| MobileViT: 一种更小,更快,高精度的轻量级Transformer端侧网络架构(附代码实现)... | 您所在的位置:网站首页 › ima架构模型 › MobileViT: 一种更小,更快,高精度的轻量级Transformer端侧网络架构(附代码实现)... |
MobileViT: 一种更小,更快,高精度的轻量级Transformer端侧网络架构(附代码实现)...
|
点击上方,选择星标或置顶,不定期资源大放送 阅读大概需要5分钟 Follow小博主,每天更新前沿干货 【导读】之前详细介绍了轻量级网络架构的开源项目,详情请看深度学习中的轻量级网络架构总结与代码实现,今天将正式开启Transormer轻量级网络架构新篇章,本文将主要介绍一种更小,更快的轻量级Transformer端侧网络架构 ---MobileViT,该网络架构在参数量和精度方面大幅度超过了当前最优的轻量级网络架构(比如Mobile-Former,MobileNetV3等等). MobileViT: 一种更小,更快,高精度的轻量级Transformer端侧网络架构(附代码实现)
论文地址:https://arxiv.org/abs/2110.02178 代码地址:https://github.com/murufeng/awesome_lightweight_networks/blob/main/light_cnns/Transformer/mobile_vit.py Motivation:基于CNN的轻量级网络架构比较适合应用在一些端侧的视觉任务中,由于卷积神经网络利用天然的归纳偏置优势(权重参数共享与平移不变性)来学习视觉表征信息,因此它们只能在空间信息域上建立局部建模依赖关系。 基于自注意力机制的视觉Transformer对输入特征图具备捕捉全局感受野的能力,能在空间维度上建立全局依赖关系从而学习到全局视觉表征信息。但是由于自注意力机制的结构,该网络架构通常具备较大的参数量和计算量。 针对上述两点思考,是否存在一种机制可以有效地结合CNN和ViT两者的优点,从而可以设计一种高效的移动端的网络架构? 本文提出的MobileViT网络架构旨在有效的结合CNN的归纳偏置优势和ViT的全局感受野能力,它是一个轻量级,通用的,低时延的端侧网络架构。首先它利用了CNN中的空间归纳偏置优势以及对数据增强技巧的低敏感性的特性,其次,它结合了ViT中对输入特征图信息进行自适应加权和建立全局依赖关系等优点。具体做法如下: 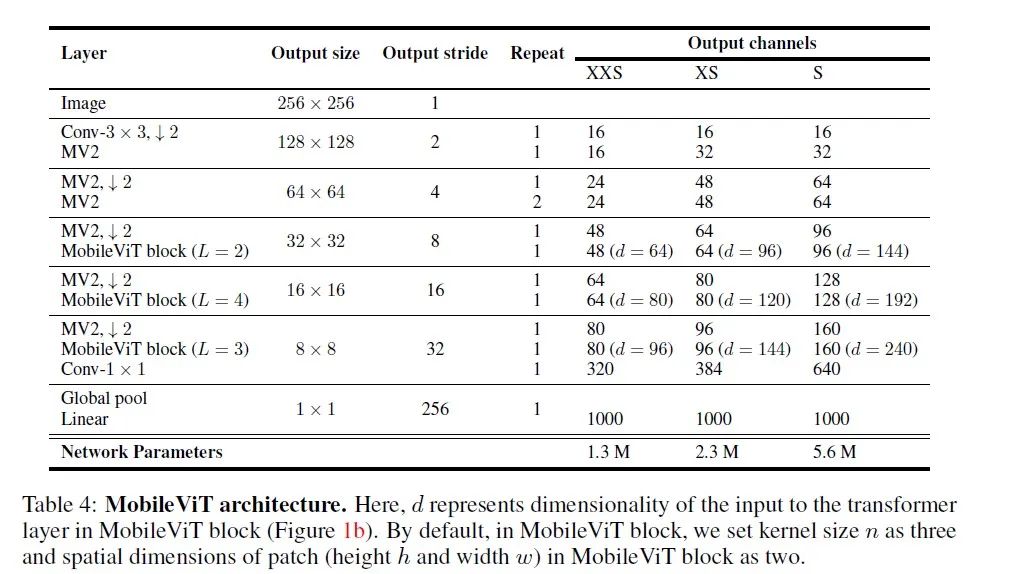
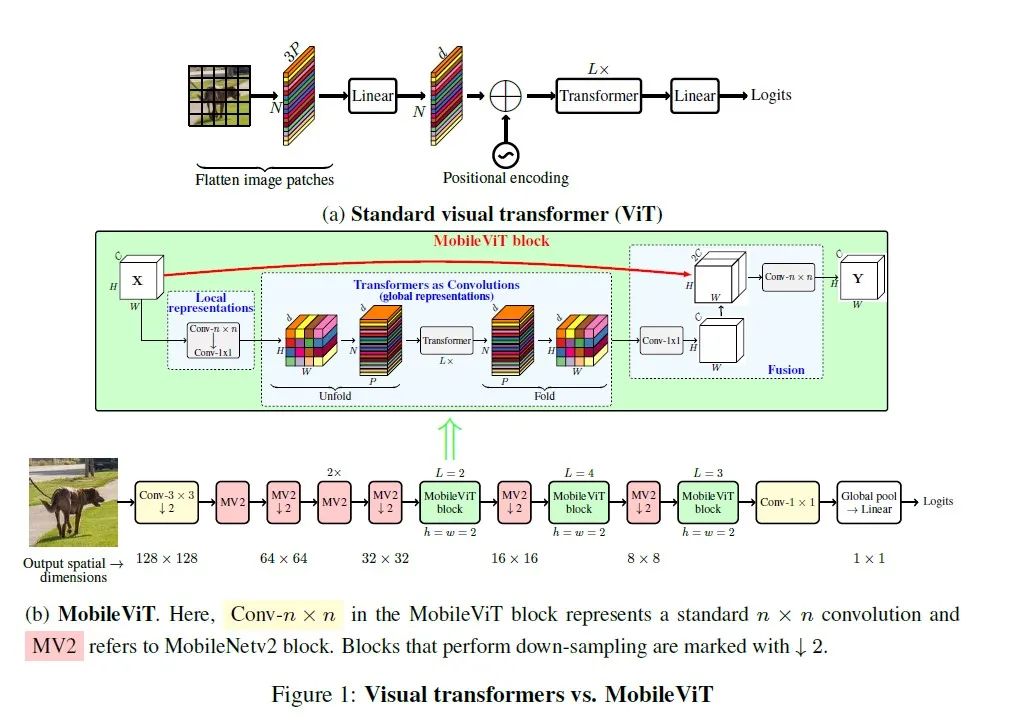
如上图所示,MobileViT主要提出了MobileViT block(如上图1(b)所示), MobileViT块使用标准卷积和Transformer来有效的结合local和global的视觉表征信息。其中标准卷积主要涉及三个操作:展开(unfloading) 、局部处理(local processing) 和展开(folding) 。而Transformer块主要是为了获取得到全局建模依赖关系。这两种方式的巧妙结合可以有效地将局部和全局信息进行编码。以前通常的做法是将patch进行投影,然后用Transformer学习patch之间的全局信息,这就丢失了图像的归纳偏置信息,因此就耗费更多的参数来进行学习,而且最后得到的模型普遍又深又宽。而MobileViT block则既具有卷积的性质,又具备ViT全局建模能力。此外,MobileViT巧妙地结合了mobilenetv2的逆残差模块,再通过有效地设计摆放mbv2 block和MobileViT block的位置顺序,从而实现local与global的视觉表征信息交互。最后将MobileViT 应用在不同的端侧视觉任务(图像分类、物体检测、语义分割)上都取得了比当前轻量级 CNN或ViT模型更好的性能。值得注意的一点:不同于大多数基于ViT的模型,MobileViT模型仅仅使用基础的数据增强训练方式,就达到了更优的性能。 代码实现如下: import torch from light_cnns import mobilevit_s model = mobilevit_s() model.eval() print(model) input = torch.randn(1, 3, 224, 224) y = model(input) print(y.size()) 部分实验结果如下:
后续我们将针对具体视觉任务集成更多的移动端网络架构。希望本项目既能让深度学习初学者快速入门,又能更好地服务科研学术和工业研发社区。 后续将持续更新模型轻量化处理的一系列方法,包括:剪枝,量化,知识蒸馏等等,欢迎大家Star和Follow Github地址:https://github.com/murufeng/awesome_lightweight_networks(欢迎各位轻量级网络科研学者将自己工作的核心代码整理到本项目中,推动科研社区的发展,我们会在readme中注明代码的作者~) 推荐阅读【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载! 一文总结微软研究院Transformer霸榜模型三部曲! Swin Transformer为主干,清华等提出MoBY自监督学习方法,代码已开源 加性注意力机制!清华和MSRA提出Fastformer:又快又好的Transformer新变体! MLP进军下游视觉任务!目标检测与分割领域最新MLP架构研究进展! 周志华教授:如何做研究与写论文?(附完整的PPT全文) 都2021 年了,AI大牛纷纷离职!各家大厂的 AI Lab 现状如何? 常用 Normalization 方法的总结与思考:BN、LN、IN、GN 注意力可以使MLP完全替代CNN吗? 未来有哪些研究方向? 欢迎大家加入DLer-计算机视觉&Transformer群! 大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。 进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)
👆 长按识别,邀请您进群! |
 !
!


【本文地址】