|
在网上查看了些博客,感觉大家都对数学公式的解释的比较晦涩,下面我结合一个非常简单的示意图解释下他的数学公式,理解不到位的请留言。
kmeans是一种聚类算法下面是算法的描述
给定训练样本是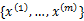 每一个 每一个
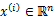 ,即每一个样本元素都是n维向量。为了便于理解在后面的示意图中采用二维的向量。 ,即每一个样本元素都是n维向量。为了便于理解在后面的示意图中采用二维的向量。
step1: 随机选取k个聚类质心点为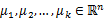
step2: 重复下面过程直到手链
对于每一个样本i计算其应该属于的类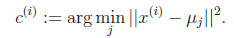
对于每一个类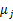 ,重新计算该类的质心 ,重新计算该类的质心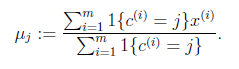
以下是转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006910.html的解释
其中,K是给定的聚类数,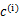 代表样例i与k个类中距离最近的那个类, 代表样例i与k个类中距离最近的那个类,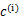 的值是1到k中的一个。质心 的值是1到k中的一个。质心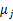 代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为 代表我们对属于同一个类的样本中心点的猜测,拿星团模型来解释就是要将所有的星星聚成k个星团,首先随机选取k个宇宙中的点(或者k个星星)作为k个星团的质心,然后第一步对于每一个星星计算其到k个质心中每一个的距离,然后选取距离最近的那个星团作为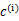 ,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心 ,这样经过第一步每一个星星都有了所属的星团;第二步对于每一个星团,重新计算它的质心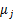 (对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。 (对里面所有的星星坐标求平均)。重复迭代第一步和第二步直到质心不变或者变化很小。
相信到这里很多人看的一头雾水,这里我接着博主的描述再进一步解释。
第一个公式中的arg是标记符号,即表明哪个样本参数属于哪个类用的,后面的紧跟着的min最小化j是我们接下来要说的J这个函数。如下: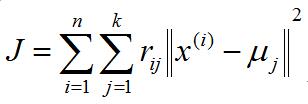 这是kmeans算法中定性描述,公式里面的符号还是上面所说的符号。 这是kmeans算法中定性描述,公式里面的符号还是上面所说的符号。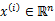 , ,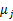 表示第1个样本所属的类别, 表示第1个样本所属的类别,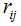 表示数据点x(i)被归类到 的时候为 1 ,否则为 0 。 表示数据点x(i)被归类到 的时候为 1 ,否则为 0 。
下面通过图文来解释这个公式,一直按照流程聚类一个样本相信大家就能很好地理解这个公式表达的意思了
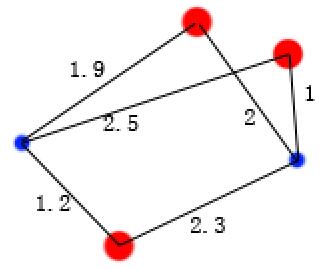
用kmeans算法将三个样本聚类成2类,图中的红点为样本点,蓝点为随即初始的两类的样本点的质心,黑色连线代表每个样本点到某一类质心的距离。J函数最小的意思就是选取这些黑色的距离线使其长度和最小,并且从红点出发的线只能选取一次,即如图中的1.9这条线和2这条线由于都是从同一个红点出发所以只能选取一个进行相加,选取的总线数就是红点的个数,下面两张图分别是多种组合选择的二种选取结果
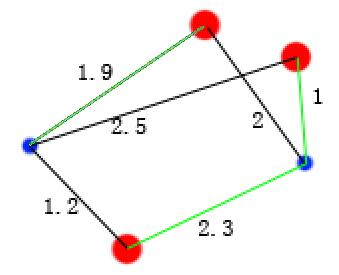
其中绿线为选取的线,他们的和为1.9+2+2.3=6.2
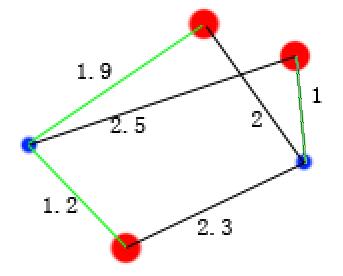
其中绿线为选取的线,他们的和为1.9+1.2+1=4.1
对比上面两张图可以看出,后者的和小,即J值小。这里第二种选取方案也是全局最优选取方案,即所有选取方案中最小的一个。此时,可以把三个点分成两类,如下图 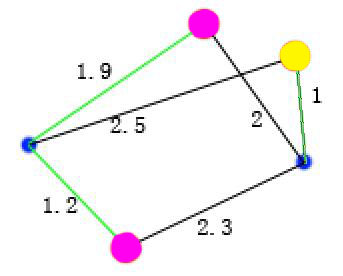 分成2类后再重新计算每类的质心,以及质心到各个样本点的距离,如下图。需要注意的是由于黄色类只有一个样本点,即该类的质点就是该样本点,故其中一个“0”表示质点到该样本点的距离为零。 分成2类后再重新计算每类的质心,以及质心到各个样本点的距离,如下图。需要注意的是由于黄色类只有一个样本点,即该类的质点就是该样本点,故其中一个“0”表示质点到该样本点的距离为零。 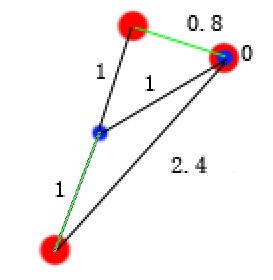 仍然按照,找每个红点到蓝点的一条线的和最小的组合方式,注意每个红点到蓝点的多个距离值只容许一条计算,下图是错误的,其中一个红有两条线参加了计算,1和0.8这两条线只能有一天参与求和。 仍然按照,找每个红点到蓝点的一条线的和最小的组合方式,注意每个红点到蓝点的多个距离值只容许一条计算,下图是错误的,其中一个红有两条线参加了计算,1和0.8这两条线只能有一天参与求和。 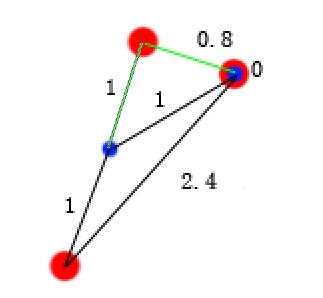 此时,样本被分成新的两类,如下图 此时,样本被分成新的两类,如下图 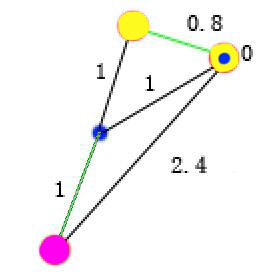 再求新分的两类的质心 再求新分的两类的质心 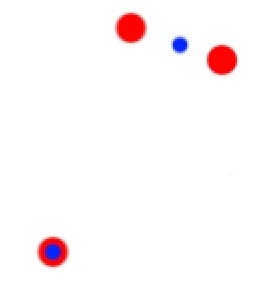 重复以上操作,直到质心不变,即J函数值最小,结束算法。 重复以上操作,直到质心不变,即J函数值最小,结束算法。 
|