| 阅读笔记 | 您所在的位置:网站首页 › ldr图像 › 阅读笔记 |
阅读笔记
|
题目:Joint HDR Denoising and Fusion: A Real-World Mobile HDR Image Dataset 链接:CVPR 2023 Open Access Repository (thecvf.com) 年份:2023年 会议:CVPR 摘要:手机已经成为我们日常生活中无处不在、不可缺少的拍照设备,而光圈小、传感器尺寸小,使得手机更容易受到噪声和过饱和的影响,从而导致低动态范围(LDR)和低图像质量。因此,开发用于移动电话的高动态范围(HDR)成像技术至关重要。遗憾的是,现有的HDR图像数据集大多是由单反相机在白天构建的,限制其对手机HDR成像研究的适用性。在这项工作中,作者首次利用手机相机开发了一个HDR图像数据集,即mobile-HDR数据集。具体而言,利用三个手机摄像头在原始图像域中收集配对的LDR-HDR图像,涵盖不同噪声水平的白天和夜间场景。然后,提出了一个基于transformer的模型,该模型具有金字塔交叉注意对齐模块,用于聚合来自不同曝光帧的高度相关特征,以执行联合HDR去噪和融合。实验验证作者的数据集和方法在移动HDR成像中的优势。 介绍: 在过去的十年中,深度学习已经展示了其从大量数据中学习图像先验的强大能力。遗憾的是,HDR成像的深度模型发展相对缓慢,主要是由于缺乏合适的训练数据集。Kalantari等[10]利用单反相机在白天构建了第一个LDR-HDR图像对数据集。受益于这个数据集,许多深度学习算法被提出用于HDR成像。一些研究[10]采用卷积神经网络(CNN)对多帧光流对齐后进行融合[18],但在遮挡和大运动情况下不可靠。后续的工作是利用各种网络从LDR帧直接重建HDR图像。Liu等人[19]开发了一种基于可变形卷积的模块来对齐输入帧的特征。Yan等人[40]提出了一种空间注意机制来抑制不需要的特征,并采用扩展卷积网络[42]进行帧融合。根据这种空间注意机制,一些融合网络发展出更大的接受域,如非局部网络[41]和Transformer网络[21]。 虽然[10]开发的数据集在很大程度上促进了HDR成像的深度学习研究,但它并不适合手机相机HDR成像技术的研究。首先,由于光圈小,传感器尺寸小,手机拍摄的图像比单反相机更容易受到噪音的影响,尤其是在夜间。然而,数据集[10]中的图像通常非常干净,因为它们是由单反相机在白天采集的。与单反相机相比,手机相机的正常曝光帧含有更强的噪点,需要通过与其他帧融合来降低噪点。其次,手机相机的记录位(12位)通常比数码单反相机(14位)少,导致参考帧中的过曝区域更大。因此,移动HDR成像是一个更具挑战性的问题,需要新的数据集和新的解决方案。 为了解决现有HDR数据集的上述局限性,便于对现实世界移动HDR成像的研究,作者利用手机摄像头建立了一个新的HDR数据集,即mobile-HDR。具体而言,利用三部手机采集原始图像域的LDR-HDR图像对,涵盖了不同噪声水平的白天和夜间场景。为了获得高质量的HDR图像地面真值,首先采用多帧平均的方法采集每次曝光下无噪声的LDR图像,然后融合生成的干净LDR帧合成地面真值HDR图像。对于有物体运动的动态场景,按照[10]的方法,首先从静态场景中捕获多帧曝光帧,合成地面真实HDR图像,然后将非参考帧替换为动态场景中捕获的图像作为输入。这是第一个带有成对训练数据的移动HDR数据集。 本文提出的方法:在建立数据集的基础上,提出了一种新的基于Transformer的HDR联合去噪和融合模型。为了增强去噪和实现对齐,我们设计了一个金字塔交叉注意模块来隐式对齐和融合输入特征。交叉注意操作可以从不同帧中搜索和聚合高度相关的特征,而金字塔结构可以在严重噪声、大曝光和大运动下实现特征对齐。然后应用Transformer模块融合对齐后的特征进行HDR图像恢复。 文章贡献: •利用不同场景下的LDR-HDR图像对构建了第一个移动HDR数据集。 •提出了一种基于交叉注意的对齐模块来进行有效的联合HDR去噪和融合。 •进行了大量的实验来验证作者的数据集和模型的优势,为研究人员研究和评估现实世界的移动HDR成像技术提供了一个新的平台。 0. 数据集 ------(raw格式、适用移动手机、作者本人制作) 为便于移动HDR成像的研究,作者利用手机摄像头在原始图像域建立LDR-HDR图像配对数据集。具体来说,使用了四部手机,配备了三种类型的移动传感器(IMX586, IMX766和IMX800)来捕捉不同曝光和光照条件下的图像,包括室内、室外、白天和夜间场景。数据集中的ISO设置范围从100到6400,涵盖了各种噪音水平。数据集由三个子集组成:①具有(GT)HDR图像的静态场景子集,②具有(GT)HDR图像的动态场景子集,③没有(GT) HDR图像的动态场景子集(仅用于视觉比较)。 对于静态场景子集,通过固定在三脚架上的带有定制应用程序的手机捕捉三个曝光(即曝光不足,中曝光和过度曝光)的LDR序列,该应用程序检测并删除每个镜头中的缺陷像素。在每次曝光下,连续拍摄120到400张图像,以便去噪。一般来说,拍摄次数随着感光度的增加和/或曝光的减少而增加。然后,对这些镜头进行平均,以获得每次曝光的无噪声LDR图像。在获取三次曝光的无噪声LDR帧后,使用[3]中提出的加权函数对它们进行合并,生成高质量的HDR图像GT,记为H。然后分别从捕获的低曝光、中曝光和过曝光的连续LDR图像中提取三个LDR帧,分别记为Lu 、Lm 、Lo ,作为LDR输入,构建LDR-HDR数据对。检查每个序列的质量并丢弃异常值。最后采集到136个静态场景(49个昼景和87个夜景)。
对于前景物体运动的动态场景子集,采用[10]中的策略,利用可控物体来模拟LDR帧之间的运动。该过程如上图所示。首先保持物体静止不动,捕捉三组静态图像,三次曝光,并采用静态场景中应用的方法合成该场景的无噪HDR GT图像H。同时,从静态集中提取一个中等曝光的LDR帧Lm 作为LDR输入之一。然后移动物体和三脚架来捕捉曝光不足的LDR帧Lu 和曝光过度的LDR帧Lo 。最后,取Lu 、Lm 、Lo 和H分别作为LDR输入和HDR GT。最后采集到115个动态场景(15个白天和100个夜间场景)。 上述HDR GT静态和动态场景子集可用于训练HDR重建模型并对其进行定量评价。此外,还捕捉了30个没有HDR GT的场景,这些场景包含手持手机捕捉的不受控制的移动或静态物体,对不同的模型进行定性评估。 下表比较了作者的Mobile-HDR数据集和Sig17数据集[10]的统计数据。可以看到,作者的数据集涵盖了比Sig17数据集更多样化的现实世界场景。与Sig17只包含白天动态场景不同,该数据集涵盖了白天和夜间、动态和静态场景,代表了实际场景中不同的照明条件和不同的噪声水平。此外,该数据集的图像分辨率(一般为4K)远高于Sig17 (1500×1000)。
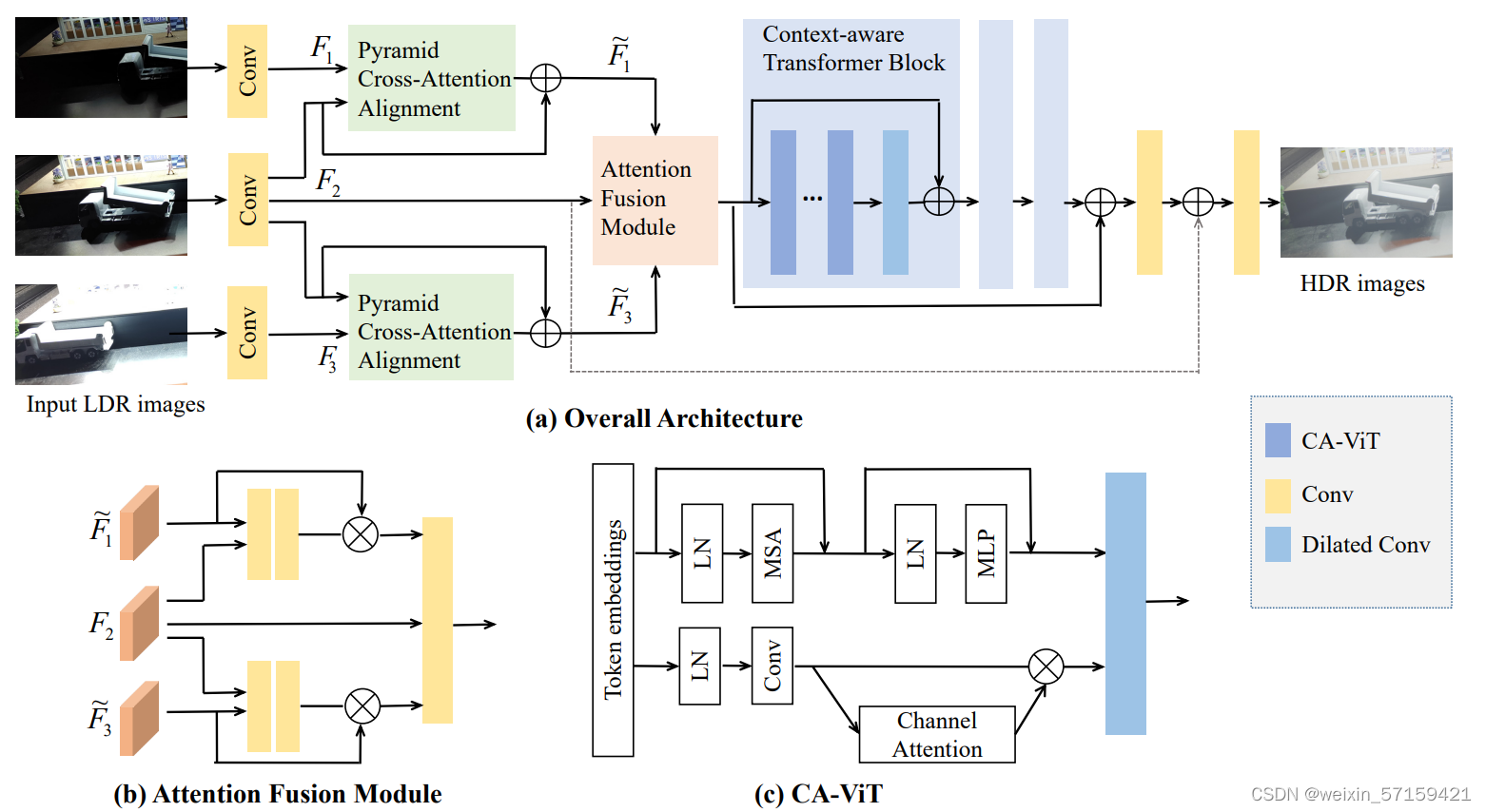
1. 网络架构(Joint-HDRDN) ------ 实现HDR重建+去噪
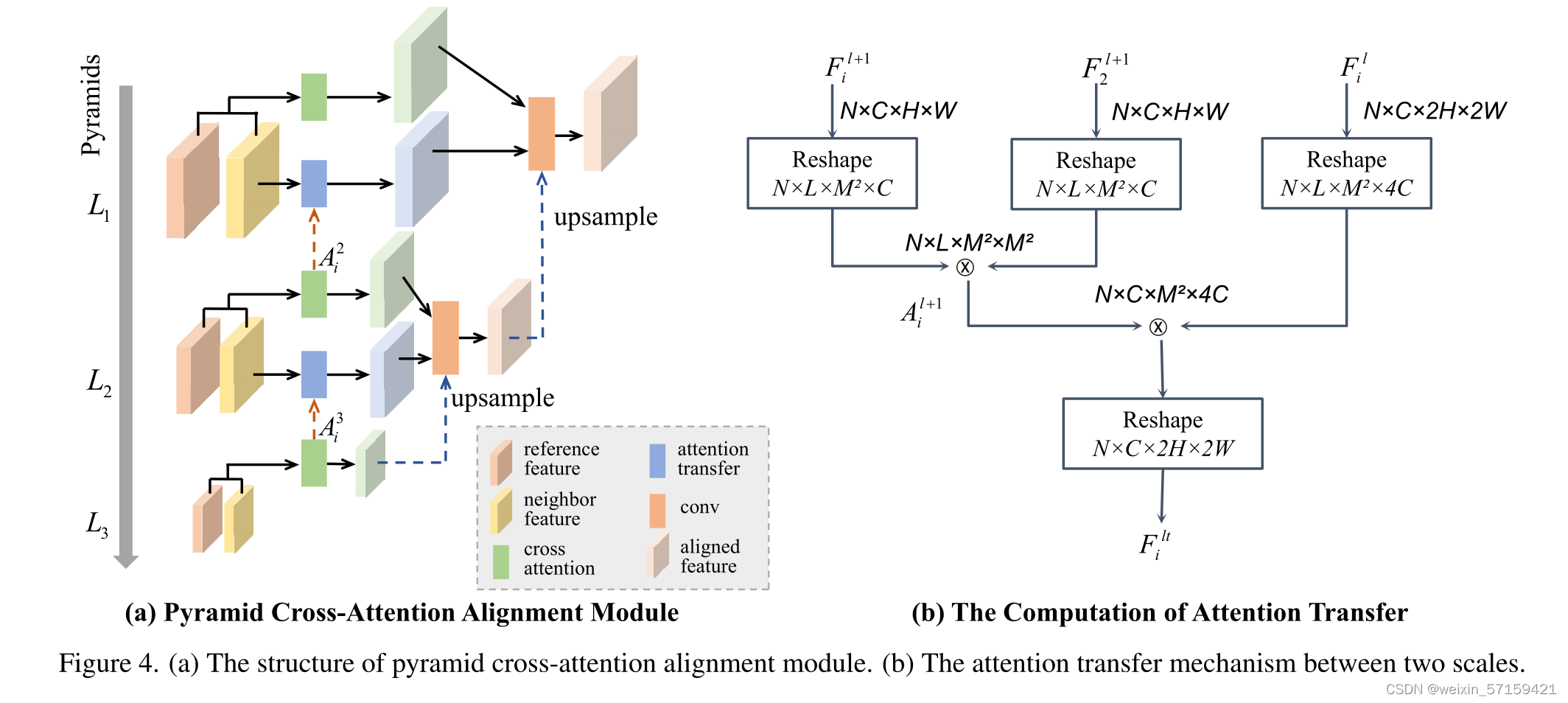
整体结构主要由用于将邻域帧对齐到参考帧的金字塔交叉注意对齐模块、用于融合对齐特征的注意融合模块和用于最终HDR重建的CA-VIT合并子网。给定三幅输入图像,首先通过卷积层提取浅层特征Fi , i=1,2,3 ,然后使用了金字塔交叉注意对齐模块将非参考特征Fi , i=1,3 ,对齐到参考特征F2 。然后将对齐后的特征F1 、F3 和F2 输入注意融合模块得到融合特征。最后将融合特征输入由CA-ViT组成的合并子网生成HDR图像。 2. 金字塔交叉注意对齐模块 ------ 将邻域帧对齐到参考帧+去噪
3. 注意融合模块 ------ 融合对齐特征 在获得对齐后的特征F1 、F3 和F2 后,作者采用AHDRNet[40]中提出的注意力模块(如图b),从未对齐、过度曝光和曝光不足的区域抑制有害特征。 对于来自非参考LDR图像(即F1 和F3 )的每个对齐特征,①首先将其与参考特征F2 连接起来作为两个卷积层的输入,生成一个范围在0到1之间的空间注意图mi , i=1,3 ;②然后执行mi 和Fi 的逐元素乘法,得到关注特征Fi' : Fi'=mi⊙Fi , i=1,3 ;③最后将关注特征F1' 、F3' 和参考特征F2 进行Concat和卷积,得到融合特征。 4. CA-ViT合并子网 ------ 重建最终HDR 在获得融合特征后,作者采用HDR-Transformer[21]中提出的融合子网(如图a),由3个context-aware Transformer block (CTB){包括4个双分支context aware vision Transformer (CA-ViT) (如图c)和一个扩展卷积层}组成,每个CA-ViT采用基于窗口的多头Transformer编码器[20]提取全局信息,并使用具有通道关注的卷积块作为另一个并行分支提取局部信息。 5. 损失函数
其中,
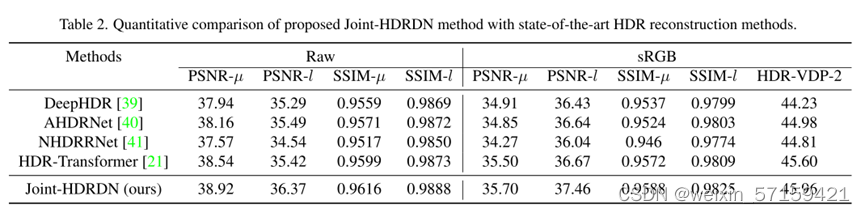
6. 实验与结果 6.1 Comparison with State-of-the-Arts 定量比较:
上表可以看到,基于Transformer的算法优于基于CNN的方法,而作者提出的Joint-HDRDN在Raw域的PSNR-µ和PSNR-l方面超过了HDR-Transformer,这是之前的最先进的方法,分别高达0.38dB和0.95dB。此外,在将图像从Raw域渲染到sRGB域后,提出的模型仍然大大优于其他竞争对手。 定性比较:
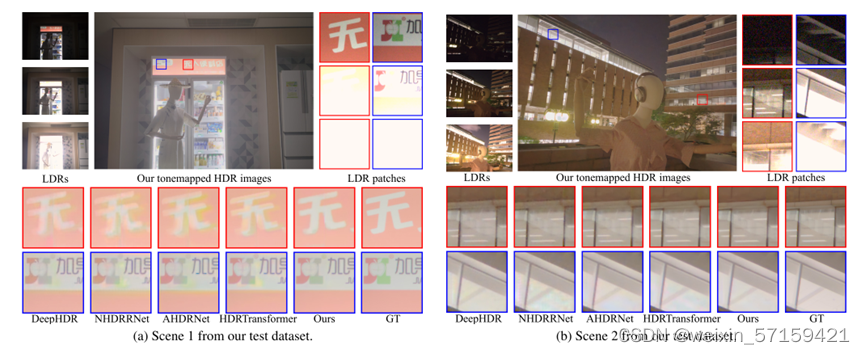
上图可以看到,作者提出的Joint-HDRDN取得了明显更好的视觉效果。对于曝光量大或噪声严重的参考系,该方法可以在不引入过多伪影的情况下恢复出较好的细节。通过比较,其他方法受到重影或残余噪声的影响。以往的方法没有考虑噪声对最终HDR图像质量的影响。同时,他们通常只是通过建模远程依赖来对过度曝光的区域产生合理的内容,通过注意力模块来抑制未对齐的区域,以减轻幽灵伪影。因此,它们不能有效地利用其他帧来恢复细节。此外,由于缺乏特定的对准设计,它们将不可避免地产生重影,特别是对于大的过度曝光区域。相比之下,作者提出的金字塔交叉注意对齐模块更有效地从其他框架中搜索和聚合有益的特征,可以更好地再现细节并消除伪影。 6.2消融实验 训练数据集的消融实验:
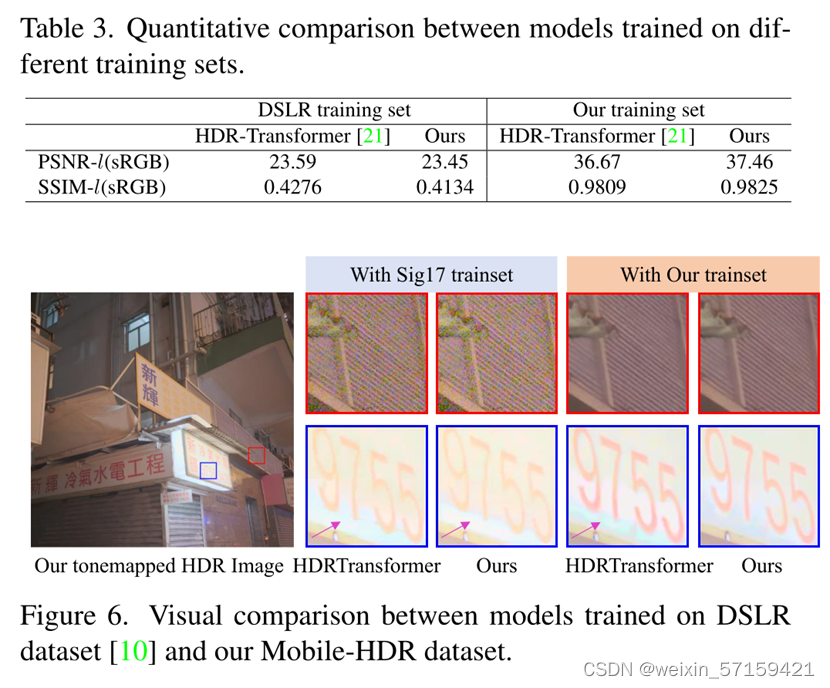
表3的定量结果证明,单反数据集不能很好地支持本研究,手机上的HDR成像主要是因为较小的光圈和传感器尺寸导致手机图像的噪点更强,过曝面积更大。图6的定性结果证明,在单反数据集上训练的模型很难去除手机图像中较重的噪声,过度曝光区域存在明显的鬼影。此外,HDR-Transformer等现有方法并不是为移动HDR成像而设计的。即使在作者的Mobile-HDR数据资产上重新训练,它们仍然在过度曝光的区域显示许多鬼影,在嘈杂的区域显示模糊的细节。因此,有必要构建一个移动HDR图像数据集,以促进对移动HDR成像的研究,如更有效的去噪、对齐、融合以及它们的联合任务。 网络结构的消融实验:
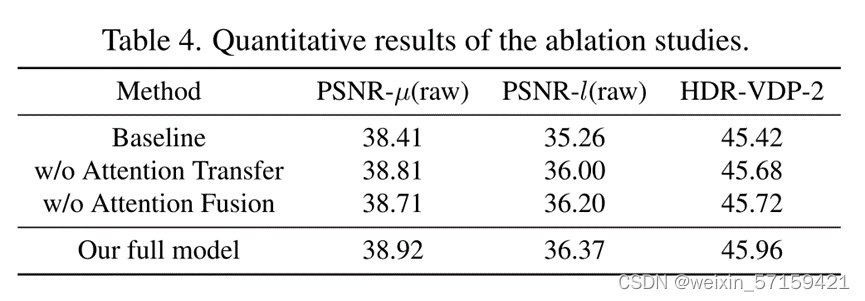
表4列出了网络结构的消融实验的定量结果。与基线模型(与完整模型共享相同的合并网络,但去除了对准模块)相比,完整模型在PSNR-µ和PSNR-l上分别获得了0.51dB和1.11dB的优势,证明了作者提出的金字塔交叉注意对准模块的有效性,提出了一种注意力转移机制,以缓解过度曝光参考区域对准的困难。如表所示,如果将注意力转移机制从对齐模块中移除,PSNR-l的性能将下降0.37dB,验证了注意力转移机制的作用;如果将注意融合模块移除,PSNR-µ的性能将下降0.21dB,验证了注意融合模块的作用。 7. 总结与展望 第一次建立了一个真实的移动HDR图像数据集,即Mobile-HDR,以促进移动HDR成像的研究。与现有的HDR图像数据集大多在白天使用单反相机采集不同,作者的数据集是在不同的光照条件和场景下使用手机相机采集的,包含更强的噪声和更大的过曝区域。作者还开发了一种新的HDR图像重建网络,即Joint-HDRDN,采用了一种新颖的金字塔交叉注意对齐模块来联合进行HDR融合和去噪。大量的实验验证了提出的数据集和模型的有效性。 |


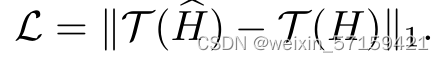
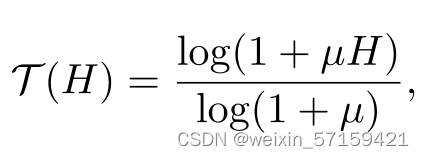
 注:Baseline为HDR-Transformer结构(但具有更少的CA-ViT,12 VS 18)。
注:Baseline为HDR-Transformer结构(但具有更少的CA-ViT,12 VS 18)。【本文地址】