| k | 您所在的位置:网站首页 › kmeans算法的过程 › k |
k
|
k-means
K-Means是一种聚类(Clustering)算法,使用它可以为数据分类。K代表你要把数据分为几个组 K-Means算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。 import pandas as pd import numpy as np from pandas import DataFrame,Series from sklearn.cluster import KMeans from sklearn.cluster import Birch from sklearn.manifold import TSNE import matplotlib.pyplot as plt #读取文件 datafile =r'D:\Postgraduate\20220128_20220212\china software cup\tezhnegzhiyuchuli\data\data.csv'#文件所在位置,u为防止路径中有中文名称,此处没有,可以省略 outfile = r'D:\Postgraduate\20220128_20220212\china software cup\tezhnegzhiyuchuli\data\julei_out.xlsx'#设置输出文件的位置 data = pd.read_csv(datafile)#datafile是excel文件,所以用read_excel,如果是csv文件则用read_csv d = DataFrame(data) print(d.head()) #聚类 mod = KMeans(n_clusters=3, max_iter = 500)#聚成3类数据,并发数为4,最大循环次数为500 mod.fit_predict(d)#y_pred表示聚类的结果 #聚成3类数据,统计每个聚类下的数据量,并且求出他们的中心 r1 = pd.Series(mod.labels_).value_counts() r2 = pd.DataFrame(mod.cluster_centers_) r = pd.concat([r2, r1], axis = 1) r.columns = list(d.columns) + [u'类别数目'] print(r) #给每一条数据标注上被分为哪一类 r = pd.concat([d, pd.Series(mod.labels_, index = d.index)], axis = 1) r.columns = list(d.columns) + [u'聚类类别'] print(r.head()) r.to_excel(outfile, index=False)#如果需要保存到本地,就写上这一列 #可视化过程 ''' TSNE的定位是高维数据可视化。对于聚类来说,输入的特征维数是高维的(大于三维), 一般难以直接以原特征对聚类结果进行展示。 而TSNE提供了一种有效的数据降维模式,是一种非线性降维算法 ''' ts = TSNE() ts.fit_transform(r) ts = pd.DataFrame(ts.embedding_, index = r.index) a = ts[r[u'聚类类别'] == 0] plt.plot(a[0], a[1], 'r.') a = ts[r[u'聚类类别'] == 1] plt.plot(a[0], a[1], 'go') a = ts[r[u'聚类类别'] == 2] plt.plot(a[0], a[1], 'b*') plt.show() n_clusters:簇的个数,即你想聚成几类 init: 初始簇中心的获取方法 n_init: 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始10次质心,实现算法,然后返回最好的结果。 max_iter: 最大迭代次数(因为kmeans算法的实现需要迭代) tol: 容忍度,即kmeans运行准则收敛的条件 precompute_distances:是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs*samples 的数量大于12e6 的时候 False,False 时核心实现的方法是利用Cpython 来实现的 verbose: 冗长模式(不太懂是啥意思,反正一般不去改默认值) random_state: 随机生成簇中心的状态条件。 copy_x: 对是否修改数据的一个标记,如果True,即复制了就不会修改数据。bool 在scikit-learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。 n_jobs: 并行设置 algorithm: kmeans的实现算法,有:‘auto’, ‘full’, ‘elkan’, 其中 'full’表示用EM方式实现
|
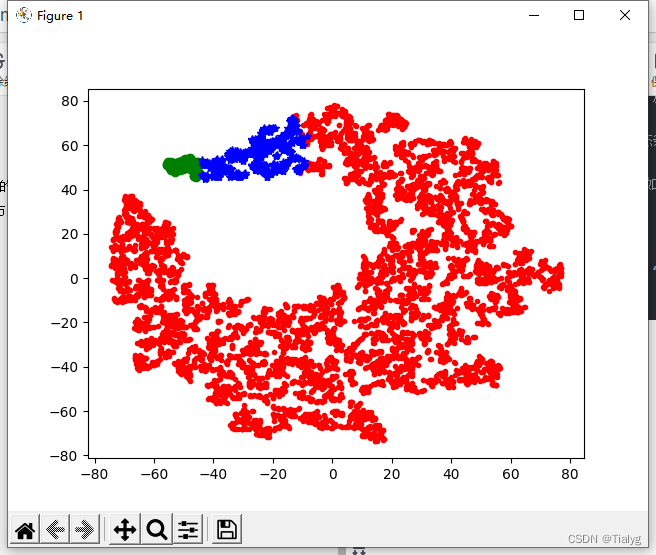
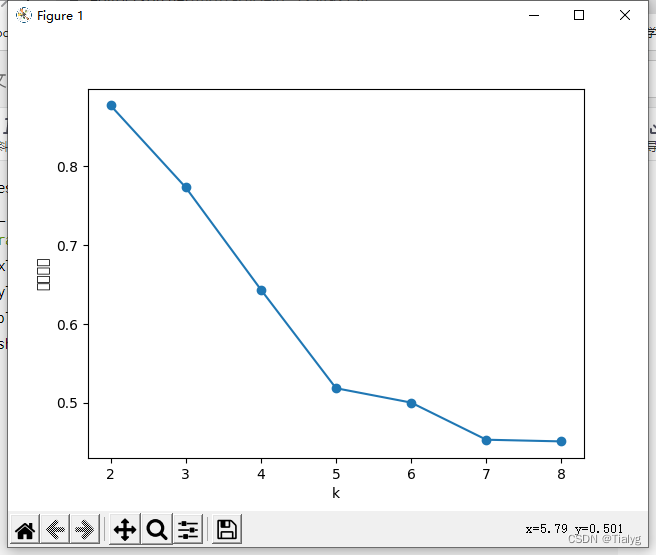 可以看到,轮廓系数最大的k值是2,这表示我们的最佳聚类数为2。但是,值得注意的是,当k取2时,SSE还非常大,所以这是一个不太合理的聚类数,我们退而求其次,考虑轮廓系数第二大的k值3,这时候SSE已经处于一个较低的水平,因此最佳聚类系数应该取3而不是2。
可以看到,轮廓系数最大的k值是2,这表示我们的最佳聚类数为2。但是,值得注意的是,当k取2时,SSE还非常大,所以这是一个不太合理的聚类数,我们退而求其次,考虑轮廓系数第二大的k值3,这时候SSE已经处于一个较低的水平,因此最佳聚类系数应该取3而不是2。【本文地址】
公司简介
联系我们