| flink中消费kafka数据防止乱序 | 您所在的位置:网站首页 › kafka分区顺序性 › flink中消费kafka数据防止乱序 |
flink中消费kafka数据防止乱序
|
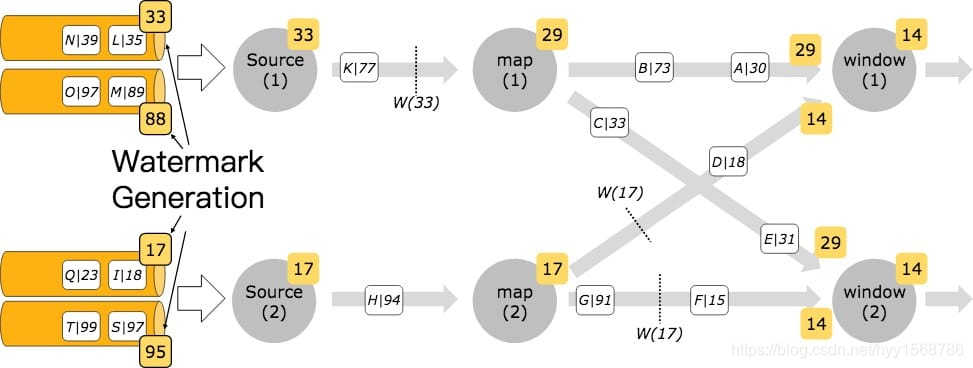
Kafka 分区时间戳 当以 Kafka 来作为数据源的时候,通常每个 Kafka 分区的数据时间戳是递增的(事件是有序的),但是当你作业设置多个并行度的时候,Flink 去消费 Kafka 数据流是并行的,那么并行的去消费 Kafka 分区的数据就会导致打乱原每个分区的数据时间戳的顺序。在这种情况下,你可以使用 Flink 中的 Kafka-partition-aware 特性来生成水印,使用该特性后,水印会在 Kafka 消费端生成,然后每个 Kafka 分区和每个分区上的水印最后的合并方式和水印在数据流 shuffle 过程中的合并方式一致。 如果事件时间戳严格按照每个 Kafka 分区升序,则可以使用前面提到的 AscendingTimestampExtractor 水印生成器来为每个分区生成水印。下面代码教大家如何使用 per-Kafka-partition 来生成水印。 FlinkKafkaConsumer011 kafkaSource = new FlinkKafkaConsumer011("aaa", schema, props); kafkaSource.assignTimestampsAndWatermarks(new AscendingTimestampExtractor() { @Override public long extractAscendingTimestamp(Event event) { return event.eventTimestamp(); } }); DataStream stream = env.addSource(kafkaSource);下图表示水印在 Kafka 分区后如何通过流数据流传播:
 标题
标题
|
【本文地址】
公司简介
联系我们