| VQGAN图像生成(离散化加对抗训练) | 您所在的位置:网站首页 › lnx加1图像 › VQGAN图像生成(离散化加对抗训练) |
VQGAN图像生成(离散化加对抗训练)
|
1 简介
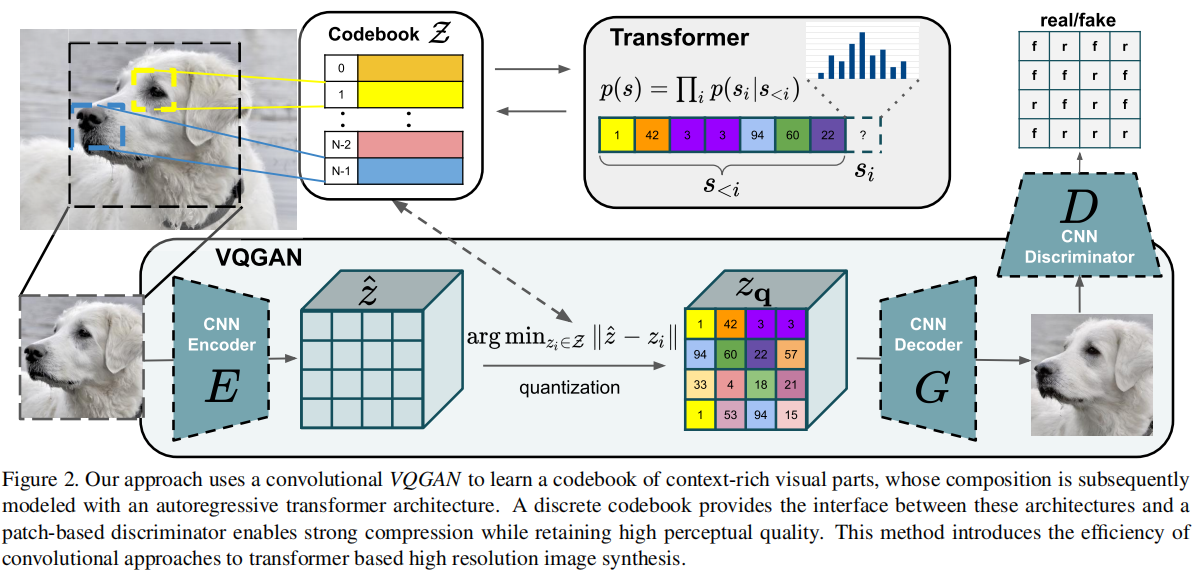
本文根据2021年6月的《Taming Transformers for High-Resolution Image Synthesis》翻译总结的。Taming是驯化的意思。从标题可以看到有效了利用了transformer。 我们显示了1)如何使用CNN学习了一个图像成分的语义丰富的词汇表,这部分也就是VQGAN;2)利用transformer在高分辨率图像中有效地对其组成(VQGAN压缩过的图片码书表示)进行建模。 整体模型也就如下图,包括两部分,VQGAN和transformer。VQGAN先进行图片的压缩,然后输入到transformer。VQGAN算是VQVAE的升级吧,使用了离散化VQ,也使用了对抗式训练GAN。
代替用像素表示图片,我们用码书(codebook)中的感知的丰富图片成分来表示。这样我们可以有效减少构成的长度,从而可以方便使用transformer。 2.1 学习一个有效的码书
然后图像通过解码器G重构恢复,如下式:
上面公式3的反向传输时不可微分。不过我们可以将解码器梯度直接复制到编码器,这样整个模型和码书就可以端到端训练了,损失函数如下:
VQGAN是VQVAE的变体,使用识别器D和感知损失,在增加压缩率下保持好的感知质量。损失函数如下:
完整的损失函数如下:
接着使用自回归模型,通过索引为i之前的序列预测索引i。即如下式:
我们可以直接最大化log-likelihood。
就多加了条件c,改为下式:
使用了滑窗注意力,如下图
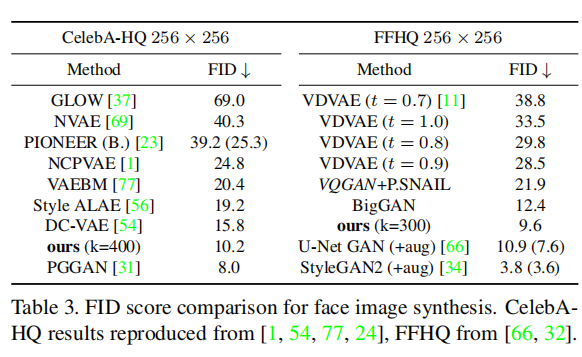
使用码书长度|Z|=1024. 如下表,在人脸合成上,VQGAN效果好。
VQGAN和VQGAE、DALL-E(也是基于VAE的)相比,在imageNet数据上,效果也较好。
下图,更加直观的比较了VQGAN和VQGAE,VQGAE效果模糊,而VQGAN更逼真。
|

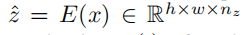
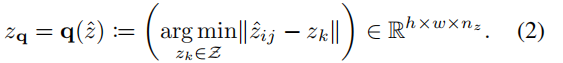


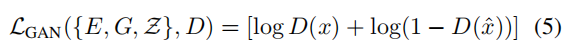
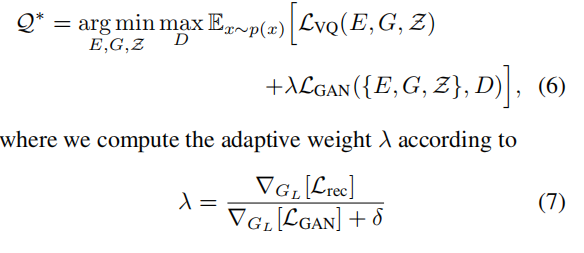

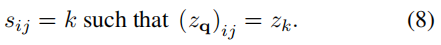

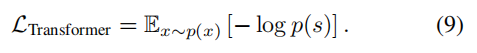
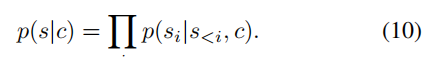



【本文地址】
公司简介
联系我们