| Spring Boot + URule 规则引擎,可视化配置太爽了! | 您所在的位置:网站首页 › javalabel里显示所有数据库 › Spring Boot + URule 规则引擎,可视化配置太爽了! |
Spring Boot + URule 规则引擎,可视化配置太爽了!
|
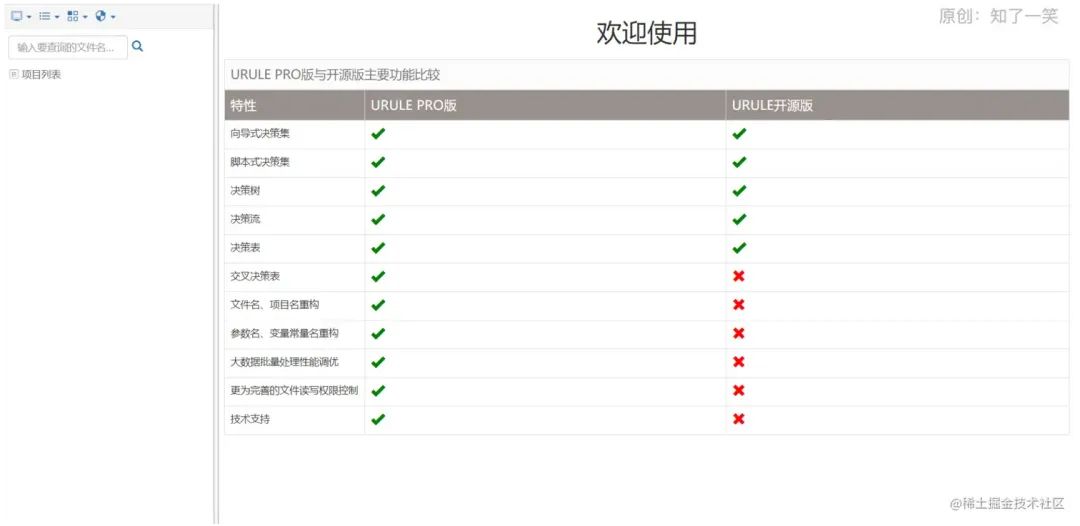
作者:知了一笑 来源:juejin.cn/post/7210194936276680759 一、背景前段时间,在做项目重构的时候,遇到很多地方需要做很多的条件判断。当然可以用很多的if-else判断去解决,但是当时也不清楚怎么回事,就想玩点别的。于是乎,就去调研了规则引擎。 当然,市面上有很多成熟的规则引擎,功能很多,性能很好。但是,就是想玩点不一样的(大家做技术选型别这样,这个是反面教材)。最终一款URule的规则引擎吸引了我,主要还是采用浏览器可直接配置,不需要过多安装,可视化规则也做的不错。经过一系列调研,后面就把它接入了项目中,顺便记录下调研的结果。 二、介绍规则引擎其实是一种组件,它可以嵌入到程序当中。将程序复杂的判断规则从业务代码中剥离出来,使得程序只需要关心自己的业务,而不需要去进行复杂的逻辑判断;简单的理解是规则接受一组输入的数据,通过预定好的规则配置,再输出一组结果。 当然,市面上有很多成熟的规则引擎,如:Drools、Aviator、EasyRules等等。但是URule,它可以运行在Windows、Linux、Unix等各种类型的操作系统之上,采用纯浏览器的编辑模式,不需要安装工具,直接在浏览器上编辑规则和测试规则。 当然这款规则引擎有开源和pro版本的区别,至于pro版是啥,懂的都懂,下面放个表格,了解下具体的区别 特性 PRO版 开源版 向导式决策集 有 有 脚本式决策集 有 有 决策树 有 有 决策流 有 有 决策表 有 有 交叉决策表 有 无 复杂评分卡 有 无 文件名、项目名重构 有 无 参数名、变量常量名重构 有 无 Excel决策表导入 有 无 规则集模版保存与加载 有 无 中文项目名和文件名支持 有 无 服务器推送知识包到客户端功能的支持 有 无 知识包优化与压缩的支持 有 无 客户端服务器模式下大知识包的推拉支持 有 无 规则集中执行组的支持 有 无 规则流中所有节点向导式条件与动作配置的支持 有 无 循环规则多循环单元支持 有 无 循环规则中无条件执行的支持 有 无 导入项目自动重命名功能 有 无 规则树构建优化 有 无 对象查找索引支持 有 无 规则树中短路计算的支持 有 无 规则条件冗余计算缓存支持 有 无 基于方案的批量场景测试功能 有 无 知识包调用监控 有 无 更为完善的文件读写权限控制 有 无 知识包版本控制 有 无 SpringBean及Java类的热部署 有 无 技术支持 有 无 三、安装使用实际使用时,有四种使用URule Pro的方式,分别是嵌入式模式、本地模式、分布式计算模式以及独立服务模式。 但是我们这里不考虑URule Pro,咱自己整个开源版,在开源版集成springboot的基础上做一个二次开发,搜了一圈,其实就有解决方案。 大致的项目模块如下:
Spring Boot 基础就不介绍了,推荐看这个实战项目: https://github.com/javastacks/spring-boot-best-practice 自己创建个空数据库,只需要在edas-rule-server服务中修改下数据库的配置,然后启动服务即可。第一次启动完成,数据库中会创建表。 spring.datasource.type=com.alibaba.druid.pool.DruidDataSource spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/urule-data?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false spring.datasource.username=root spring.datasource.password=mysql上面说过,它是纯用浏览器进行编辑,配置规则的,只需要打开浏览器,输入地址:http://localhost:8090/urule/frame,看到这个界面,就说明启动成功了。
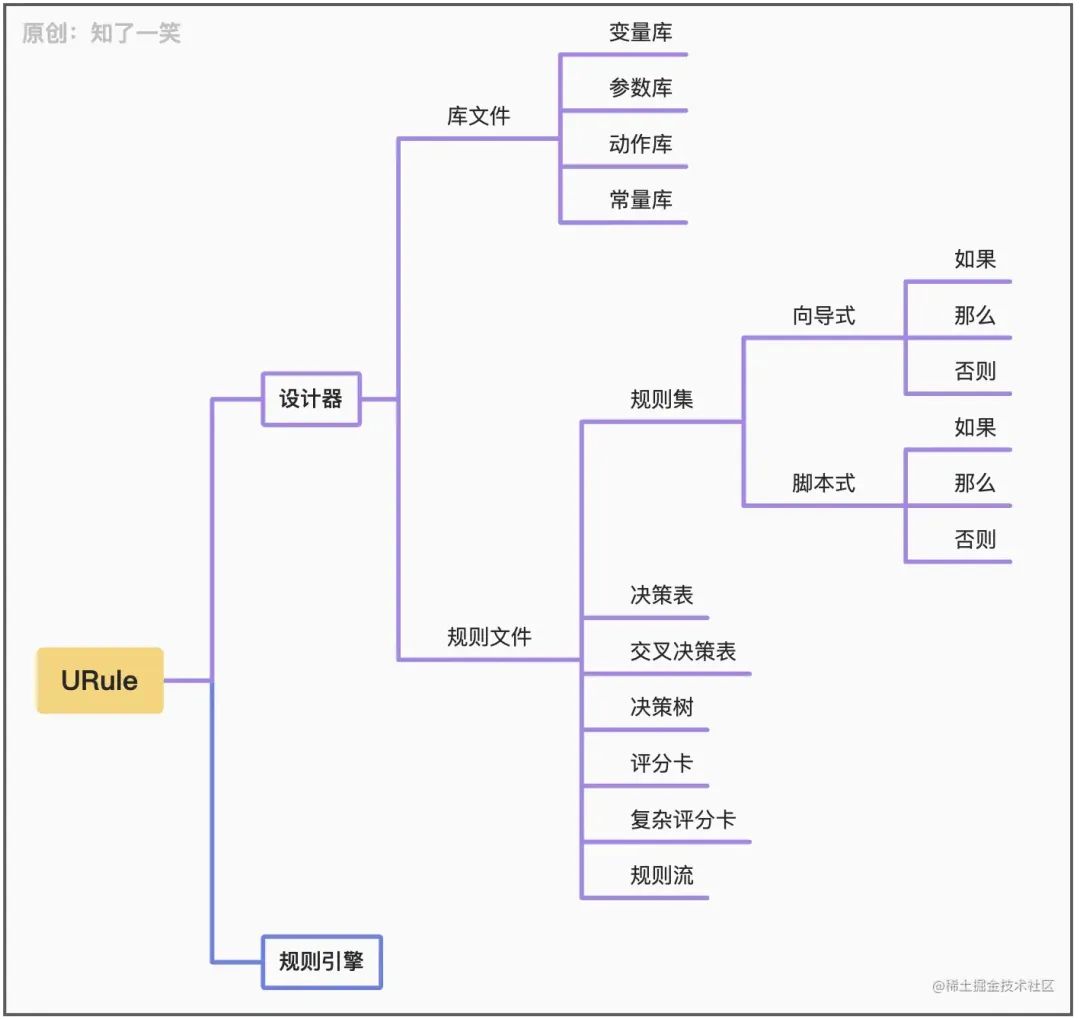
先说下URule它的构成部分,主要是两部分:1、设计器部分 2、规则执行引擎。设计器部分主要是库文件和规则文件构成。下面看下整体的结构图
如上图介绍的,库文件有4种,包括变量库,参数库,常量库和动作库。其实类似于Java开发的系统中的实体对象,枚举,常量以及方法。 上面说过,规则都是可视化配置的。在配置规则的过程中,就需要引入各种已经定义好的库文件,再结合业务需求,从而配置出符合业务场景的业务规则,所以哪里都有库文件的身影。 3.2.1变量库文件在业务开发中,我们会创建很多Getter和Setter的Java类,比如PO、VO、BO、DTO、POJO等等,其实这些类new对象后主要起到的作用就是数据的载体,用来传输数据。 在URule中,变量库就是用来映射这些对象,然后可以在规则中使用,最终完成业务和规则的互动。最后上一张图,用来创建变量库
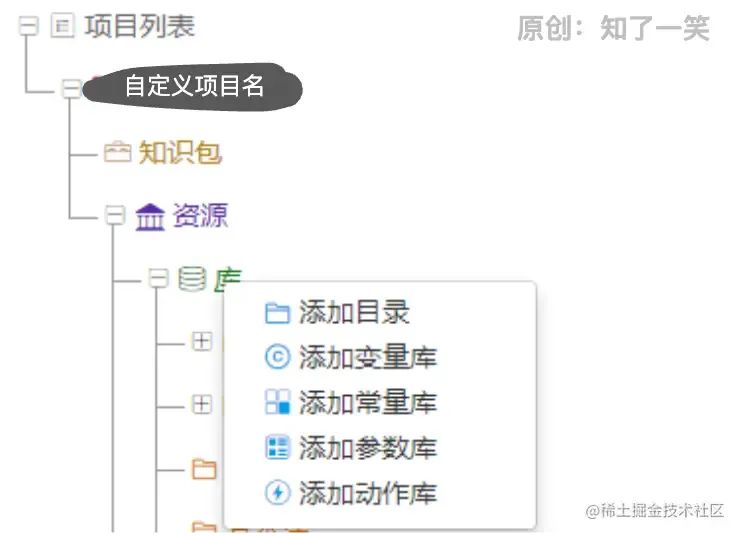
对了,上面废话了这么多可视化配置,这才是第一次展示配置界面,惭愧惭愧。 上图一目了然,在“库”这个菜单底下右键,然后点击添加变量库即可,最后定义自己喜欢的变量库名,当然名字只支持中文或者英文,其他字符不可用。
最后在业务系统中创建对应的类,注意全限定名和配置变量库的类路径一致。 package com.cicada; import com.bstek.urule.model.Label; import lombok.Data; /** * @author 往事如风 * @version 1.0 * @date 2023/3/3 15:38 * @description */ @Data public class Stu { @Label("姓名") private String name; @Label("年龄") private int age; @Label("班级") private String classes; }最后说下这个@Label注解,这个是由URule提供的注解,主要是描述字段的属性,跟变量库的标题一栏一致就行。听官方介绍可以通过这个注解,实现POJO属性和变量库属性映射。就是POJO写好,然后对应规则的变量库就不需要重新写,可以直接生成。反正就有这个功能,这里就直接一笔带过了。 3.2.2常量库文件说到常量库,这个就可以认为是我们Java系统中的常量,枚举。比如性别,要定义枚举吧;比如对接的机构,也可以定义一个枚举吧。 当然,类似于变量库,常量库也可以实现和系统中的枚举相互映射,这样做的好处可以避免我们手动输入,防止输入错误。创建常量库也比较简单,直接在“库”这个菜单下右键,“添加常量库”。 创建好常量库文件后,也会出现如下页面:
参数库,就是URule规则中的临时变量,变量的类型和数量不固定。可以认为类似于Map,实际上存储参数库的也就是个Map。 同样的套路,直接在“库”这个菜单下右键,“添加参数库”。
当然还需要注意的点是,定义的名称要保证唯一,因为Map中的key是唯一的,不然就会存在覆盖的情况。 3.2.4动作库文件动作库可以对配置在spring中的bean方法进行映射,然后可以在规则中直接调用这批方法。惯用套路,还是在“库”菜单下右键,点击“添加动作库”。
最后在动作库页面上添加bean,“Bean Id”一列输入对应的spring bean的名称,这里输入action。然后点击操作列中的小手按钮,就会弹出刚在Action类中标记了ExposeAction注解的方法。选择一个指定的方法添加进来,最后看到方法对应的参数也会被自动加载进去。
最后,变量库、参数库、动作库、常量库这些库文件定义好后,各种规则文件配置的时候就可以导入他们。但是一旦这些库文件被某个规则文件使用,就不要随意修改库文件了。 3.3规则集说到规则集,顾名思义,就是配置规则了。前面定义的库文件就需要导入到规则集中去配置使用。它是使用频率最高的一个业务规则实现方式。 规则集说的是规则的集合,由三个部分规则组成:如果、那么、否则。 在规则集的定义的方式上,URule由向导式和脚本式两种; 向导式规则集:就是在页面上通过鼠标点点点,高度的可视化配置,不是开发都能懂,这也是这个规则引擎的亮点所在。 脚本式规则集:听名字就知道了,这玩意要写脚本的。拉高配置门槛,需要懂点编码的人来编写。 3.3.1向导式规则集还是一样,首先新建。这次是在“决策集”菜单上右键,点击“添加向导式决策集”,这样就创建好一个规则集了。
最后,附上添加完规则后,通过代码去执行规则; package com.cicada; import cn.hutool.core.bean.BeanUtil; import com.Result; import com.bstek.urule.Utils; import com.bstek.urule.runtime.KnowledgePackage; import com.bstek.urule.runtime.KnowledgeSession; import com.bstek.urule.runtime.KnowledgeSessionFactory; import com.bstek.urule.runtime.service.KnowledgeService; import com.cicada.req.StuReq; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.io.IOException; /** * @author 往事如风 * @version 1.0 * @date 2023/3/10 16:47 * @description */ @RestController @RequestMapping("/rule") public class RuleDataController { @PostMapping("/stu") public Result rule(@RequestBody StuReq stuReq) throws IOException { KnowledgeService knowledgeService = (KnowledgeService) Utils.getApplicationContext().getBean(KnowledgeService.BEAN_ID); KnowledgePackage knowledgePackage = knowledgeService.getKnowledge("xxx/xxx"); KnowledgeSession knowledgeSession = KnowledgeSessionFactory.newKnowledgeSession(knowledgePackage); Stu stu = BeanUtil.copyProperties(stuReq, Stu.class); knowledgeSession.insert(stu); knowledgeSession.fireRules(); return Result.success(stu.getTeacher()); } }
脚本式的规则集,各种原理都是和向导式一模一样,无非就是拉高门槛,用写脚本的方式去实现配置的规则。这里不做过多的介绍了。 3.4决策表再聊下决策表,其实它就是规则集的另一种展示形式,比较相对规则集,我更喜欢用决策表去配置规则,应为它呈现的更加直观,更便于理解。但是本质和规则集没啥区别。 也不展开过多的赘述,这里我就放一张配置过的决策表;
当然,还有其他的概念和功能,这里也不一一介绍了,因为上面说的已经是最常用的了,想了解的可以自行去了解。其他功能包括:交叉决策表、评分卡、复杂评分卡、决策树、规则流;当然,其中有些是Pro版的功能。 四、运用场景最近在开发一期大版本的需求,其中就有个场景,具体如下;参与购买订单的用户都会有自己的一个职级,也可以说是角色。每个用户都会有三个职位:普通用户、会员、精英会员。 然后,每个月初都会对用户进行一次晋升处理,普通用户达到要求,就会晋升为会员,会员达到要求就会晋升为精英会员。 当然,普通用户晋升会员,会员晋升精英会员,都会有不同的规则; 普通用户->会员:3个月内帮注册人数达到3人;3个月内自己和底下团队的人,下单金额超过1万;个人的订单继续率超过80%。 会员->精英会员:3个月内帮注册人数达到6人;3个月内自己和底下团队的人,下单金额超过5万;个人的订单继续率超过90%。 不能跨级晋升,普通用户最多只能到会员,达到会员了才能晋升到精英会员。当然,这只是做过简化的一部分需求,我做过稍许的改动,真实的需求场景并没有这么简单。 下面,我对这个需求做一个规则的配置,这里用一个决策表进行配置;在配置规则前,我添加一个变量库文件和常量库;
规则引擎对于我们的系统而言可用可不用,它可以锦上添花,帮助我们剥离出业务中需要进行大量判断的场景。但是,这种规则的剥离,需要我们开发人员对需求进行理解,在理解的基础上进行抽象概念的具化。这,也是整个编程的必经之路。 近期热文推荐: 1.1,000+ 道 Java面试题及答案整理(2022最新版) 2.劲爆!Java 协程要来了。。。 3.Spring Boot 2.x 教程,太全了! 4.别再写满屏的爆爆爆炸类了,试试装饰器模式,这才是优雅的方式!! 5.《Java开发手册(嵩山版)》最新发布,速速下载! 觉得不错,别忘了随手点赞+转发哦! |
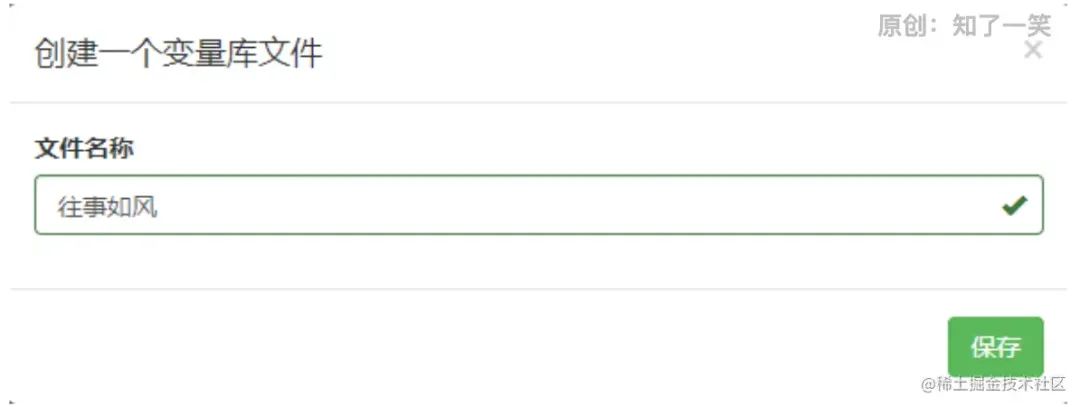 创建完变量库后,就可以对变量库进行编辑,可以认为就是给POJO添加属性
创建完变量库后,就可以对变量库进行编辑,可以认为就是给POJO添加属性 也不弯弯绕绕讲什么术语,就个人理解。图左边是创建类,其中名称是它的别名,配置规则用它代替这个类。图右边是类的属性,我这里随便写了几个,估计看了懂得都懂。
也不弯弯绕绕讲什么术语,就个人理解。图左边是创建类,其中名称是它的别名,配置规则用它代替这个类。图右边是类的属性,我这里随便写了几个,估计看了懂得都懂。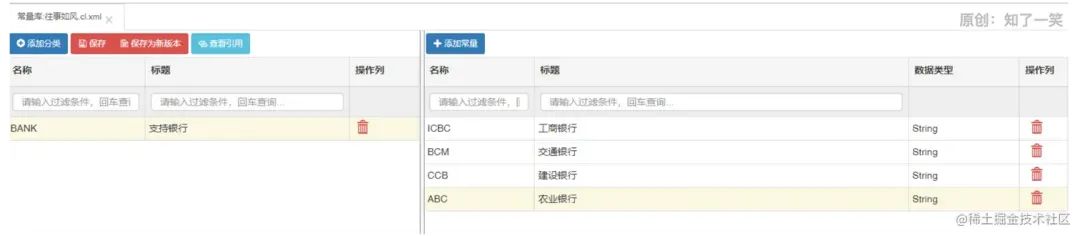
 可以看到,参数库已经少了左边分类这一项,直接添加参数,选择类型就是干,相对简单了很多。“名称”这列我这里用了英文,就是Map中的key,而“标题”这列就是在配置规则时候显示用的,中文看着比较直观。
可以看到,参数库已经少了左边分类这一项,直接添加参数,选择类型就是干,相对简单了很多。“名称”这列我这里用了英文,就是Map中的key,而“标题”这列就是在配置规则时候显示用的,中文看着比较直观。 然后我在系统中添加了一个类Action,然后在类上标记@Component注解,将该类交给spring的bean容器管理。该类中添加一些方法,在方法上标记@ExposeAction注解,该注解是URule定义的,说明被标记的方法都会被动作库读取到。
然后我在系统中添加了一个类Action,然后在类上标记@Component注解,将该类交给spring的bean容器管理。该类中添加一些方法,在方法上标记@ExposeAction注解,该注解是URule定义的,说明被标记的方法都会被动作库读取到。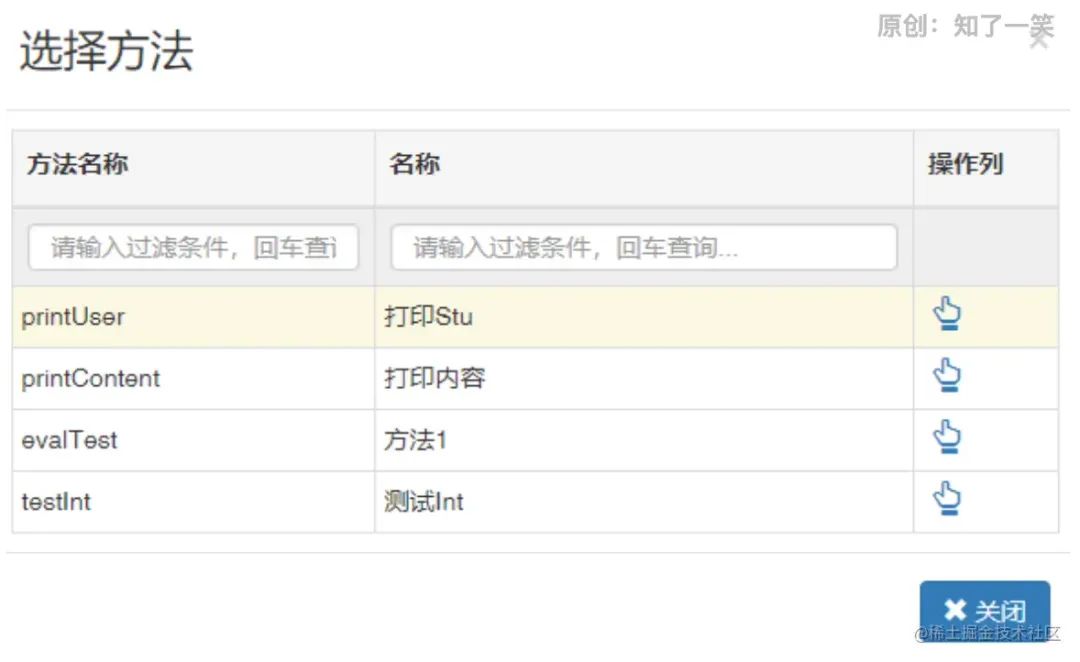

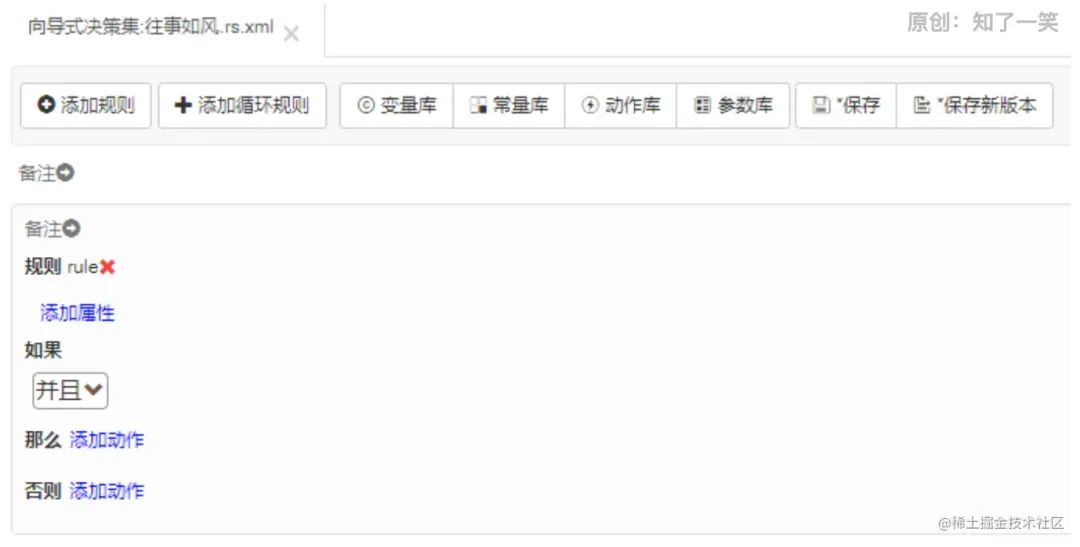 在配置规则前,可以先导入前面定义好的库文件。我这里导入变量库文件,页面上点击“变量库”,然后选择指定的变量库文件即可。如图所示;
在配置规则前,可以先导入前面定义好的库文件。我这里导入变量库文件,页面上点击“变量库”,然后选择指定的变量库文件即可。如图所示;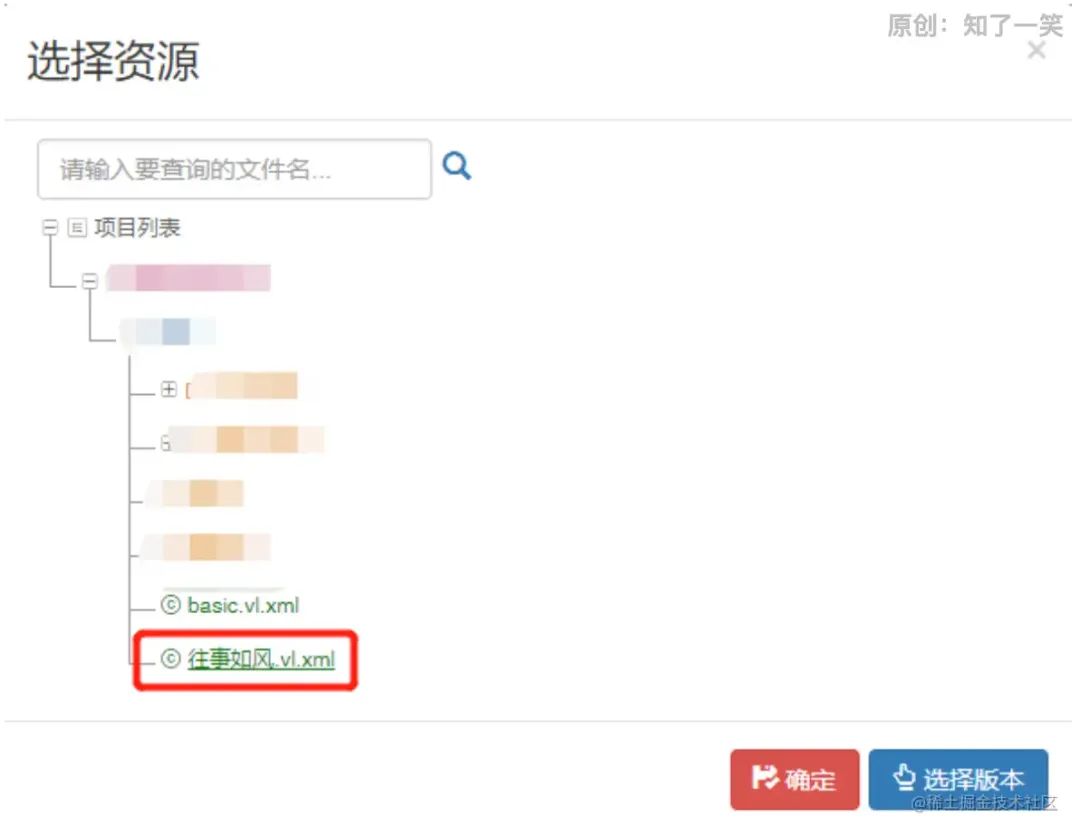 最后,可以愉快的配置规则了,向导式没什么好讲的,都是可视化界面,点点点即可。下面是我配置的一个简单的规则集;
最后,可以愉快的配置规则了,向导式没什么好讲的,都是可视化界面,点点点即可。下面是我配置的一个简单的规则集;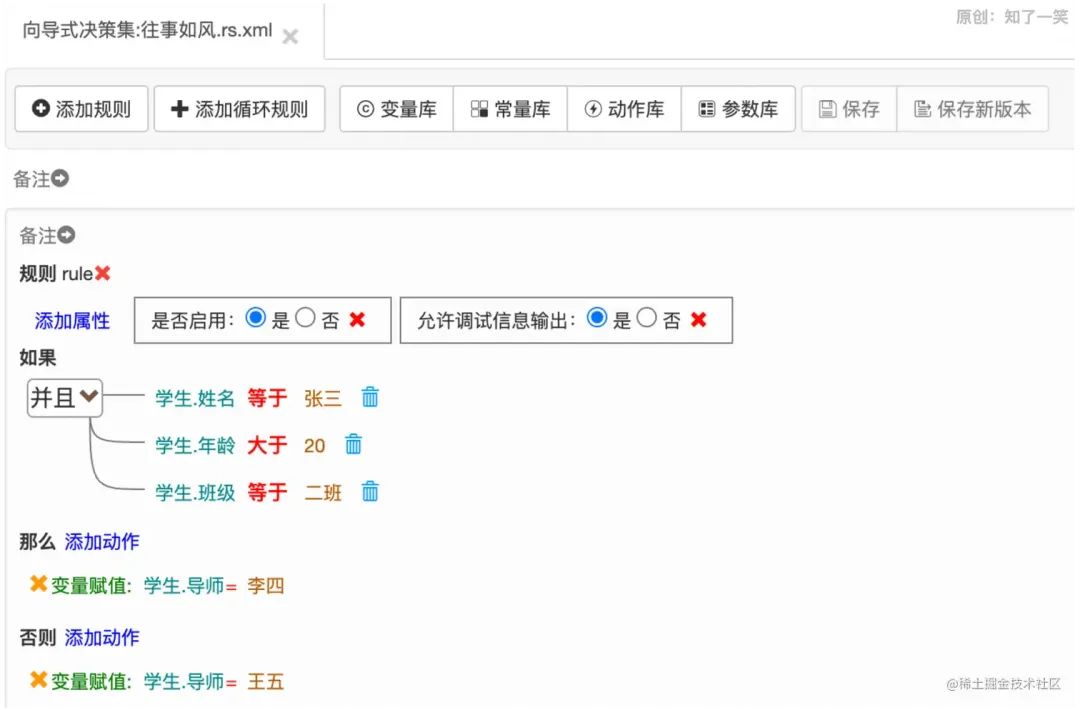 可以看到由三部分组成:如果、那么、否则;
可以看到由三部分组成:如果、那么、否则;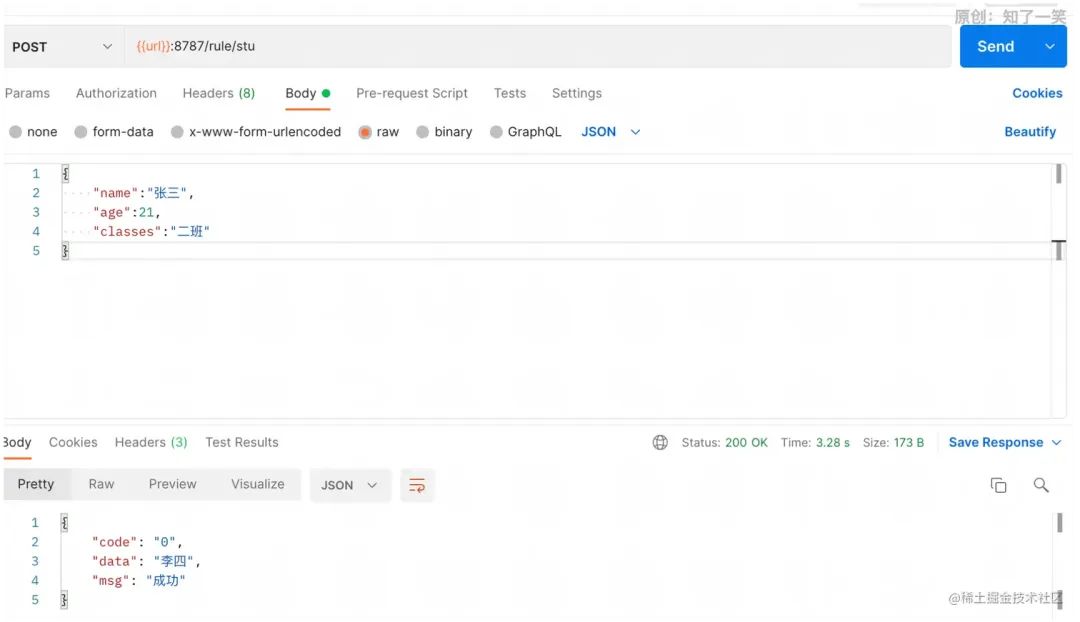 请求接口,最终参数符合配置的条件,返回“那么”中配置的输出结果。
请求接口,最终参数符合配置的条件,返回“那么”中配置的输出结果。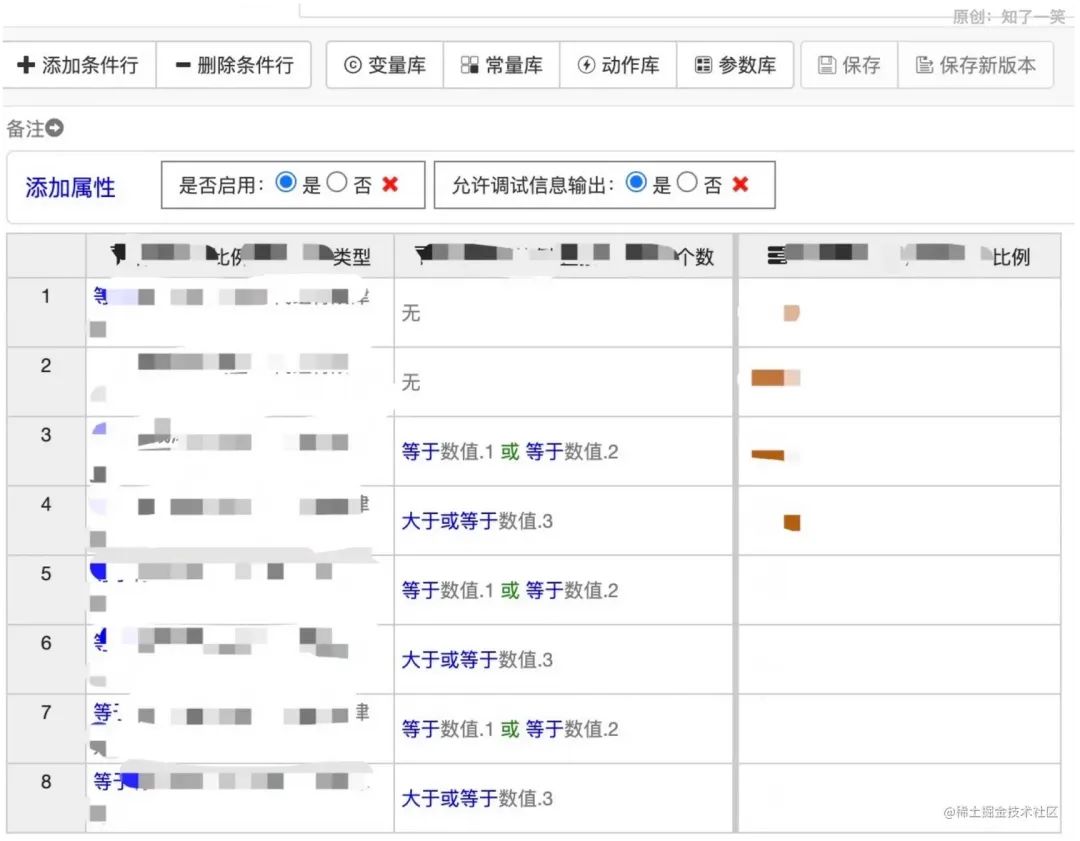
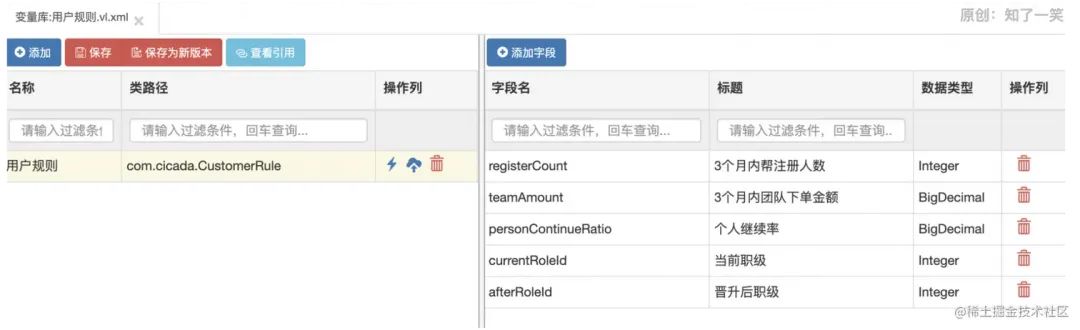
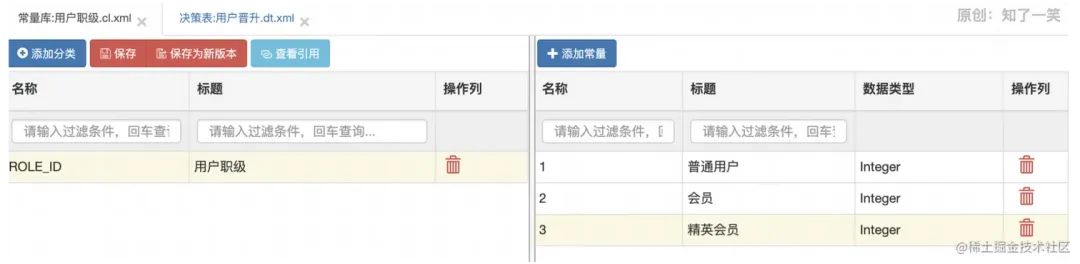 最后,添加一个决策表,并进行规则配置;
最后,添加一个决策表,并进行规则配置;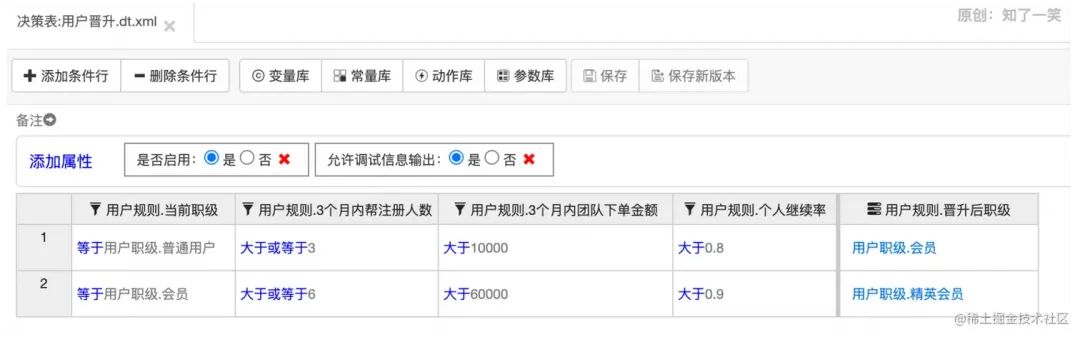 可以看到,表格一共五列,其中前四列是规则,最后一列是满足规则后输出的信息。这样看着就很清晰,即使并不是技术人员,也可以轻松看懂其中的规则。
可以看到,表格一共五列,其中前四列是规则,最后一列是满足规则后输出的信息。这样看着就很清晰,即使并不是技术人员,也可以轻松看懂其中的规则。【本文地址】