| Java IO 之 FileReader 读取文件打印在控制台(处理汉字乱码bug) | 您所在的位置:网站首页 › java读取文件内容到控制台上 › Java IO 之 FileReader 读取文件打印在控制台(处理汉字乱码bug) |
Java IO 之 FileReader 读取文件打印在控制台(处理汉字乱码bug)
|
测试文件IO之FileReader的使用,从自己d盘读取个txt类型的文件,然后打印输出到控制台,附上测试代码。 发现的问题: 测试过程中,中文汉字出现乱码。经调查,知道在电脑新建txt文本,默认是ANSI编码方式。不是utf-8编码方式。所以在FileReader读汉字显示的时候,就乱码了。你把txt文件换成个你写的java文件,当然你的java文件默认是utf-8的就没问题,可以正常打印到控制台上。 为什么乱码: 至于为什么系统默认是utf-8,这个可能和技术进步有关系了。当时utf-8还不是很流行,或者编码格式还没升级到utf-8,可以用System.getProperty()方法,看看自己系统的Java编辑器是不是默认编码是utf-8的。汉字存在电脑上是以二进制01010的形式进行存储的,根据ANSI的编码方式来形成二进制数字,然后存到硬盘上。然后读的时候以utf-8来读的,即根据utf-8这个码表,来根据存储的二进制数字找到数字对应的汉字。2张码表的同一个数字对应的汉字很大概率不一样啦。所以,对不上了,就乱码了。 解决方法; 把新建的txt文件的编码格式给修改成utf-8.然后再测试。
FileReader : 用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。要自己指定这些值,可以先在FileInputStream 上构造一个InputStreamWriter。 默认字符编码,就是自己系统默认编码。System.setProperty()方法,可以得到自己系统的默认编码。(更新:这话,有问题。也不知道当时怎么想的,写的这句话。)现在一般都是utf-8。FileReader 字母意思,读文件,即把文件中的内容读到内存当中。就方向而言是InStream。
FileReader 关于read方法的多个重载的说明: FileReader.read() //一次读一个字符,且会自动往下读 FileReader.read( char cbuf[]) //读字符数据到一个char数组,返回读取字符个数 FileReader.read( char cbuf[], int off, int len) //读字符数据到数组,哪开始把数据写入到数组,多少长度的字符个数 FileReader.read(java.nio.CharBuffer target) //把数据读到这个类型的buffer里面关于read()方法的说明: 方法返回类型为int,当返回-1时,读到文件的末尾。读动作结束。
测试代码: package com.lxk.FileTest; import java.io.FileReader; import java.io.IOException; /** * 读取一个文件,并打印在控制台上。 * (测试代码中并没有正确姿势关闭文件流,释放系统资源。) */ class FileReaderTest { public static void main(String[] args) throws IOException { FileReader fr = new FileReader("d:ss.txt"); char[] buf = new char[1024]; int num; while ((num = fr.read(buf)) != -1) { System.out.print(new String(buf, 0, num)); } fr.close(); } }
上述代码中char数组即缓冲区的大小为什么是1024 一般都是1024的整数倍,1024,是一个单位,一k个字节,那么一个char类型的是2个字节,那么这个数组,一共就是2kb,read方法,就是一直读数据到缓冲数组。直到缓冲空间不够,或者自己读到文件末尾。才停下来。先把数据取出来放到这个2kb的数组中,满了再取出来。对于字符少的,循环一次就可以搞定。
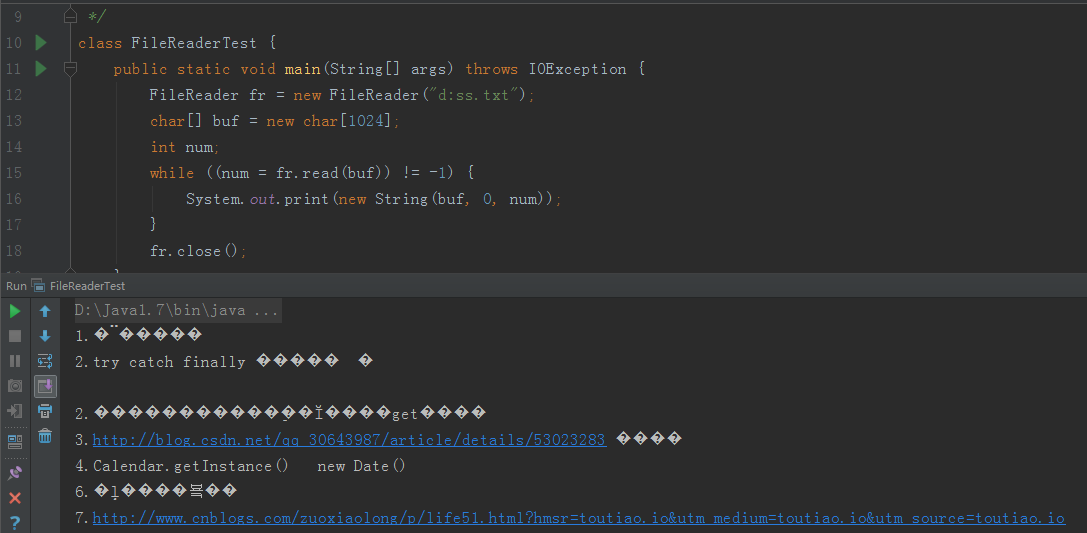
测试乱码结果图:
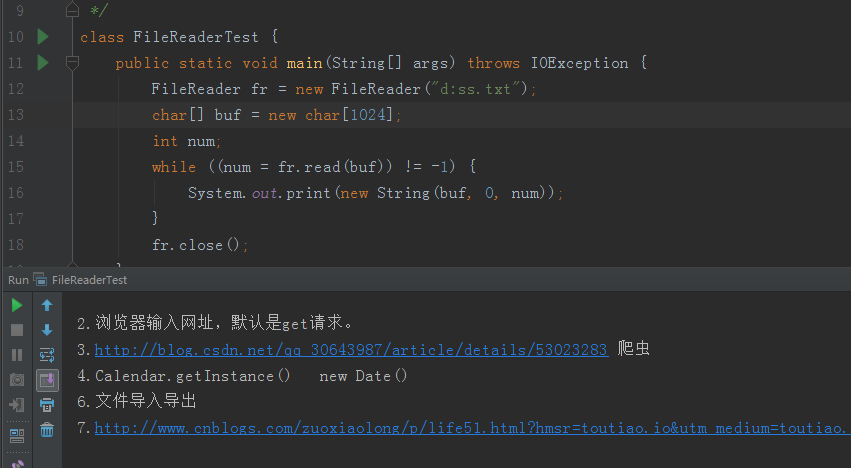
修改新建的txt文件的编码格式之后的正常测试结果图
关于FileReader.read(char cbuf[ ]){ ... }方法的说明。如下。是把数据读到一个数组去。 /** * Reads characters into an array. This method will block until some input * is available, an I/O error occurs, or the end of the stream is reached. * * @param cbuf Destination buffer * * @return The number of characters read, or -1 * if the end of the stream * has been reached * * @exception IOException If an I/O error occurs */ public int read(char cbuf[]) throws IOException { return read(cbuf, 0, cbuf.length); }
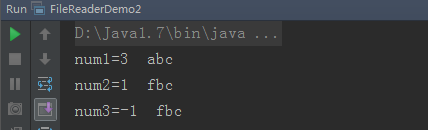
关于FileReader.read( char cbuf[])边界值的测试如下: package com.lxk.FileTest; /* 第二种方式:通过字符数组进行读取。 */ import java.io.*; class FileReaderDemo2 { public static void main(String[] args) throws IOException { //注意下面读的文件内部只写入"abcf"内容来测试边界问题。 FileReader fr = new FileReader("d:demo.java"); //定义一个字符数组。用于存储读到字符。 //该read(char[])返回的是读到字符个数。 char[] buf = new char[3]; int num1 = fr.read(buf); System.out.println("num1=" + num1 + " " + new String(buf)); int num2 = fr.read(buf); System.out.println("num2=" + num2 + " " + new String(buf, 0, num2)); int num3 = fr.read(buf); System.out.println("num3=" + num3 + " " + new String(buf, 0, num3)); fr.close(); } } 奇怪的测试结果图:
关于FileReader.read( char cbuf[])边界值问题的说明。 代码中分三次读取数据到长度为3的char数组里面。三次都用的是同一个数组。方法返回值是每次读取字符的个数。现在来分析每一次的读取。 第一次:因为文件中是"abcf",那么读取三个字符到数组中,那么就是abc被读取出来啦。所以数组中是[abc],且返回的int值为3,即为这一次read读到的字符个数。 第二次:read方法会自动往下读,除非the end of the stream is reached,这次读到f之后,再继续读的时候,发现已经没有了,那么读到的字符个数就是1,然后得到的字符就是f, 但是第二次读数据用的是第一次用过的数组。那么原来数组内部的数据,并没有被清空,那么这个buf数组的下标0处的值被修改了。下标1,2的地方却还是原来第一次读的值。所以数组的内容就是"fbc"。 第三次:第三次的时候,因为第二次已经读到文件末尾了,游标已经是-1啦。那么就不会继续往后移动了,那么再次读的时候,文件内已经没数据了,那么返回的就是-1,那么这个buf数组是三次都公用的,因为这个数组的值,在这次读取的时候,并没有写入新的值,那么返回的还是第二次的结果。那么还是和上一次是一样的咯。
所以应该根据读到的字符的个数来实例化字符串,如下: int num2 = fr.read(buf); System.out.println("num2=" + num2 +" " + new String(buf, 0, num2));
关于FileReader类的整个Java继承关系图,如下:
|
【本文地址】