| html中嵌套iframe页面 | 您所在的位置:网站首页 › html中嵌套iframe页面 › html中嵌套iframe页面 |
html中嵌套iframe页面
|
网络爬虫|网页中嵌套iframe框架内容爬取的两种思路
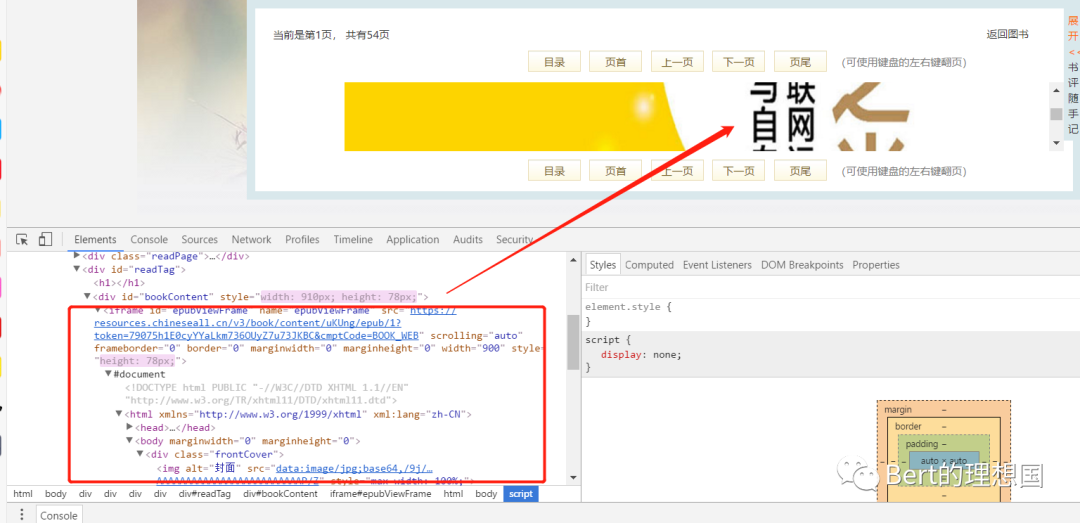
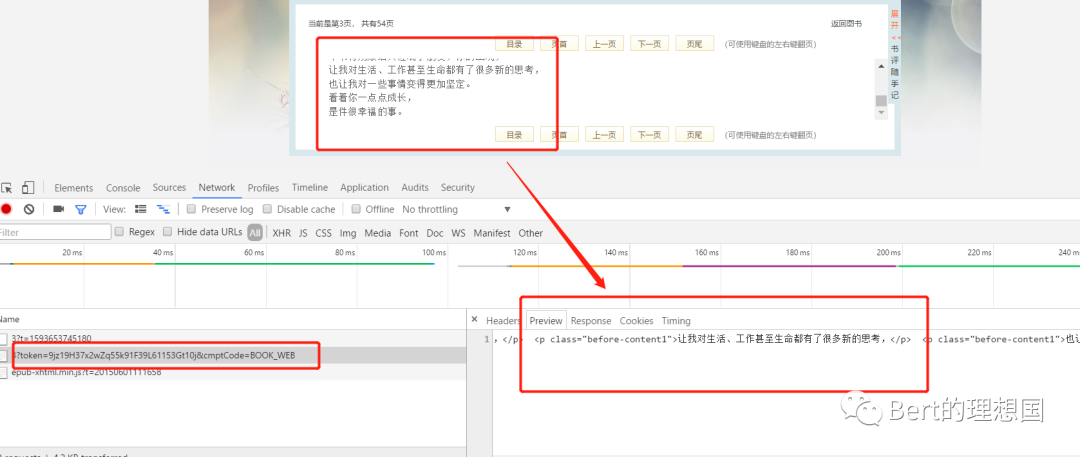
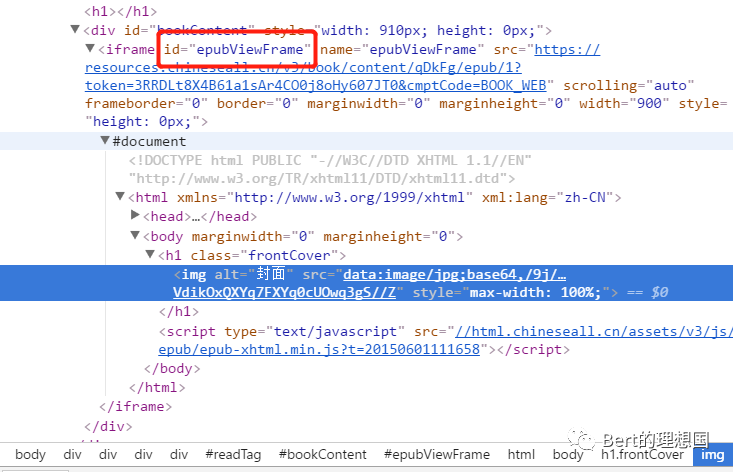
本文只介绍解决相应问题的解决思路,做技术分享,请勿滥用,否则后果自负。 前言 最近在网站看书的时候,遇到了一种iframe嵌套的网站,然后就习惯性的考虑了进行数据获取的时候应该如何解决。 分析 进入网站点击下一页发现地址栏并不发生变化,但是改变地址栏的相应页面数字的时候小说的页数能够随着变化,我觉得很大可能是ajax绑定了数据。之后打开f12审查元素,又打开网页源码进行查看网页源码进行比较,发现f12审查元素中存在一个iframe标签,在这个iframe标签中存在小说相应的数据,如下图:
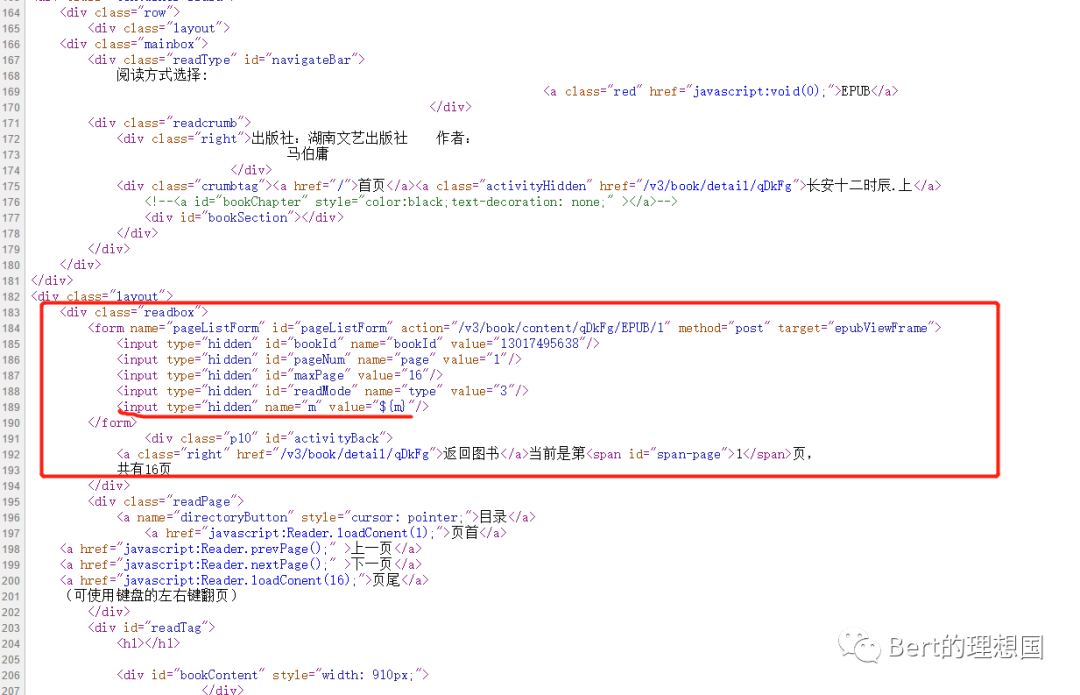
之后查看源码中并不存在iframe相关的内容,只有一个form表单
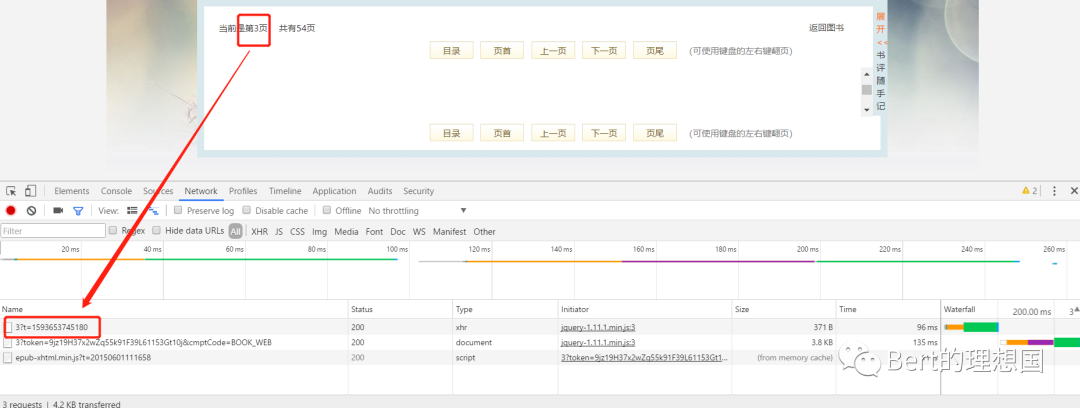
如果在这个状态下直接使用requests请求网址肯定是获取不到任何数据的,因为requests获取到的就是网站的源码。如果图省事的话可以直接考虑使用selenium,只要网站上看得到的都可以使用selenium进行获取,另外也是可以考虑使用requests进行分析network中各个请求进行获取数据。下面从两个角度对该问题进行解决。 思路一:使用requests获取数据 1.分析network 如果直接请求地址栏中的url是不可能获取到小说相关的内容的。因此先从network下手,看看点击下一页之后网站的发起请求的情况。点击下一页之后发现出现三个请求,并且出现了3?t=一串数字
打开第一个文件发现里边的链接恰好就是下一个访问的链接
进入第二个链接发现里边的内容恰好就是小说内容
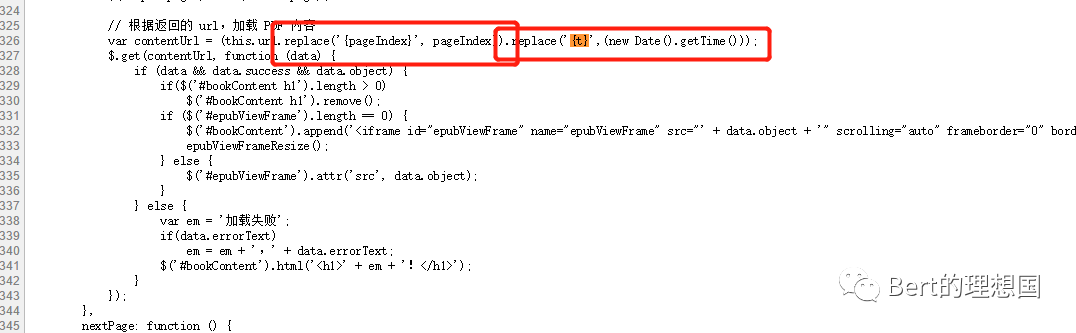
由此可以得出我们只要获取到第一个链接就可以得到小说的内容。 2.分析网页源码中的js部分 从1中我们得出只要能够获得链接1我们就能获取到数据,分析网页源码的目的也就是为了找到构造这个链接的js部分。首先肯定会考虑那个form表单,看看有什么用处,在里边的参数有一个${m}感觉有点像后端的EL表达式,数据是从后端传过来的。此路解决起来可能有点难度,继续看看其他的js方法,发现有一个方法里构造的url和我们在1中发现的第一个url极度相似
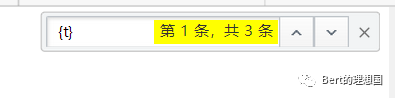
两个参数,一个pageIndex不用说了肯定是页码,但是这个t是什么,然后可以考虑在全局中搜索一下
找到了突破口
{t}仅仅是个字符,被一个方法替换了(new Date().getTime():获取时间戳),看这个方法应该是和时间有关系,那么t应该就是time的意思,然后去在线js执行一下方法
3.构造url进行访问 用上边的时间戳构造url
成功获取到信息
现在url地址栏的信息则为1中的第二个链接
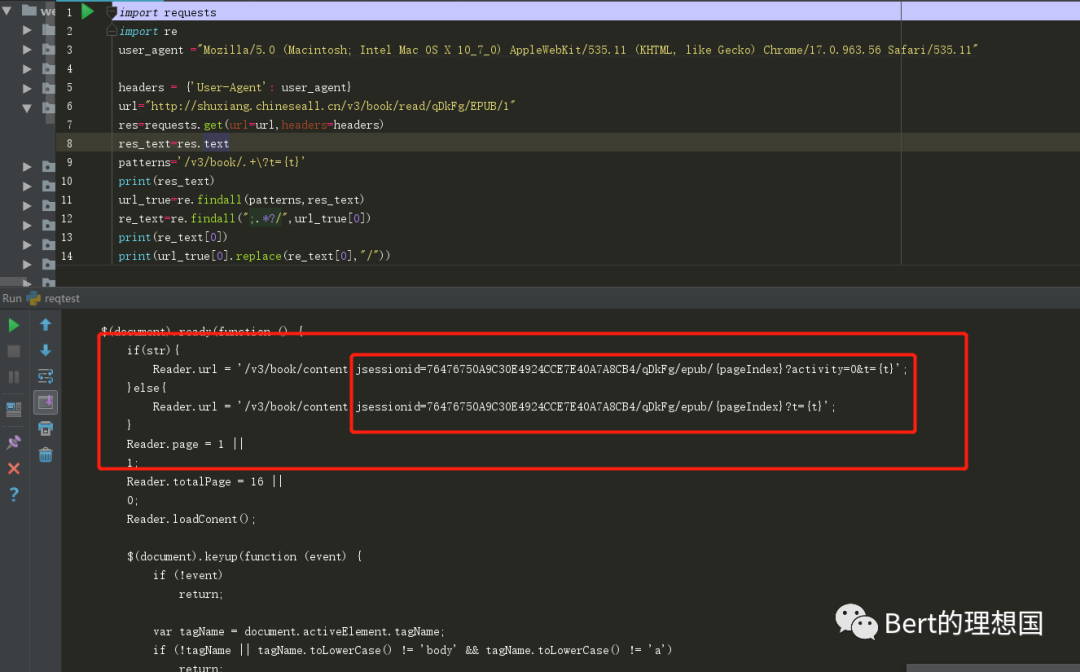
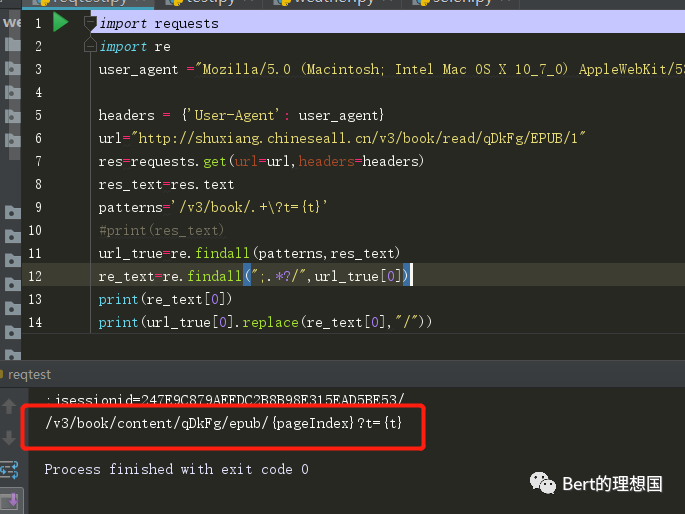
4.正则匹配url 使用requests进行请求的时候,看源码发现那个url与网站源码有些出入,按照requests请求后的源码解决即可。
把中间的jsessionid相关的东西匹配出来之后替换掉
于是就匹配出来了,之后使用replace换成相应的内容就可以了 代码如下: import requestsimport reimport timefrom bs4 import BeautifulSoupuser_agent ="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"headers = {'User-Agent': user_agent}url="http://shuxiang.chineseall.cn/v3/book/read/qDkFg/EPUB/1"res=requests.get(url=url,headers=headers)res_text=res.textpatterns='/v3/book/.+\?t={t}'#Reader Url正则匹配规则url_true=re.findall(patterns,res_text)#对整体进行匹配re_text=re.findall(";.*?/",url_true[0])#匹配出来jsessionidprint(re_text[0])print(url_true[0].replace(re_text[0],"/").replace("{pageIndex}","1").replace("{t}",str(int(time.time()))))#将链接中的jsessionid除去加入pagenumber以及时间戳newurl="http://shuxiang.chineseall.cn"+url_true[0].replace(re_text[0],"/").replace("{pageIndex}","4").replace("{t}",str(int(time.time())))result=requests.get(newurl,headers=headers)print(result.text)soup=BeautifulSoup(result.text,'lxml')print(soup.find_all('p'))运行结果:
思路二:使用selenium获取数据 1.找到iframe的class或者id
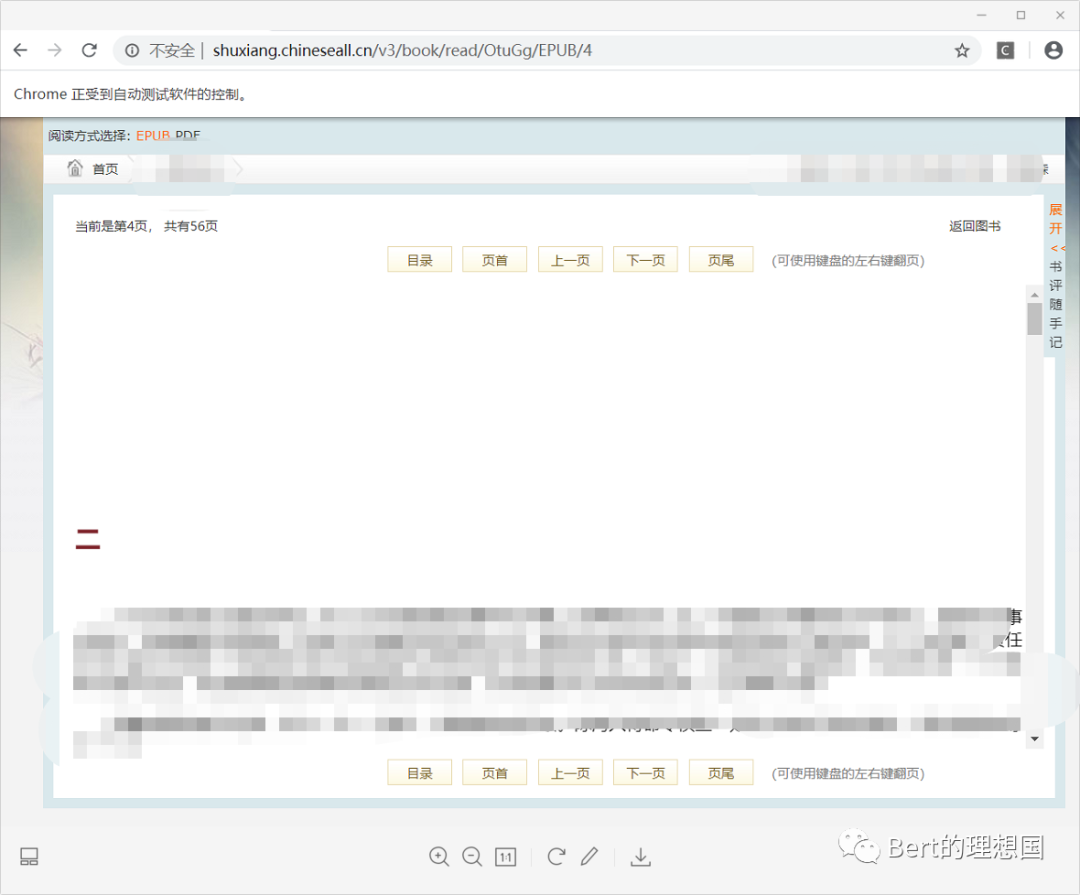
使用selenium中的switch_to.frame(id)就可以转达框架内进行操作 代码如下: from selenium import webdriverfrom bs4 import BeautifulSoupfrom selenium.webdriver import ActionChainsimport timeb_driver = webdriver.Chrome()url_str="http://shuxiang.chineseall.cn/v3/book/read/OtuGg/EPUB/"url=[url_str+str(i)for i in range(2,8)]#actions=ActionChains(b_driver)f=open("D:\\研究数据爬取\\datatext.txt",'a')def getTexts(url,urla): webdriver.Chrome() b_driver.get(url) b_driver.switch_to.frame('epubViewFrame')#转入iframe标签内 page=b_driver.page_sourceprint(page) soup=BeautifulSoup(page,'lxml') soup_text=soup.select('p[]')for i in range(0,len(soup_text)): print(soup_text[i].string)if soup_text[i].string==None: f.write(" ")else: f.write(soup_text[i].string) f.write("\n") f.write("*"*30+"\n") b_driver.switch_to.window(b_driver.window_handles[-1])#使用新的标签进行访问下一个链接 b_driver.get(urla)for i in range(1,len(url)): if i==len(url): break else: time.sleep(10) getTexts(url[i],url[i+1])效果如下:
总结 遇到需要爬取iframe内的信息网站的时候如果不要求时间的话完全可以使用selenium来爬取就可以,任何的js或者ajax对其都没有什么作用,但是如果有$cbc以及webdriver检测的话可能selenium就不行了。requests相对麻烦一些,因为需要抓包看一下相关的链接情况。最后还是要提醒一下,写任何的爬虫都不要给网站服务器造成负担,设置合理的休眠时间。
|








【本文地址】