| 【hadoop期末复习】第九章 数据仓库Hive 超详细讲解 | 您所在的位置:网站首页 › hive组成部分 › 【hadoop期末复习】第九章 数据仓库Hive 超详细讲解 |
【hadoop期末复习】第九章 数据仓库Hive 超详细讲解
|
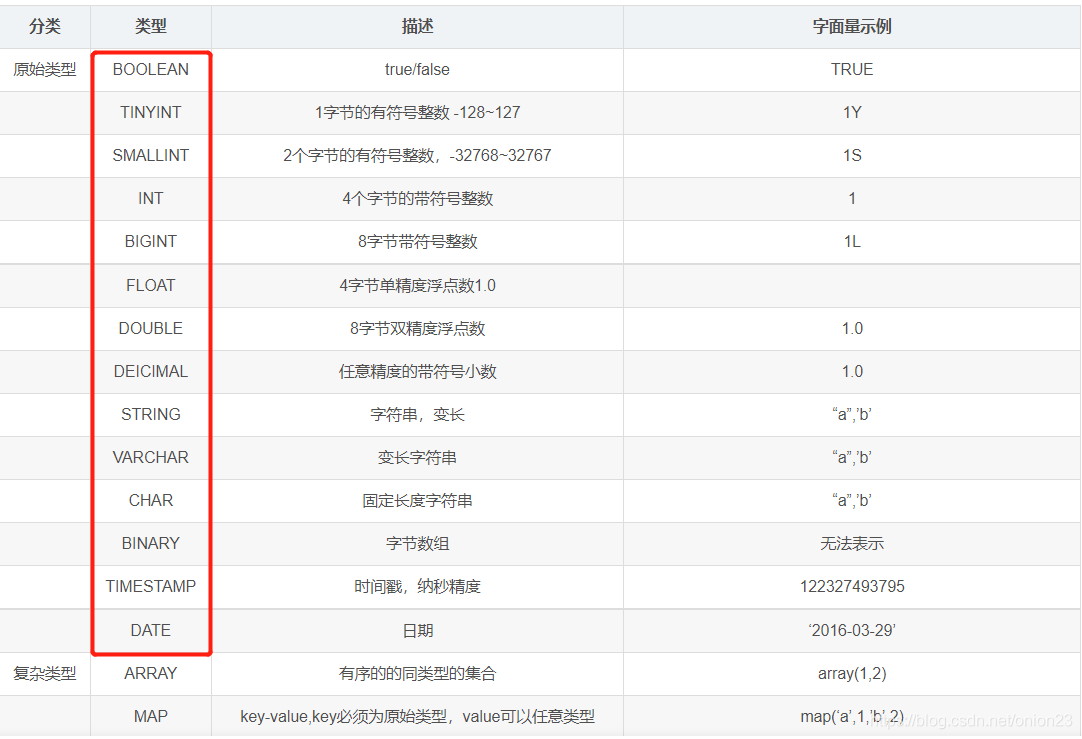
** 本专栏的Hadoop复习计划文章内容主要包含以下几个部分: 【简单】学习通习题 【进阶】课本课后练习 【操作】相关章节实验回顾 让我们开始吧! 学习通 - 习题 1. 下列关于Hive基本操作命令的解释错误的是A.create table if not exists usr(id bigint,name string,age int);//如果usr表不存在,创建表usr,含三个属性id,name,age B.load data local inpath ‘/usr/local/data’ overwrite into table usr; //把目录’/usr/local/data’下的数据文件中的数据以追加的方式装载进usr表 C.create database userdb;//创建数据库userdb D.insert overwrite table student select * from user where age>10; //向表student中插入来自usr表的age大于10的数据并覆盖student表中原有数据 我的答案:B 解析: B.load data local inpath ‘/usr/local/data’ overwrite into table usr; //把目录’/usr/local/data’下的数据文件中的数据以追加的方式装载进usr表 - 错误 overwrite - 意为“覆写”,直接把新数据写进去,覆盖原有的表 2. 下列说法正确的是A.Impala和Hive、HDFS、HBase等工具可以统一部署在一个Hadoop平台上 B.数据仓库Hive不需要借助于HDFS就可以完成数据的存储 C.Hive本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据 D.HiveQL语法与传统的SQL语法很相似 我的答案:ACD 解析: A.Impala和Hive、HDFS、HBase等工具可以统一部署在一个Hadoop平台上 正确,因为Impala和Hive都可以与HDFS、HBase进行交互 B.数据仓库Hive不需要借助于HDFS就可以完成数据的存储 错误,hive简介如下: Hive某种程度上可以看作是用户编程接口,本身不存储和处理数据依赖HDFS存储数据依赖MapReduce处理数据定义了简单的类SQL 查询语言 HiveQL(HQL)用户可以通过编写的HQL语句运行MapReduce任务是一个可以提供有效、合理、直观组织和使用数据的模型C.Hive本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据 正确 D.HiveQL语法与传统的SQL语法很相似 正确 3. 以下属于Hive的基本数据类型是A.TINYINT B.BINARY C.FLOAT D.STRING 我的答案:ABCD 解析: hive的基本数据类型有:
Hive 传统数据库 数据插入 支持批量导入 支持单条和批量导入 数据更新 不支持 支持 索引 支持 支持 分区 支持 支持 执行延迟 高 低 扩展性 好 有限 3. 简述hive的几种访问方式1)内部访问 CLIHWI2)外部访问 KarmasphereHueQubole 4. 对hive的几个主要组成模块进行简要介绍1)用户接口模块 包含:CLI、HWI、JDBC、ODBC、Thrift Server等CLI:Hive自带的一个命令行界面HWI:Hive的一个简单网页界面JDBC、ODBC、Thrift Server:向用户提供进行编程访问的接口2)驱动模块 包含:编译器、优化器、执行器等所有命令和查询都会进入到驱动模块,通过该模块对输入进行解析编译,对需求的计算进行优化,然后按照指定的步骤进行执行3)元数据存储模块 是一个独立的关系型数据库通常是与MySQL数据库连接后创建的一个MySQL实例,也可以是Hive自带的derby数据库实例元数据存储模块中主要保存表模式和其他系统元数据(如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等) 5. 简述hive中输入一条查询的具体执行过程1)SQL → 语法树 2)语法树 → 查询块 3)查询块 → 逻辑查询计划 4)重写逻辑查询计划 5)逻辑查询计划 → 物理计划(MapReduce Jobs) 6)选择最佳的优化查询策略 图示:
Impalad 是 Impala 的一个进程 功能: 负责协调客户端提交查询的执行给其他impalad分配任务收集其他impalad的执行结果进行汇总 8. 比较hive与Impala的异同点1)不同点 Hive适合于长时间的批处理查询分析,而Impala适合于实时、交互式SQL查询 Hive依赖于MapReduce计算框架,执行计划组合成管道型的MapReduce任务模式进行执行,Impala把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询。 Hive在执行过程中,如果内存放不下所有数据,则会使用外存,以保证查询能顺序执行完成,而Impala在遇到内存放不下数据时,不会利用外存,所以Impala目前处理查询时会受到一定的限制。 2)相同点 Hive、Impala使用相同的存储数据池,都支持把数据存储于HDFS、HBase中 Hive与Impala使用相同的元数据 Hive与Impala中对SQL的解释处理比较相似,都是通过词法分析生成执行计划 9. 简述 state store的作用Impala主要由Impalad,State Store和CLI三部分组成State Store会创建一个statestored进程 作用: 跟踪集群中的Impalad的健康状态及位置信息创建多个线程来处理Impalad的注册订阅和与各类Impalad保持心跳连接当State Store离线后,Impalad一旦发现State Store处于离线时,就会进入recovery模式,并进行反复注册当State Store重新加入集群后,自动恢复正常,更新缓存数据3. CLI给用户提供查询使用的命令行工具提供了Hue、JDBC及ODBC的使用接口 10. 简述impala执行一条查询的具体过程 当用户提交查询前,Impala先创建一个负责协调客户端提交的查询的Impalad进程,该进程会向Impala State Store提交注册订阅信息,State Store会创建一个statestored进程,statestored进程通过创建多个线程来处理Impalad的注册订阅信息用户通过CLI客户端提交一个查询到impalad进程,Impalad的Query Planner对SQL语句进行解析,生成解析树;然后,Planner把这个查询的解析树变成若干PlanFragment,发送到Query Coordinator,其中,PlanFragment由PlanNode组成的,能被分发到单独的节点上原子执行,每个PlanNode表示一个关系操作和对其执行优化需要的信息Coordinator通过从HDFS的名称节点中获取数据地址,从MySQL元数据库中获取元数据,以得到存储这个查询相关数据的所有数据节点Coordinator初始化相应impalad上的任务执行,即把查询任务分配给所有存储这个查询相关数据的数据节点Query Executor通过流式交换中间输出,并由Query Coordinator汇聚来自各个impalad的结果Coordinator把汇总后的结果返回给CLI客户端 11. 列举hive值的列所支持的3种集合数据类型 ARRAY 矩阵MAP 映射STRUCT 结构体
** 见下文中的实验回顾 实验回顾** 详见我之前写的:【hadoop学习之路】Hive HQL 语句实现查询 |



【本文地址】