| 头歌大数据作业六:Hive | 您所在的位置:网站首页 › hive基本操作实验结果 › 头歌大数据作业六:Hive |
头歌大数据作业六:Hive
|
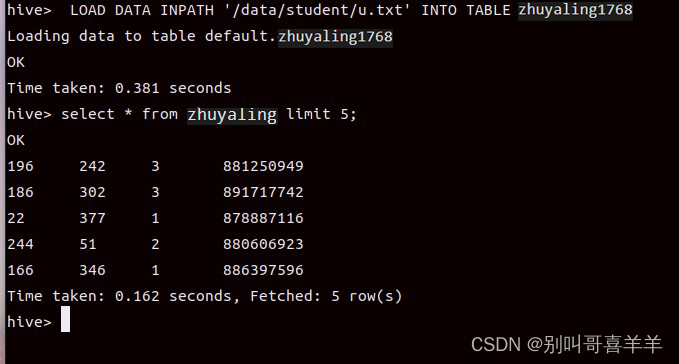
课外作业六:Hive 作业详情内容 一、 阿里云-云起实验室-《基于EMR离线数据分析》 基于EMR离线数据分析 - 云起实验室-在线实验-上云实践-阿里云开发者社区-阿里云官方实验平台-阿里云 ,或者在自己的虚机上安装Hive,安装步骤详见后面。 实验要求: 完成教材9.6-Hive基本操作。 Hive数据表emrusers改为自己姓名全拼接学号后四位,截图:查询数据表中有多少条数据结果,包含Hive命令。 《Hive创建数据仓库》KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云 三、简要回答“课堂考核”内容 1、HiveQL语言是不是SQL语言? 答:HiveQL是类似于SQL的查询语言,它的语法与SQL相似,但是有一些不同之处。HiveQL支持类SQL语法,包括SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等关键词,但也有一些SQL不支持的关键词和语法,如USING、CLUSTER BY、DISTRIBUTE BY、LATERAL VIEW等。 2、Hive不指明数据库的话,创建表是哪个数据库的? 如果在Hive中创建表时没有指定数据库,则表会被创建在默认数据库中。默认情况下,Hive会使用名为default的数据库作为默认数据库。可以使用USE语句来指定要使用的数据库,例如USE my_database; 将当前数据库切换到my_database。也可以在CREATE TABLE语句中使用database.table_name来明确指定表所属的数据库,例如CREATE TABLE my_database.my_table (col1 INT, col2 STRING); 将表my_table创建在my_database数据库中。 3、Hive怎么创建表?怎么创建分区表? 在Hive中创建表的语法为: CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC]), ...]] [INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [TBLPROPERTIES (property_name=property_value, ...)] 其中,如果要创建分区表,需要在CREATE TABLE语句中使用PARTITIONED BY子句来指定分区键,例如: CREATE TABLE my_table ( col1 INT, col2 STRING ) PARTITIONED BY (col3 STRING, col4 INT); 4、Hive怎么加载数据?列是用什么符合分隔的?行是用什么符合分隔的? 可以使用以下命令从 Hadoop 中加载数据到 Hive 表中: LOAD DATA INPATH 'hdfs_path' INTO TABLE table_name; 其中,hdfs_path 是存储数据的 HDFS 路径,table_name 是目标表格的名称。 在加载数据之前,需要确保表格的结构和数据格式匹配。Hive 支持多种数据格式,包括 CSV、文本、序列化等。默认情况下,列之间使用制表符 \t 进行分隔,行之间使用换行符进行分隔。如果要使用其他的列分隔符或行分隔符,可以在创建表格时指定 ROW FORMAT 和 FIELDS TERMINATED BY 选项,例如: CREATE TABLE mytable( column1 string, column2 int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; 这个命令将创建一个名为 mytable 的表格,其中列之间使用逗号进行分隔。在加载数据时,会自动根据指定的分隔符进行解析。 5、Hive查询数据怎么查询?查询条件是什么? 要查询 Hive 中的数据,可以使用 SELECT 语句,例如: SELECT * FROM mytable WHERE column1 = 'value'; 其中,mytable 是要查询的表格名称,column1 是要查询的列名称,'value' 是查询条件。可以根据需要指定多个查询条件,并使用逻辑运算符 AND 或 OR 进行连接。还可以使用以下命令将查询结果保存到其他表格中: INSERT OVERWRITE TABLE myoutput SELECT * FROM mytable WHERE column1 = 'value'; 这个命令将查询 mytable 表格中列 column1 的值为 'value' 的所有记录,并将结果保存到 myoutput 表格中。 6. Hive统计数据怎么统计? HiveQL语句中统计的关键词是什么意思? Hive统计数据可以使用如下关键词: • COUNT:返回指定列或行的记录数。 • SUM:返回指定数值类型列的和。 • AVG:返回指定数值类型列的平均值。 • MAX:返回指定列或行的最大值。 • MIN:返回指定列或行的最小值。 HiveQL语句中可以使用这些关键词来对数据进行统计分析。 四、习题 9.8 试述在Hadoop生态系统中Hive与其组件之间的相互关系。 Hive与Hadoop生态系统的组件之间的相互关系:Hive与Hadoop生态系统中的其他组件(如HDFS、YARN、MapReduce等)紧密集成,Hive底层使用HDFS存储数据,使用YARN管理作业,使用MapReduce进行计算。请简述Hive与传统数据库的区别。 Hive与传统数据库的区别:Hive是一种基于Hadoop生态系统的数据仓库,与传统的关系型数据库相比,Hive更适合处理大数据,支持数据的延迟插入和大规模的批处理,而且并不支持事务处理。请简述Hive的几种访问方式。 Hive的几种访问方式: Hive提供了CLI(命令行界面)、JDBC/ODBC驱动、Web服务等多种访问方式,可根据具体需求进行选择。请分别对Hive的几个注意组成模块进行简要介绍。 HCatalog:提供了一种将Hive集成到其他Hadoop组件中的方法。Metastore:存储了Hive表的元数据信息。Hive服务(HiveServer2):作为客户端与Hive进行通信的接口。Hive驱动:负责将HiveQL转化为MapReduce任务。 请简述向Hive输入一条查询的具体执行过程。 通过客户端提交Hive查询语句,查询语句交给Hive服务。Hive服务通过Hive驱动将HiveQL语句传给解析器,分析HiveQL语句以建立执行计划。执行计划被分解为一系列的MapReduce任务,并被提交到YARN中执行。MapReduce任务执行完毕后,结果被返回给Hive服务,最后返回给命令行界面或客户端应用程序。 请简述Hive HA原理。 Hive HA原理:Hive HA实现了同步反复,通过Zookeeper高可用框架实现了Hive的高可用性。当主节点宕机时,备用节点立即取代主节点的角色,实现了快速的自动故障转移。请简述Impalad进程的主要作用。 Impalad进程的主要作用:Impalad进程负责处理从客户端接收的查询请求,包括解析、优化和执行查询。它还负责和Metastore交互,以便Impala能够获取元数据信息。请比较Hive与Impala的异同点。 异同点:Hive使用MapReduce进行计算,而Impala可以直接在存储文件上执行查询以达到更高的查询速度;Hive仅支持离线批处理操作,而Impala可以进行实时查询。相同点:Hive和Impala都是针对Hadoop生态系统的数据仓库,两者都使用SQL-like语言HiveQL。 请简述State Store的作用。 State Store的作用:State Store是Impala集群中负责存储Impala的状态信息的进程,包括Impala使用的元数据、执行计划和查询进度等。请简述Impala执行一条查询的具体过程。 客户端连接到一个Impala Daemon,发送查询请求。Impala Daemon解析请求,然后发送给State Store,以获取元数据和执行计划。Impala Daemon针对查询构建执行计划,然后将其划分为若干个片段,并把每个片段分配给Impala Daemon集群中的某个节点来执行。Impala执行每个片段并返回结果集,最终结果集由Impala Daemon将所有结果集组合成一个结果集并返回给客户端。 请列举Hive中的列所支持的3种集合数据类型。 ARRAY:一种值的有序集合,元素可以是任何数据类型。MAP:一种键值对的无序集合,键和值可以是任何数据类型。STRUCT:一组同数据类型或不同数据类型的值的集合。 请举例几个Hive的常用操作及基本语法。 创建表:CREATE TABLE table_name(column1 datatype, column2 datatype, …);查询数据:SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list [ASC | DESC]] [LIMIT number]加载数据:LOAD DATA [LOCAL] INPATH 'input_path' [OVERWRITE] INTO TABLE table_name;统计数据:使用COUNT、SUM、AVG、MAX、MIN关键词进行统计分析。创建分区表:CREATE TABLE table_name(column1 datatype, column2 datatype, …) PARTITIONED BY (partition_column1 datatype, partition_column2 datatype, …);定义分隔符:ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'; |

 完成以下华为云三个实验,其中《Hive的数据统计》实验,最后一步多表统计中,两个表名接自己姓名全拼,截图HQL统计语句和执行结果。 二、华为云KooLabs实验
完成以下华为云三个实验,其中《Hive的数据统计》实验,最后一步多表统计中,两个表名接自己姓名全拼,截图HQL统计语句和执行结果。 二、华为云KooLabs实验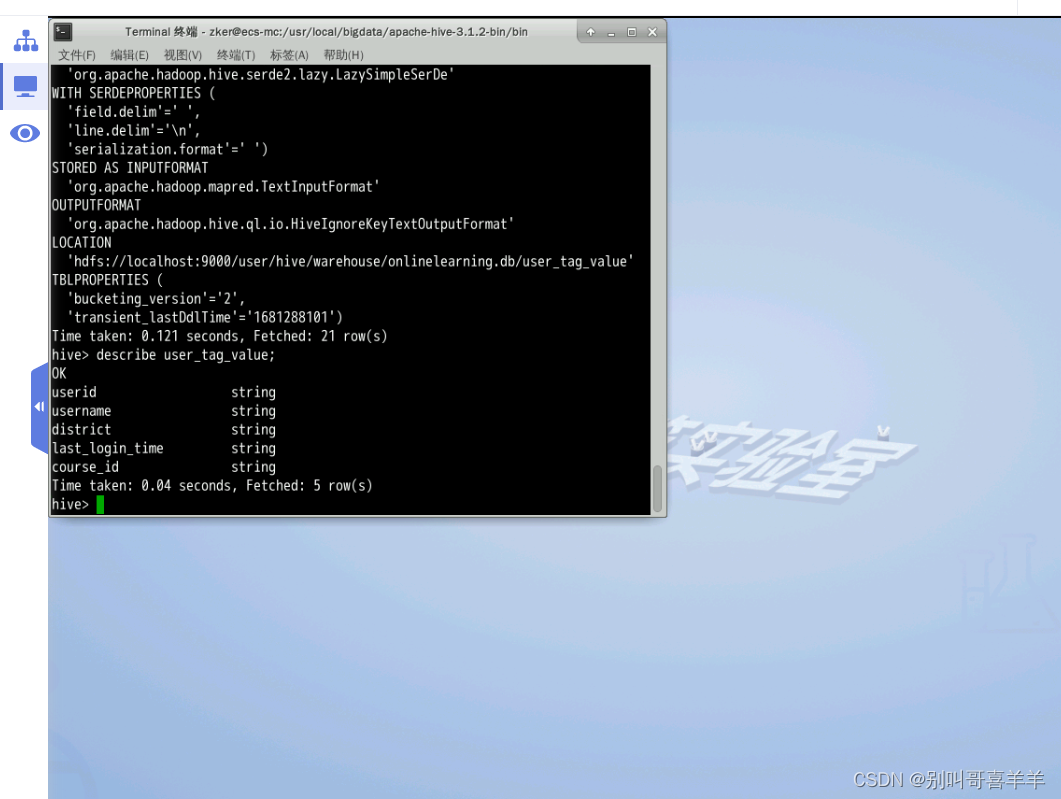
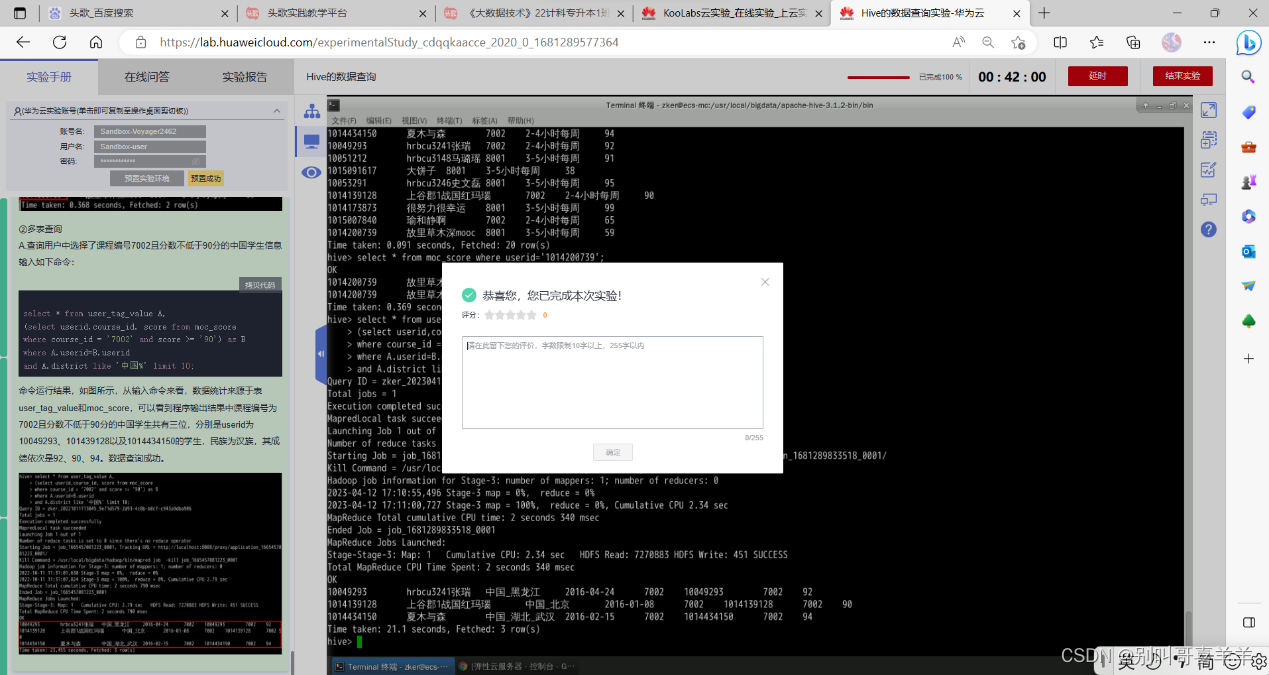
 《Hive的数据查询》KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云
《Hive的数据查询》KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云 
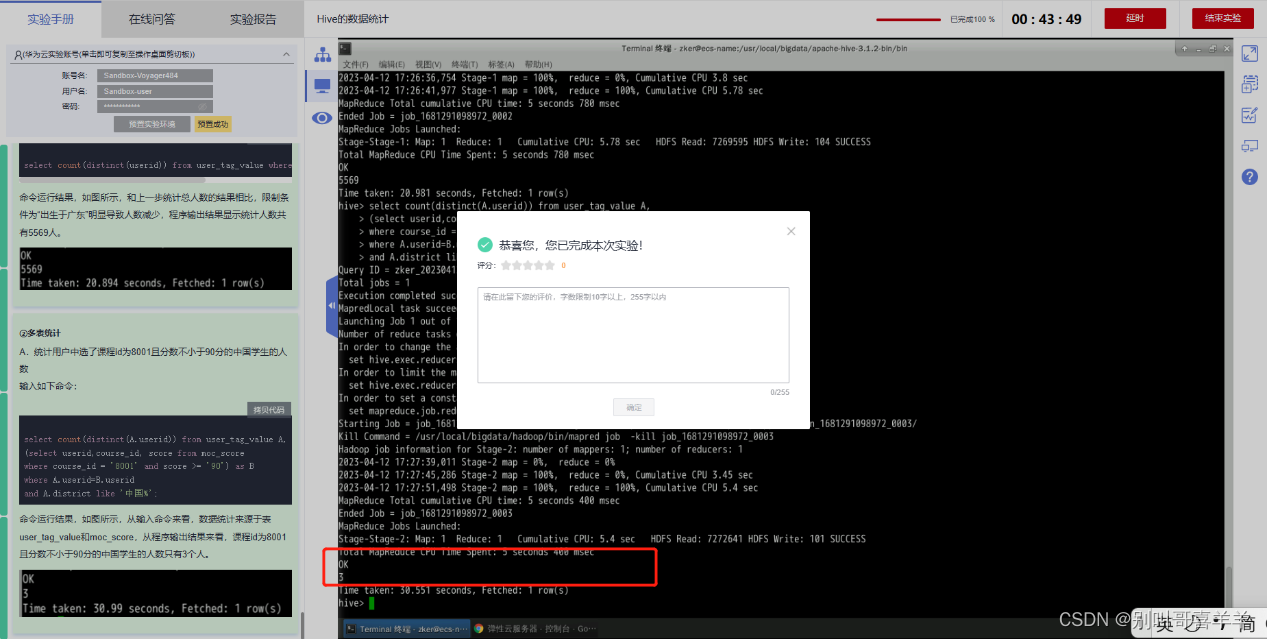
 《Hive的数据统计》KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云
《Hive的数据统计》KooLabs云实验_在线实验_上云实践_云计算实验_AI实验_华为云官方实验平台-华为云 
【本文地址】