| 离散选择模型(1) | 您所在的位置:网站首页 › logestic回归 › 离散选择模型(1) |
离散选择模型(1)
|
1.线性概率模型(Linear Probability Model,PLM)
2.Logistic回归与Logit模型
1.PLM
线性回归模型在定量分析中比较流行,但是在分析分类变量的时候,会遇到困难,比如因变量是分类变量。在现实生活中,人们也会将连续变量转化成分类变量进行分析,如将成绩这个连续因变量转化成能否考上大学的二分类变量。 在线性回归模型中,对自变量的限定性并不强,只规定了自变量不能是其他变量的完全线性组合,并且自变量不能与误差项相关。自变量可以是连续变量,也可以是分类变量。但是线性回归模型中,对因变量做了限定,规定其只能是连续变量。 用一个例子阐述在线性回归模型中因变量不能是分类变量的原因。 假设用OLS解释家庭扫地机器人的购买情况(因变量是二分类变量)。 为了方便叙述,只考虑一个自变量,回归模型如下:
其中 在给定
由于 公式(2 )左侧可以作为事件的发生概率来解释,因此,因变量是二分类变量的线性回归模型称为线性概率模型(LPM)。其中 对应的事件 i 不发生的概率为:
由公式(1)可以得出残差的表达式为:
当
当
令 f( 定义:当 当 因此残差的期望值为:
而对于残差 从公式可以看出残差的方差依赖于条件概率的测量值,因而也就是依赖于因变量的变动,于是不同的观测值便有不同的方差(方差的非齐性)。 因此,当使用OLS对因变量时二分类变量进行预测的时候,会有以下的问题: 由于在PLM中残差的非齐性,参数的估计的估计方差将是有偏差的。因此在任何的假设检验中,如t检验、f检验中,无论样本多大,都是无效的。由线性概率模型估计的事件的概率值,在遇到较大或者较小的x值时,可能会超出[0,1]区间。在线性回归模型中,回归系数由于OLS对于二分类因变量的不适用,因此使用非线性函数对其分析。在二分类因变量的分析中,常用的回归模型分别是以logistic为分布函数的logisti回归(又可称为logit回归),和以标准正态分布为分布函数的probit回归。 下面主要阐述logistic回归与logit回归之间的关联。其两者在本质上是相同的,不过前者估测的是事件 i 发生的概率,后者估测的是事件 i 的发生比。而当发生概率增加的时候,也就意味着发生比增大,反之亦然。 假设存在连续反应变量
因变量可以表示为:
因此:
其中 F 为 为了使累积分布函数有一个较为简单的公式,令logistic分布的均值为0,方差为
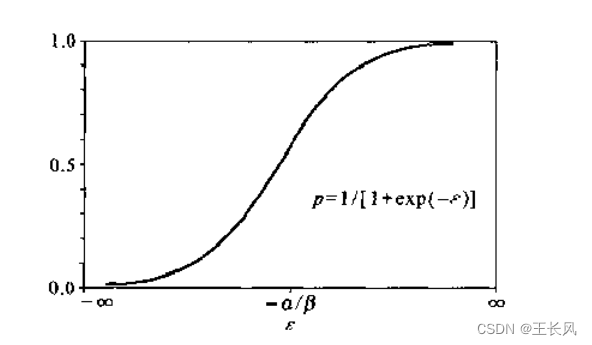
其图像如下: 无论 一个家庭购买扫地机器人的概率并不是收入每增加一个单位,概率便增加一个固定的量。实际上,家庭收入在某一段区间内变化时,才会对概率有较大的影响。收入过低或者过高,都不会对概率有较大的影响。原因是收入较低的家庭不会考虑购买扫地机器人,而收入较高家庭早已经购买扫地机器人了。 由上述可知 logistic 回归模型可以写成如下形式:
其中 令
事件 i 不发生的概率为: 因此事件的发生比odds为:
两边取对数有:
此处的对数变换称为 y 的 Logit 变换 ,既 logit(y),因此 logit(y) 便可以利用许多线性回归模型的性质。 Logit 模型的系数 根据文献资料可知,有时人们将“logistic 回归模型”、“logistic模型”、“logit模型”这些称谓相互混用。但此处,logit回归模型与logistic回归模型两者并不相同,前者估测事件的发生比的对数值,后者估测事件发生的概率。 注意:logit回归虽然是线性形式,但其与线性回归是完全不同的。 线性回归的因变量(结果变量、反应变量)与其自变量之间的关系是线性的,而Logit回归中的因变量和自变量的关系是非线性的,尽管这里将其变换成了线性的关系。在线性回归中,通常假设对应的自变量多元变量 当自变量的个数为K(K>2)时,事件 i 的发生概率为
其 logit 回归形式如下:
因此只要拥有了参数的估计值,样本观测值,便能分析事件的发生比以及发生概率。 参考文献: 王济川,郭志刚. Logistic 回归模型——方法与应用[M]
|





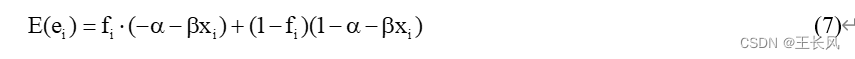 因为残差的期望值为0,所以有:
因为残差的期望值为0,所以有: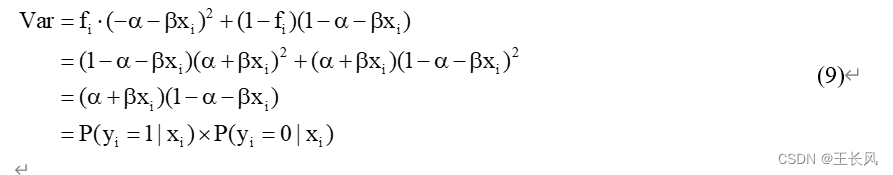
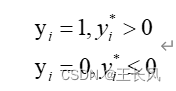

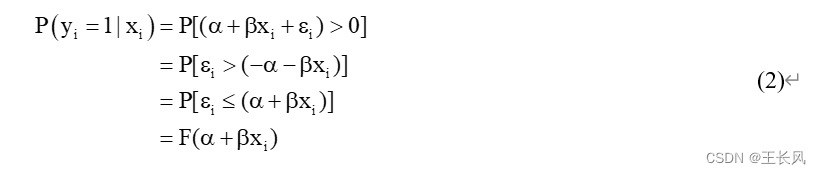
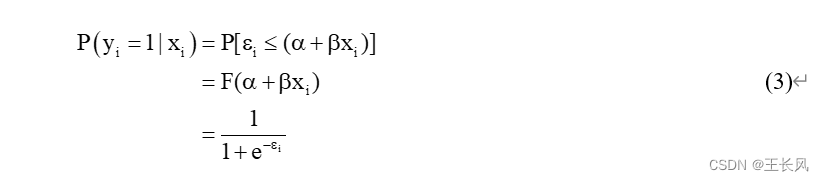
 其实质是
其实质是 
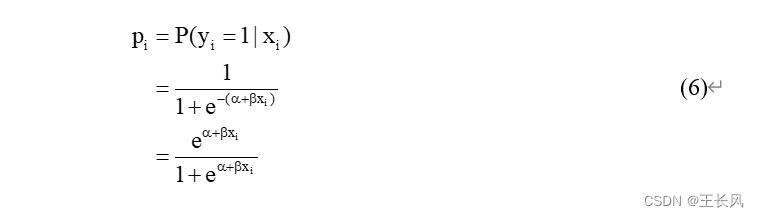





【本文地址】