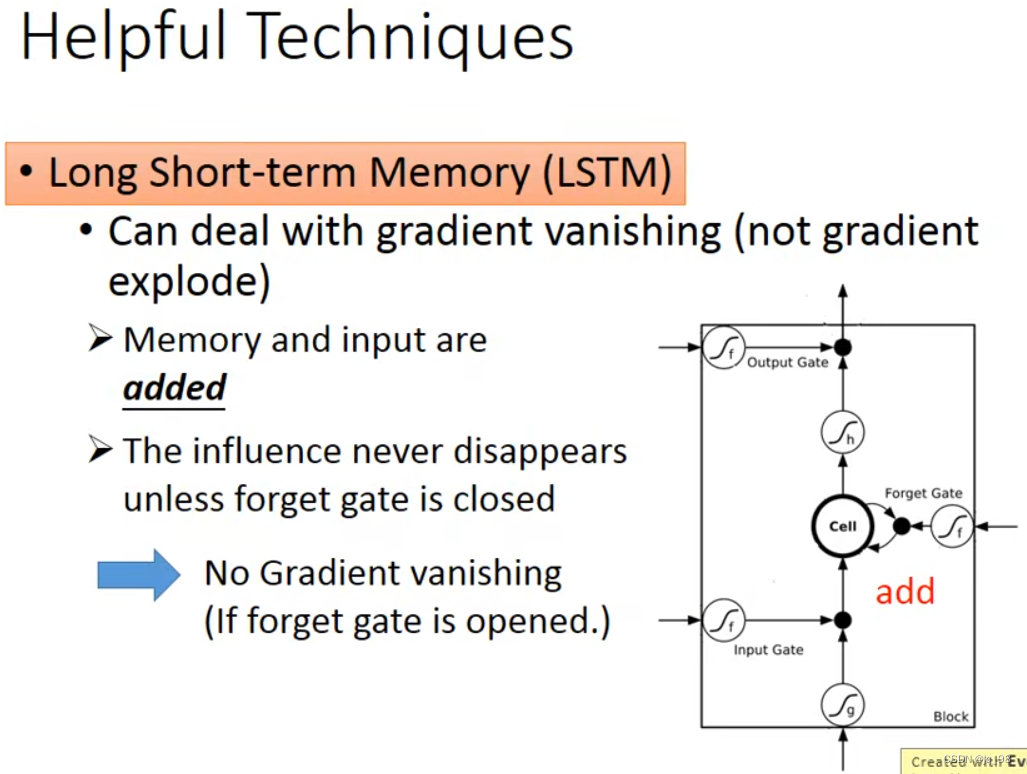
最近阅读了colah的LSTM博客,受益匪浅,浅谈一下这个问题,并且这个问题也是我面试的时候遇到的。 link:Understanding LSTM Networks 以及李宏毅老师2020年的视频讲解:link 讲解LSTM 和 GRU的 视频及动图:link colab手写的LSTM(便于以后做自定义结构更新):link 目录 一、RNN结构有什么问题?二、LSTM解决了RNN什么问题?怎么解决的?LSTM提出了门控机制:LSTM背后的核心思想Step-by-Step LSTM Walk ThroughStep1: 遗忘门发挥作用Step2: 决定在细胞状态中存储哪些信息(利用输入门)Step3: 决定此状态的输出(输出门发挥作用) 李宏毅老师课程:LSTM可以避免RNN的梯度消失问题 LSTM的门控激活函数是sigmoid,生成候选记忆的激活函数是tanhLSTM与RNN为什么是共享权值:总结 一、RNN结构有什么问题?循环神经网络(Recurrent Neural Network或RNN )就是一类用于处理序列数据的神经网络。RNN的状态,不仅受输入影响,还受前一时刻状态的影响。 RNN具有长期依赖问题: 长期依赖是指当前系统的状态,可能受很长时间之前系统状态的影响,然而常规的RNN结构中无法解决的一个问题。即RNN结构很难将很长时间以前的系统状态信息为自己所用 ,举两个例子: 如果从“这块冰糖味道真?”来预测下一个词,是很容易得出“甜”结果的。但是如果有这么一句话,“他吃了一口菜,被辣的流出了眼泪,满脸通红。旁边的人赶紧给他倒了一杯凉水,他咕咚咕咚喝了两口,才逐渐恢复正常。他气愤地说道:这个菜味道真?”,让你从这句话来预测下一个词,确实很难预测的。因为出现了长期依赖,预测结果要依赖于很长时间之前的信息。The cat, which already ate a bunch of food, was full. & The cats, which already ate a bunch of food, were full. 最后的was与were如何选择是和前面的单复数有关系的,但对于简单的RNN来说,两个词相隔比较远,如何判断是单数还是复数就很关键。长期依赖的根本问题是,经过许多阶段传播后的梯度倾向于消失(大部分情况)或爆炸(很少,但对优化过程影响很大)。 如果想更好的理解Long-Term Dependencies 问题,建议看一下 Google Brain 的科学家colah怎么解释的: The Problem of Long-Term Dependencies One of the appeals of RNNs is the idea that they might be able to connect previous information to the present task, such as using previous video frames might inform the understanding of the present frame. If RNNs could do this, they’d be extremely useful. But can they? It depends. Sometimes, we only need to look at recent information to perform the present task. For example, consider a language model trying to predict the next word based on the previous ones. If we are trying to predict the last word in “the clouds are in the sky,” we don’t need any further context – it’s pretty obvious the next word is going to be sky. In such cases, where the gap between the relevant information and the place that it’s needed is small, RNNs can learn to use the past information. LSTM重点解决了RNN的长期依赖问题 重点:LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn! LSTM及其变体被明确地设计了出来,为了解决长期以来问题。长时间记住信息实际上是他们的默认行为,而不是他们努力学习的东西! LSTMs also have this chain like structure, but the repeating module has a different structure. Instead of having a single neural network layer, there are four, interacting in a very special way.
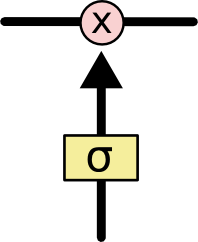
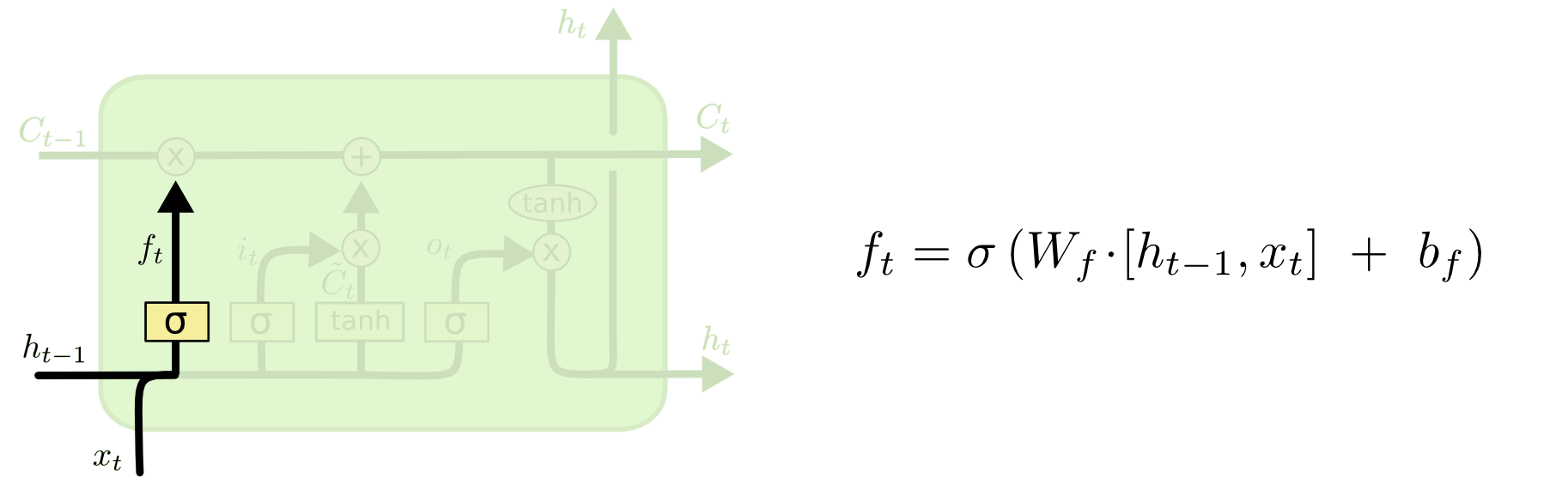
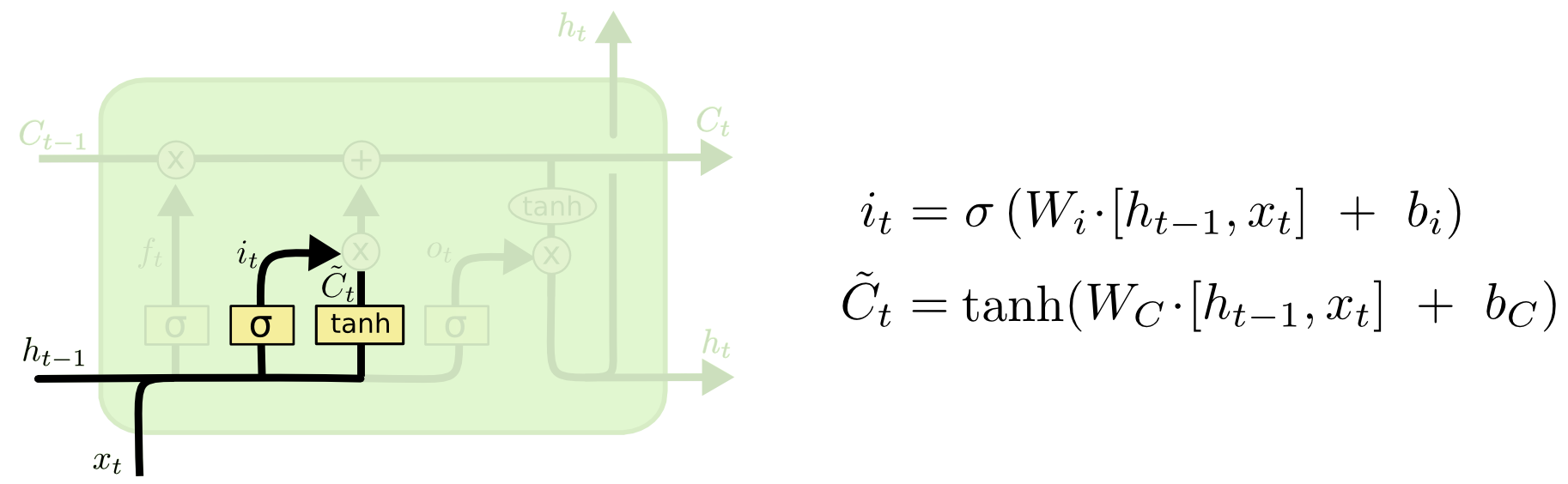
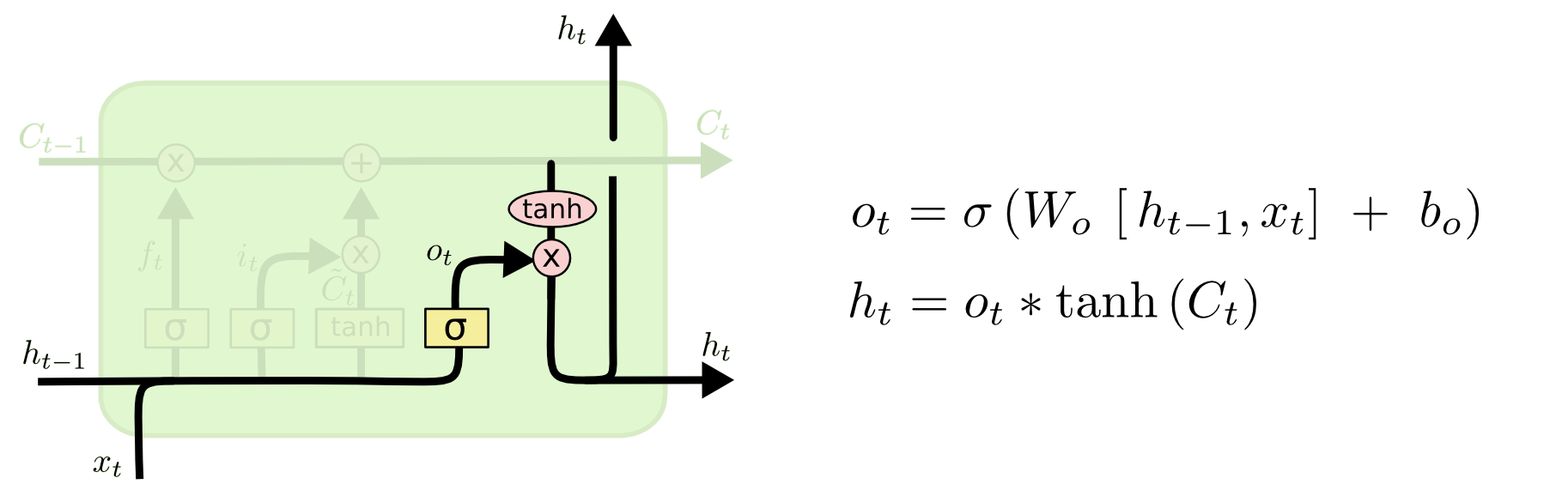
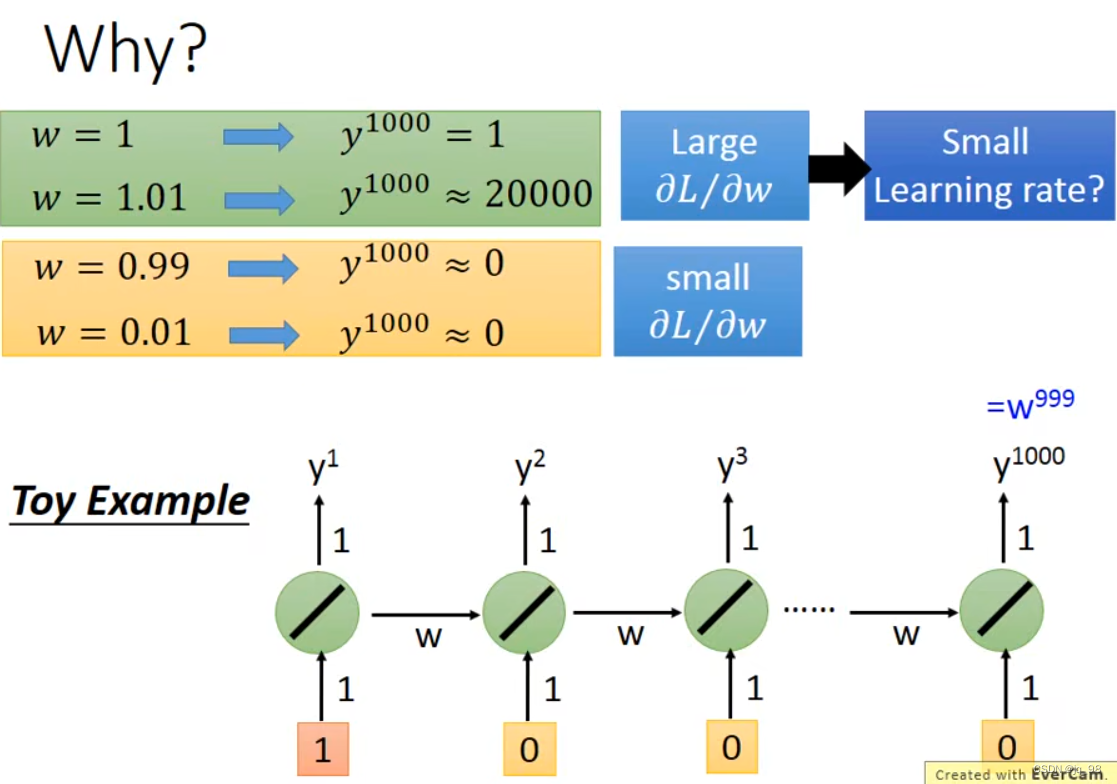
遗忘门、输入门、输出门 可以选择性的让信息通过! The key to LSTMs is the cell state, the horizontal line running through the top of the diagram. LSTM的核心状态是细胞状态,即贯穿水平的那一条线 (怎么理解:系统的信息一直在这条线上传递,总是在选择性的遗忘一些不必要的信息,并加入当前状态的重要信息,组成当前状态的总信息向下传递) The key to LSTMs is the cell state, the horizontal line running through the top of the diagram. LSTM确实能够向细胞状态中删除或添加信息,这些信息由称为门的结构仔细调节。 Gates are a way to optionally let information through. They are composed out of a sigmoid neural net layer and a pointwise multiplication operation. 门是一种选择性地让信息通过的方式。它们由一个sigmoid神经网络层和一个逐点乘法运算组成,sigmoid的输出介于0-1 之间,所以代表信息通过的多少 An LSTM has three of these gates, to protect and control the cell state. LSTM中有三种门,分别是:输入门,输出门以及遗忘门。 Step-by-Step LSTM Walk Through Step1: 遗忘门发挥作用The first step in our LSTM is to decide what information we’re going to throw away from the cell state. This decision is made by a sigmoid layer called the “forget gate layer.” It looks at ht−1 and xt, and outputs a number between 0 and 1 for each number in the cell state Ct−1. 遗忘门的输出:1 represents “completely keep this” while a 0 represents “completely get rid of this.” 如何理解这个遗忘门:拿一个语言模型来说,假设我们要预测某句话中的某个词,我们需要用到之前所有的语境,那么我们需要将遗忘门“开”到最小,这样就尽可能地获取到了前面的语境信息,如果我们要预测的这个词是一个新的语境,那么我们并不需要之前的语境,并且之前的语境对模型的判断还会产生干扰,所以我们需要尽可能地忘记之前地语境,这就是遗忘门需要控制以及学习的。 Step2: 决定在细胞状态中存储哪些信息(利用输入门)The next step is to decide what new information we’re going to store in the cell state. This has two parts. First, a sigmoid layer called the “input gate layer” decides which values we’ll update. Next, a tanh layer creates a vector of new candidate values, C~t, that could be added to the state. In the next step, we’ll combine these two to create an update to the state. 如何理解这一部分:还是以一个语言模型作为例子,在我们存储的信息中,我们选择性的选择了一部分遗忘(也有可能全部保留),面对此刻的一个语境,我们需要进行一个保留,用以替代被遗忘掉的那部分,做一个信息融合 Finally, we need to decide what we’re going to output. This output will be based on our cell state, but will be a filtered version. First, we run a sigmoid layer which decides what parts of the cell state we’re going to output. Then, we put the cell state through tanh (to push the values to be between −1 and 1) and multiply it by the output of the sigmoid gate, so that we only output the parts we decided to. RNN存在权重共享,李宏毅老师举了一个例子:所有的权重相同,那么下面一个简单的例子中,最后的前向传播中,只要w中的参数有一个很小的变化,就能引起巨大/小的梯度,造成梯度消失/爆炸 注意:LSTM与RNN相同,都是权值共享。 LSTM在其中引入了门控机制,变得更复杂了,与RNN不同的是LSTM有一个长时记忆,每一个时刻的影响都被保存下来了,形成一个新的记忆,进行传输。
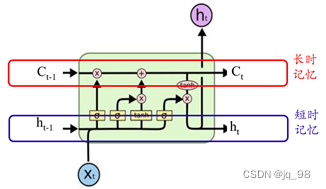
候选记忆用tanh是因为tanh的输出在-1~1,是0中心的,并且在0附近的梯度大,模型收敛快 参数共享有纯理论上的原因: 1、减少参数量,使得训练更加容易,减少训练难度 2、它有助于将模型应用于不同长度的示例。 在读取序列时,如果RNN模型在训练期间的每个步骤使用不同的参数,则不会将其推广到看不见的不同长度的序列。 通常,序列会根据整个序列的相同规则进行操作。例如,在NLP中: “星期一下雪了”“星期一在下雪”虽然细节在序列的不同部分中,但这两个句子的含义相同。参数共享反映了我们在每一步都执行相同任务的事实,因此,我们不必在句子的每一点都重新学习规则。 总结为什么LSTM(Long Short-Term Memory)为什么叫长短期记忆网络,总结来看,LSTM中红色的主线传递是长时记忆,而蓝色的主线传递的是短时记忆 |
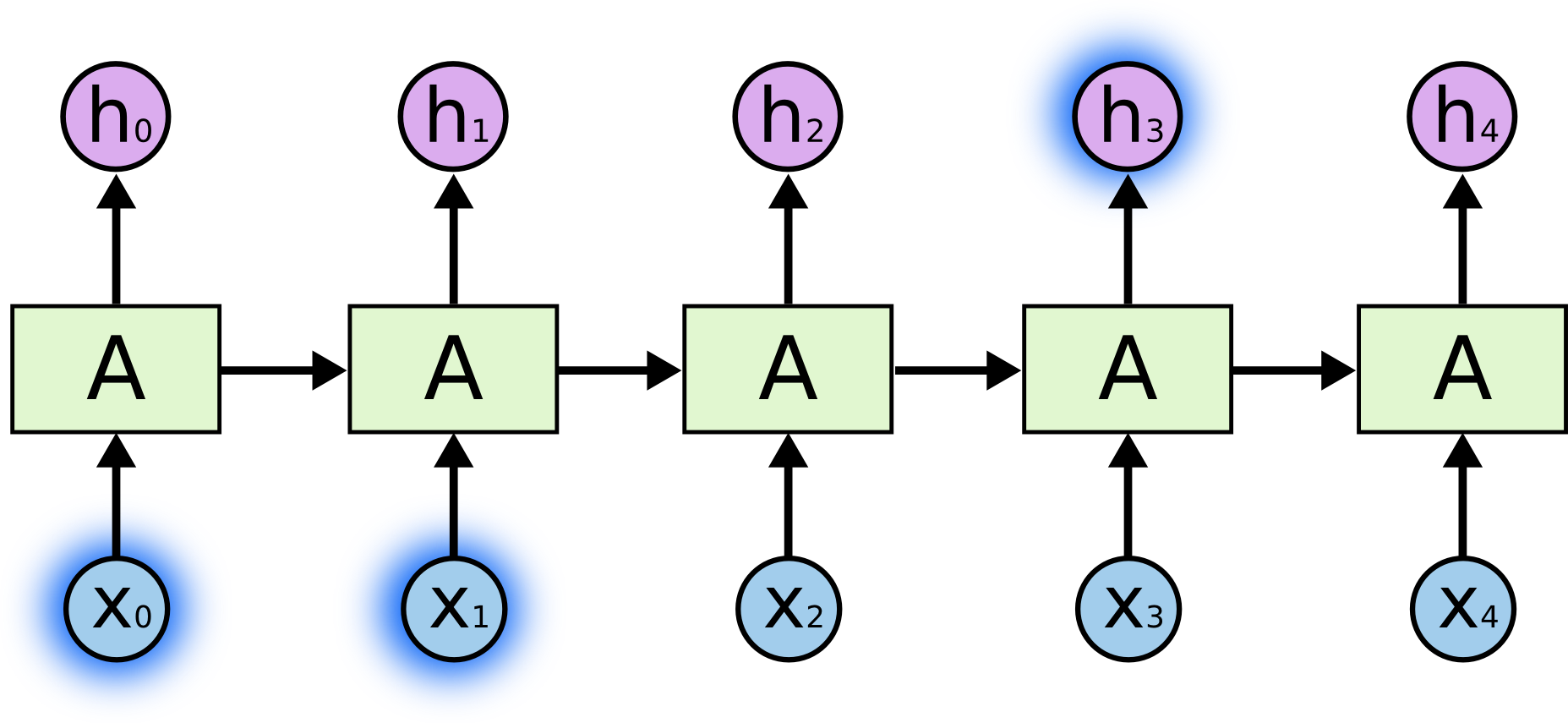 But there are also cases where we need more context. Consider trying to predict the last word in the text “I grew up in France… I speak fluent French.” Recent information suggests that the next word is probably the name of a language, but if we want to narrow down which language, we need the context of France, from further back. It’s entirely possible for the gap between the relevant information and the point where it is needed to become very large. Unfortunately, as that gap grows, RNNs become unable to learn to connect the information.
But there are also cases where we need more context. Consider trying to predict the last word in the text “I grew up in France… I speak fluent French.” Recent information suggests that the next word is probably the name of a language, but if we want to narrow down which language, we need the context of France, from further back. It’s entirely possible for the gap between the relevant information and the point where it is needed to become very large. Unfortunately, as that gap grows, RNNs become unable to learn to connect the information. 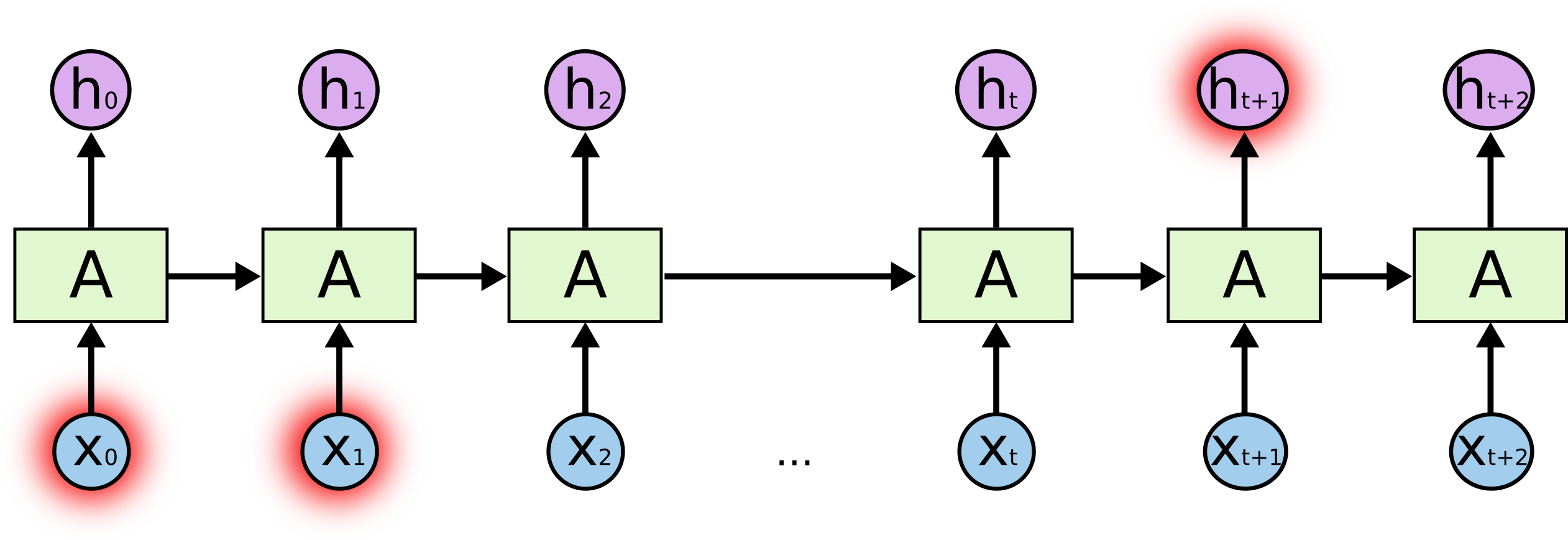 In theory, RNNs are absolutely capable of handling such “long-term dependencies.” A human could carefully pick parameters for them to solve toy problems of this form. Sadly, in practice, RNNs don’t seem to be able to learn them. The problem was explored in depth by Hochreiter (1991) [German] and Bengio, et al. (1994), who found some pretty fundamental reasons why it might be difficult. 单个RNN的内部结构:
In theory, RNNs are absolutely capable of handling such “long-term dependencies.” A human could carefully pick parameters for them to solve toy problems of this form. Sadly, in practice, RNNs don’t seem to be able to learn them. The problem was explored in depth by Hochreiter (1991) [German] and Bengio, et al. (1994), who found some pretty fundamental reasons why it might be difficult. 单个RNN的内部结构: 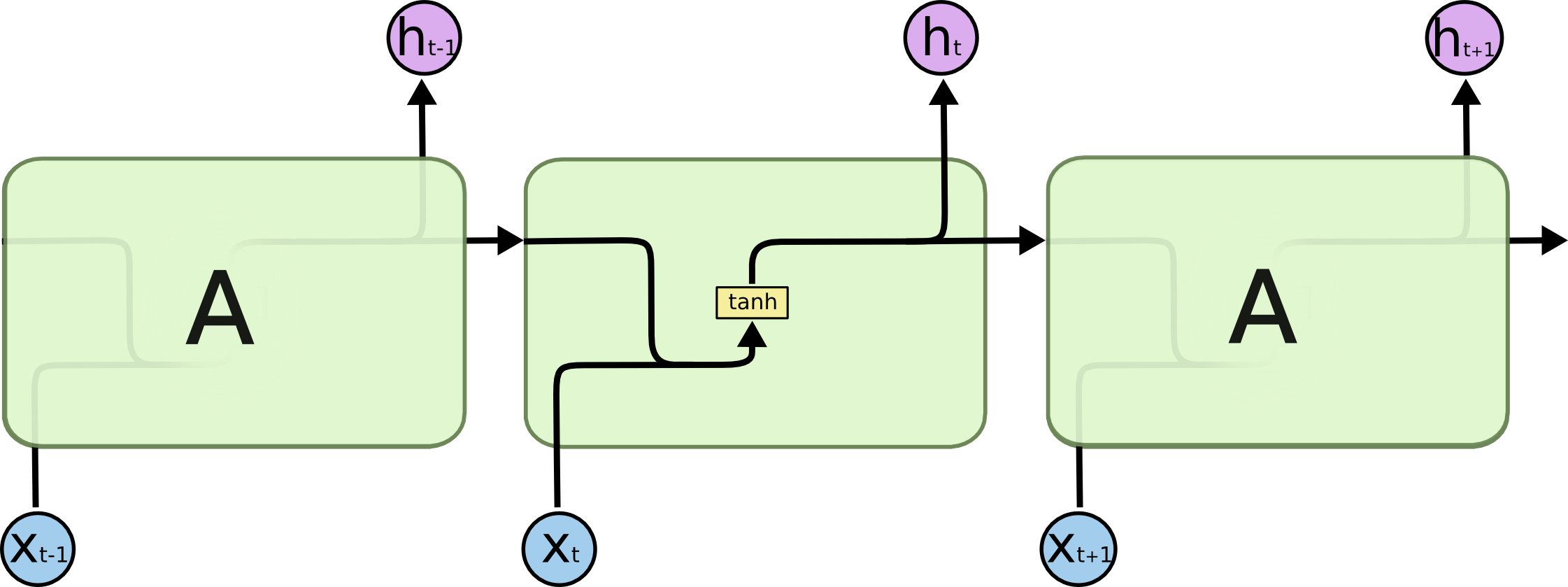 RNN内部的激活函数为什么要使用tanh,而不是用Relu? tanh 可以进一步缓解梯度消失/爆炸
RNN内部的激活函数为什么要使用tanh,而不是用Relu? tanh 可以进一步缓解梯度消失/爆炸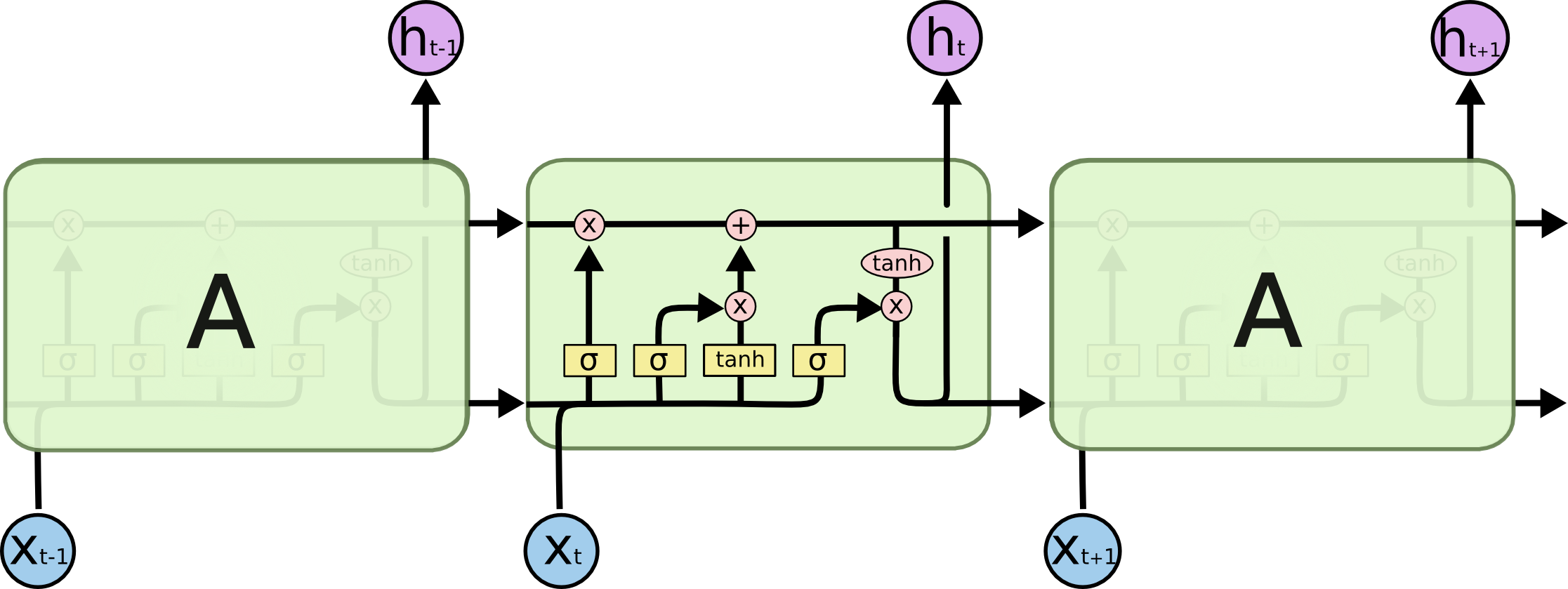

 It’s now time to update the old cell state, Ct−1, into the new cell state Ct. The previous steps already decided what to do, we just need to actually do it. We multiply the old state by ft, forgetting the things we decided to forget earlier. Then we add it∗C~t. This is the new candidate values, scaled by how much we decided to update each state value. In the case of the language model, this is where we’d actually drop the information about the old subject’s gender and add the new information, as we decided in the previous steps.
It’s now time to update the old cell state, Ct−1, into the new cell state Ct. The previous steps already decided what to do, we just need to actually do it. We multiply the old state by ft, forgetting the things we decided to forget earlier. Then we add it∗C~t. This is the new candidate values, scaled by how much we decided to update each state value. In the case of the language model, this is where we’d actually drop the information about the old subject’s gender and add the new information, as we decided in the previous steps. 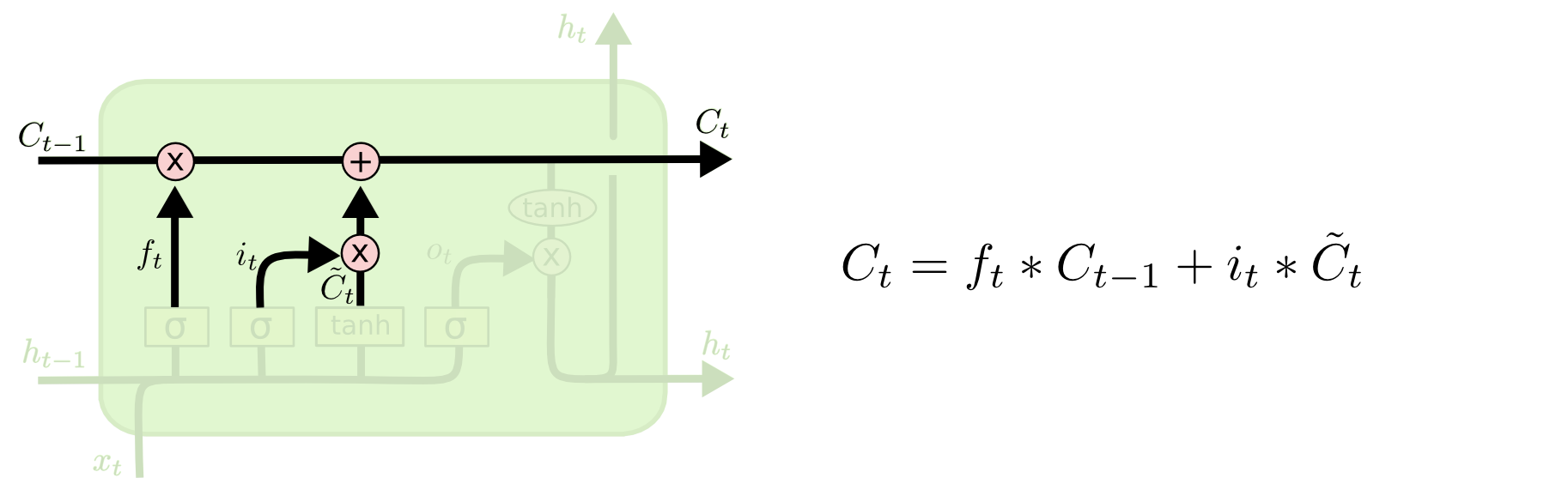

【本文地址】