| 《Cython系列》1. Cython 是什么?为什么要有 Cython?为什么我们要用 Cython? | 您所在的位置:网站首页 › lackvumekr是什么 › 《Cython系列》1. Cython 是什么?为什么要有 Cython?为什么我们要用 Cython? |
《Cython系列》1. Cython 是什么?为什么要有 Cython?为什么我们要用 Cython?
|
楔子
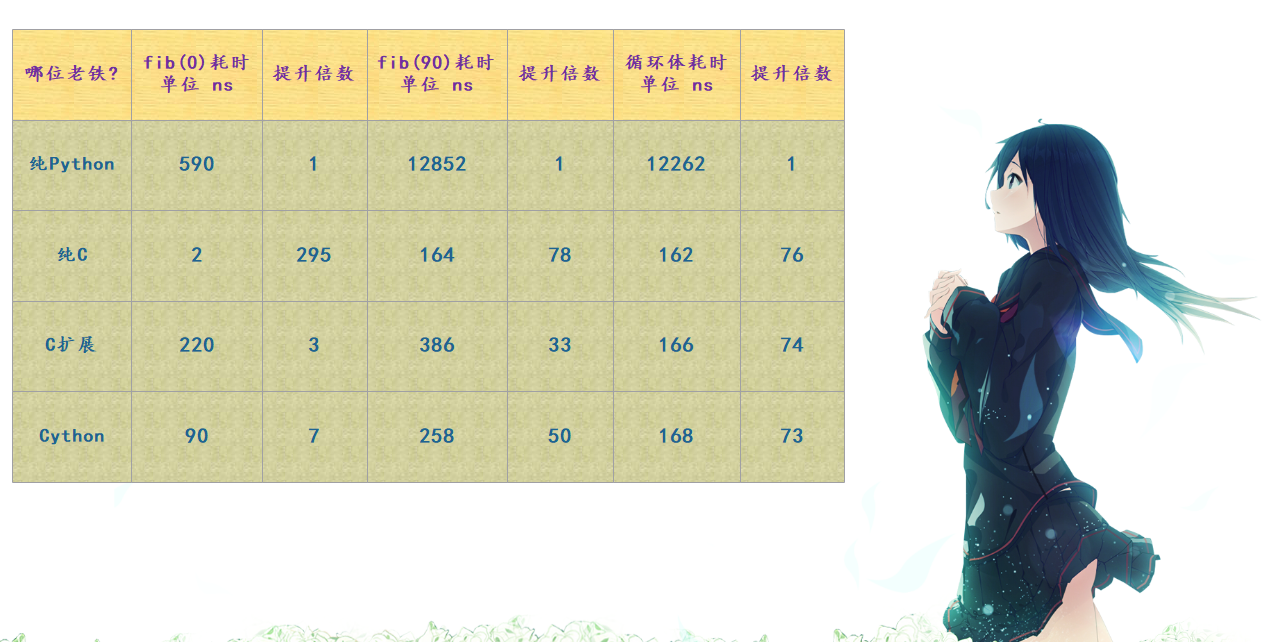
Cython:估计很多人都听说过,是用来对 Python 进行加速的。如果你在使用 Python 编程时,有过如下想法,那么 Cython 非常适合你。 1. 因为某些需求导致不得不编写一些多重嵌套的循环,而这些循环如果用 C 语言来实现会快几百倍,但是不熟悉 C 或者不知道 Python 如何与 C 进行交互。 2. 因为 Python 解释器的性能原因,如果将 CPython 解释器换成 PyPy,或者干脆换一门语言,比如 Julia,将会得到明显的性能提升,可是换不得。因为你的项目组规定只能使用 Python 语言,解释器只能 CPython。 3. Python 是一门动态语言,但你希望至少在数字计算方面,能够加入可选的静态类型,这样可以极大的加速运算效果。因为单纯的数字相加不太需要所谓的动态性,尤其是当你的程序中出现了大量的计算逻辑时。 4. 对于一些计算密集型的部分,你希望能够写出一些超越 Numpy、Scipy、Pandas 的算法。 5. 你有一些已经用 C、C++ 实现的库,你想直接在 Python 内部更好地调用它们,并且不使用 ctypes、cffi 等模块。 6. 也许你听说过 Python 和 C 可以无缝结合,通过 C 来为 Python 编写扩展模块,将 Python 代码中性能关键的部分使用 C 进行重写,来达到提升性能的效果。但是这需要你对 Python 解释器有很深的了解,熟悉底层的 Python/C API,而这是一件非常痛苦的事情。 如果你有过上面的一些想法,那证明你的 Python 水平是很优秀的,然而这些问题总归是要解决的,于是 Cython 便闪亮登场了。注意:Cython 并不是一个什么实验性的项目,它出现的时间已经不短了,并且在生产环境中久经考验,我们完全是有理由学习它的。 下面让我们开始 Cython 的学习之旅吧,最终不管效果如何,逼格要到位。至少我觉得用 Cython 还是很酷的,它的语法我特别特别喜欢,当然它也确实起到了加速的效果。 关于 Cython关于 Cython,你必须要清楚两件事: 1. Cython 是一门编程语言,它将 C、C++ 的静态类型系统融合在了 Python 身上。 补充:没错,Cython 是一门编程语言,文件的后缀是 .pyx,它是 Python 的一个超集;语法是 Python 语法和 C 语法的混血,当然我们说它是 Python 的一个超集,因此你写纯 Python 代码也是可以的。 2. cython 是一个编译器,负责将 Cython 源代码翻译成高效的 C 或者 C++ 源代码;Cython 源文件被编译之后的最终形式可以是 Python 的扩展模块(.pyd),也可以是一个独立的可执行文件。 因此 Cython 的强大之处就在于它将 Python 和 C 结合了起来,可以让你像写 Python 代码一样的同时还可以获得 C 的高效率;所以我们看到 Cython 相当于是高级语言 Python 和低级语言 C 之间的一个融合,因此有人也称 Cython 是 "克里奥尔编程语言"(creole programming language)。 补充:克里奥尔人是居住在西印度群岛的欧洲人和非洲人的混血儿,以此来形容 Cython 也类似于是一个(Python 和 C 的)混血儿。 但是 Python 和 C 系语言大相径庭,为什么要将它们融合在一起呢?答案是:因为这两者并不是对立的,而是互补的。Python 是高阶语言、动态、易于学习,并且灵活。但是这些优秀的特性是需要付出代价的,因为Python的动态性、以及它是解释型语言,导致其运行效率比静态编译型语言慢了好几个数量级。 而 C 语言是最古老的静态编译型语言之一,并且至今也被广泛使用。从时间来算的话,其编译器已有将近半个世纪的历史,在性能上做了足够的优化,因此 C 语言是非常低级、同时又非常强大的。然而不同于 Python 的是,C 语言没有提供保护措施(没有 GC、容易内存泄露),以及使用起来很不方便。 所以两个语言都是主流语言,只是特性不同使得它们被应用在了不同的领域。而Cython 的美丽之处就在于:它将 Python 语言丰富的表达能力、动态机制和 C 语言的高性能汇聚在了一起,并且代码写起来仍然像写 Python 一样。 注意:除了极少数的例外,Python代码(2.x和3.x版本)已经是有效的Cython 代码,因为 Cython 可以看成是 Python 的超集。并且 Cython 在 Python 语言的基础上添加了一些少量的关键字来更好的开发 C 的类型系统,从而允许 cython 编译器生成高效的 C 代码。如果你已经知道 Python 并且对 C 或 C++ 有一定的基础了解,那么你可以直接学习 Cython,无需再学习其它的接口语言。 另外,我们其实可以将 Cython 当成两个身份来看待:如果将 Python 编译成 C,那么可以看成 Cython 的 '阴';如果将 Python 作为胶水连接 C 或者 C++,那么可以看成是 Cython 的 '阳'。我们可以从需要高性能的 Python 代码开始,也可以从需要一个优化的 Python 接口的 C、C++ 开始,而我们这里是为了学习 Cython,因此显然是选择前者。为了加速 Python 代码,Cython 将使用可选的静态类型声明并通过算法来实现大量的性能提升,尤其是静态类型系统,这是实现高性能的关键。 Cython 和 CPython 的区别关于 Cython,最让人困惑的就是它和 CPython 之间的关系(尤其是少了的那个字母 P),但是需要强调的是这两者是完全不同的。 首先 Python 是一门语言,它有自己的语法规则。我们按照 Python 语言规定的语法规则编写的代码就是 Python 源代码,但是源代码只是一个或多个普通的文本文件,我们需要使用 Python 语言对应的解释器来执行它。 而 Python 解释器也会按照同样的语法规则来对我们编写的 Python 源代码进行分词、语法解析等等,如果我们编写的代码不符合 Python 的语法规则,那么会报出语法错误,也就是 SyntaxError。如果符合语法规范的话,那么会顺利的生成抽象语法树(Abstract Syntax Tree,简称AST),然后将 AST 编译成指令集合,也就是所谓的字节码(bytes code),最后再执行字节码。 所以我们看到 Python 源代码是需要 Python 解释器来操作的,我们想做一些事情的话,如果光写成源代码是不行的,必须要由 Python 解释器将我们的代码解释成机器可以识别的指令进行执行才可以。而 CPython 正是 Python 语言对应的解释器,并且它也是官方实现的标准解释器,同时还是是使用最广泛的一种解释器。基本上我们使用的解释器都是 CPython,也就是从官网下载、然后安装之后所得到的。 标准解释器 CPython 是由 C 语言实现的,除了 CPython 之外还有 Jython(java实现的 Python 解释器)、PyPy(Python 语言实现的 Python 解释器)等等。总之设计出一门语言,还要有相应的解释器才可以;至于编译型语言,则是对应的编译器。 最后重点来了,我们说 CPython 解释器是由 C 实现的,它给 Python 语言提供了 C 级别的接口,也就是熟知的 Python/C API。比如:Python 中的列表,底层对应的是 PyListObject;字典则对应 PyDictObject,等等等等。所以当我们在Python中创建一个列表,那么 CPython 在执行的时候,就会在底层创建一个 PyListObject。因为 CPython 是用C来实现的,最终肯定是将 Python 代码翻译成 C 级别的代码,然后再变成机器码交给 CPU 执行。而 Cython 也是如此,Cython 代码也是要被翻译成 C 代码的,而实现这一点的就是 cython 编译器(本质上是一个第三方模块,所以同样依赖于 CPython)。因此 Cython 是一门语言,它并不是Python 解释器的另一种实现,它的地位和 CPython 不是等价的,不过和 Python 是平级的。 因此 Cython 是一门语言,可以通过 Cython 源代码生成高效的扩展模块,同样需要 CPython 来进行调用。 比较一下 Python、C、C 扩展、Cython我们以简单的斐波那契数列为例,来测试一下它们执行效率的差异。 先是 Python 代码: def fib(n): a, b = 0.0, 1.0 for i in range(n): a, b = a + b, a return a正如上面提到的那样,Python 函数是一个合法的 Cython 函数,上面的这个函数在 Python 和 Cython 中的表现是完全一致的,我们后面会看看如何使用 Cython 来提升性能。 double cfib(int n) { int i; double a=0.0, b=1.0, tmp; for (i=0; i tp_name); return NULL; } PyObject *z; double a = 0.0, b = 1.0, tmp; int i; for (i = 0; i < PyLong_AsLong(n); i++){ tmp = a; a = a + b; b = tmp; } z = PyFloat_FromDouble(a); return z; }最后来看看如何使用 Cython 来编写斐波那契,你觉得使用 Cython 编写的代码应该是一个什么样子的呢? def fib(int n): cdef int i cdef double a = 0.0, b = 1.0 for i in range(n): a, b = a + b, a return a怎么样,代码和 Python 是不是很相似呢?虽然我们现在还没有正式学习 Cython 的语法,但你也应该能够猜到上面代码的含义是什么。我们使用 cdef 关键字定义了一个 C 级别的变量,并声明了它们的类型。 关键是为什么这样就可以起到加速的效果呢(虽然还没有测试,但速度肯定会提升的,否则就没必要学 Cython 了),和纯 Python 的斐波那契相比,我们看到区别貌似只是事先规定好了变量 i、a、b 的类型而已。但是原因就在这里,因为 Python 中所有的变量都是一个 PyObject *,在底层中就是 C 的一个指针。PyObject(C 的一个结构体)内部有两个成员,分别是 ob_refcnt:保存对象的引用计数、ob_type *:保存对象类型的指针。不管是整型、字符串、元组、字典,亦或是其它的什么,所有指向它们的变量都是一个 PyObject*,当进行操作的时候,首先要通过 -> ob_type 来获取对应的类型的指针,再进行转化。 比如:这里的 a 和 b,我们虽然知道无论进行哪一层循环,结果指向的都是浮点数,但是 Python 解释器不会做这种推断。每一次相加都要进行检测,判断到底是什么类型并进行转化,然后执行加法的时候,再去找内部的 __add__ 方法,将两个对象相加,创建一个新的对象,执行结束后再将这个新对象的指针转成 PyObject *,然后返回。并且 Python 中的对象都是在堆上分配空间,再加上 a 和 b 不可变,所以每一次循环都会创建新的对象,并将之前的对象给回收掉。 以上种种都导致了 Python 代码的执行效率不可能高,虽然 Python 也提供了内存池以及相应的缓存机制,但显然还是架不住效率低。 关于 Cython 为什么能加速,Python为什么慢,我们后面会继续唠叨。 效率差异那么它们之间的效率差异是什么样的呢?我们用一个表格来对比一下:
提升的倍数,指的是相对于纯 Python 来说在效率上提升了多少倍;第二列是fib(0),显然它没有真正进行循环,fib(0) 测量的是调用一个函数所需要花费的开销;而倒数第二列 "循环体耗时" 指的是执行 fib(90) 的时候,排除函数调用本身的开销,也就是执行内部循环体所花费的时间。 整体来看纯 C 语言编写的斐波那契,毫无疑问是最快的,但是这里面有很多值得思考的地方,我们来分析一下。
纯 Python 众望所归,各方面都是表现最差的那一个。从 fib(0) 来看,调用一个函数要花 590 纳秒。和 C 相比慢了这么多,原因就在于 Python 调用一个函数的时候需要创建一个栈帧,而这个栈帧是分配在堆上的,而且结束之后还要涉及栈帧的销毁等等。至于 fib(90),显然无需分析了。 纯 C 显然此时没有和 Python 运行时的交互,因此消耗的性能最小。fib(0) 表明了,C调用一个函数,开销只需要 2 纳秒;fib(90) 则说明执行一个循环,C 比 Python 快了将近80倍。 C 扩展 C 扩展应该都听说过,使用 C 来为 Python 编写扩展模块。我们看一下循环体耗时,发现 C 扩展和纯 C 是差不多的,区别就是函数调用上花的时间比较多。原因就在于我们在调用扩展模块的函数时,需要先将 Python 中的数据转成 C 中的数据,然后在 C 计算斐波那契数列,计算完了再将 C 中的数据转成 Python 中的数据。 所以 C 扩展本质也是 C 语言,只不过在编写的时候遵循 Python 提供的 API 规范,可以将 C 代码编译成 pyd 文件,直接让 Python 来调用。从结果上看,和 Cython 做的事情是比较类似的。但是还是那句话,用 C 写扩展,本质上还是写 C,而且还要熟悉底层的 Python/C API,难度是比较大的。 Cython 单独看循环体耗时的话,我们看到纯 C、C 扩展、Cython 都是差不多的,但是编写 Cython 显然是最方便的。而我们说 Cython 做的事情和 C 扩展本质是类似的,都是为 Python 提供扩展模块,所以对于 Cython 来说,将 Python 的数据转成 C 的数据、进行计算、然后再转成 Python 中的数据返回,这一过程是无可避免的。但是我们看到 Cython 在函数调用时的耗时相比 C 扩展却要少很多,主要是 Cython 生成的C代码是经过高度优化的。不过说实话,函数的调用花的时间根本不需要关心,内部代码块执行所花的时间才是我们应该需要注意的。 Python 的 for 循环为什么这么慢?通过循环体耗时我们看到,Python 的 for 循环真的是出了名的慢,那么原因是什么呢?我们来分析一下。 1. Python 的 for 循环机制 Python 在遍历一个可迭代对象的时候,会先调用这个可迭代对象内部的__iter__ 方法返回其对应的迭代器,然后再不断地调用这个迭代器的 __next__ 方法,将值一个一个的迭代出来,直到迭代器抛出 StopIteration 异常,for循环捕捉,终止循环。而迭代器是有状态的,Python 解释器需要时刻记录迭代器的迭代状态。 2. Python 的算数操作 这一点我们上面其实一定提到过了,Python 由于其动态特性,使得其无法做任何基于类型的优化。比如:循环体中的 a + b,这个 a、b 指向的可以是整数、浮点数、字符串、元组、列表,甚至是我们实现了魔法方法 __add__ 的类的实例对象,等等等等。尽管我们知道是浮点数,但是 Python 不会做这种假设,所以每一次执行 a + b 的时候,都会检测其类型到底是什么?然后判断内部是否有 __add__ 方法,以及两者能不能相加,然后条件满足的话再调用对应的 __add__ 方法,将 a 和 b 作为参数,将 a 和 b 指向的对象进行相加。计算出结果之后,再返回其指针转成 PyObject * 返回。 而对于 C 和 Cython 来说,在创建变量的时候就实现规定了类型。就是这个类型,不是其它的,因此编译之后的 a + b 只是一条简单的机器指令。这对比下来,Python 尼玛能不慢吗。 3. Python中对象的内存分配 我们说 Python 中的对象是分配在堆上面的,因为 Python 中的对象本质上就是 C 中的 malloc 函数为结构体在堆区申请的一块内存。我们知道在堆区进行内存的分配和释放是需要付出很大的代价的,而栈则要小很多,并且它是由操作系统维护的,会自动回收,效率极高。而堆显然没有此待遇,而恰恰 Python 的对象都是分配在堆上的,尽管 Python 引入了内存池机制使得其在一定程度上避免了和操作系统的频繁交互,并且还引入了小整数对象池以及针对字符串的intern机制。但事实上,当涉及到对象(任意对象、包括标量)的创建和销毁时,都会增加动态分配内存、以及 Python 内存子系统的开销。而 float 对象又是不可变的,因此每循环一次都会创建和销毁一次,所以效率依旧是不高的。 而 Cython 分配的变量,这里是 a 和 b,它们就不再是指针了(我们说 Python 中的变量本质上都是一个指针),而是分配在栈上的双精度浮点数。而栈上分配的效率远远高于堆,因此非常适合 for 循环,所以效率要比 Python 高很多。 所以在 for 循环方面,C 和 Cython 要比纯 Python 快了一个数量级以上,这并不是奇怪的事情,因为 Python 每次迭代都要做很多的工作。 需要注意的点我们看到只是在代码中添加了几个 cdef 就能获得如此大的性能改进,显然是非常让人振奋的。但是,并非所有的 Python 代码在使用 Cython 时,都能获得巨大的性能改进。我们这里的斐波那契数列示例是刻意的,因为里面的数据是绑定在 CPU 上的,运行时都花费在处理 CPU 寄存器的一些变量上,而不需要进行数据的移动。如果此函数是内存密集(例如,给两个大数组添加元素)、I/O 密集(例如,从磁盘读取大文件)或网络密集(例如,从 FTP 服务器下载文件),则 Python,C,Cython 之间的差异可能会显著减少(对于存储密集操作)或完全消失(对于 I/O 密集或网络密集操作)。 当提升 Python 程序性能是我们的目标时,Pareto 原则对对我们帮助很大,即:程序百分之 80 的运行耗时是由百分之 20 的代码引起的。但如果不进行仔细的分析,那么是很难找到这百分之 20 的代码的。因此我们在使用 Cython 提升性能之前,分析整体业务逻辑是第一步。 如果我们通过分析之后,确定程序中的瓶颈是由网络 IO 所导致的,那么我们就不能期望 Cython 可以带来显著的性能提升;因此在你使用 Cython 之前,是有必要先确定到底哪种原因导致程序中出现了瓶颈。因此,尽管 Cython 是一个强大的工具,但前提是它必须应用在正确的道路上。 因为 Cython 将 C 的类型系统引入进了 Python,所以 C 的数据类型的限制是我们需要关注的。我们知道,Python 的整数不受长度的限制,但是 C 中 int 和 long 是受到限制的,这意味着它们不能正确地表示无限精度的整数。但幸运的是,Cython 的一些特性可以帮助我们捕获这些溢出。总之最重要的是:C 数据类型的速度比 Python 数据类型快,但是会受到限制导致其不够灵活和通用。 从这里我们也能看出,在速度以及灵活性、通用性上面,Python 选择了后者。 此外,思考一下 Cython 的另一个特性:连接外部代码。假设,我们的起点不是Python 而是 C 或者 C++,我们希望使用 Python 将多个 C 或者 C++ 进行连接。而 Cython 理解 C 和 C++ 的声明,并且它能生成高度优化的代码,因此更适合作为连接的桥梁。 由于我本人是主 Python 的,如果涉及到 C、C++,我们都是介绍如何在 Cython 中引入 C、C++,直接调用已经写好的 C 库;而不会介绍如何在 C、C++ 中引入 Cython,来作为连接多个 C、C++ 模块的桥梁。这一点望理解,因为本人不用 C、C++ 编写服务,只会用它们来辅助 Python 提高效率。 使用 Cython 来包装 C 代码我们之前用 C 实现了一个斐波那契数列,那么我们可以直接在 Cython 中进行调用。下面看看怎么做? // fib.h double cfib(int n); // fib.c double cfib(int n) { int i; double a=0.0, b=1.0, tmp; for (i=0; i |
【本文地址】