| HashMap底层分析 | 您所在的位置:网站首页 › hashmap计算下标 › HashMap底层分析 |
HashMap底层分析
|
当我们向HashMap容器中put一个元素时,这个元素会被放到一个Node结点对象中,结点对象又会被放入到数组中,那么结点对象会被放入数组的什么位置呢?这是由key的hash值来决定的。
2. 根据hashCode值,通过hash算法,计算出hash值。(那么使用什么算法来计算hash值呢? 既要保证 运算速度快,又要保证 计算出来的hash值能均匀分布在[0,数组长度 - 1]区间内) 3. hash算法实现分为两步:
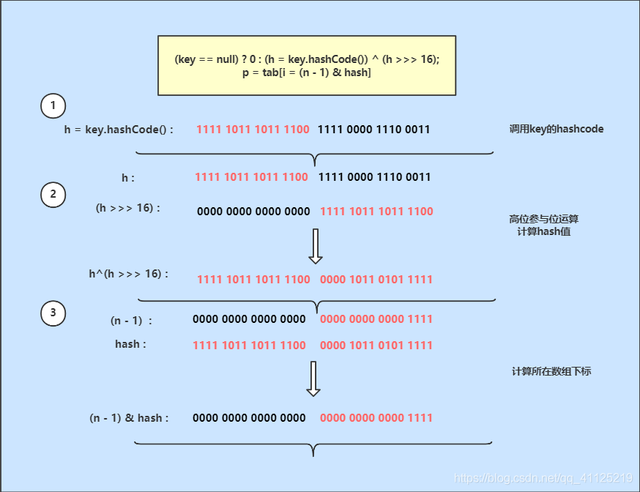
第一步就是hash()函数,将key的hashCode值 与 key的hashCode值的高16位(无符号右移),进行^异或运算,得到一个hash值(注意:这个hash值,不是index索引,需要进行第二步计算后得到的才是index索引) static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } h >>> 16(h无符号右移16位),即在h二进制数的左侧加16个0,得到的就是h二进制数的高16位 int类型是32位,左侧16位是高16位,右侧16位是低16位 如:某个key的hashCode值的整数h = 550550,则它的二进制数是h = 0000 0000 0000 1000 0110 0110 1001 0110 h >>> 16,得到的是h二进制数的高16位,也就是0000 0000 0000 0000 0000 0000 0000 1000 h与h的高16位进行^异或运算(异或运算规则:相同为0,相异为1) 0000 0000 0000 1000 0110 0110 1001 0110 ^ 0000 0000 0000 0000 0000 0000 0000 1000 -------------------------------------------------------- 0000 0000 0000 1000 0110 0110 1001 1110这一步的目的是为了,计算出来的index索引,能均匀分布在[0,数组长度 - 1]区间内。(即是元素分布均匀)。
将第一步中的到的hash值 和 (数组长度 - 1) 进行&运算,得到index索引。(注意:该算法有个前提,约定数组长度必须为2的整数幂。这就是HashMap的容量必须为2的整数幂的原因) index = hash值 & (数组长度 - 1) tab[index = (n - 1) & hash]) tab是HashMap主干数组,i是索引,n是数组长度,hash是第一步中计算出来的hash值很多hash算法采用的都是取模运算(取余,index = hash % n),保证得到的索引小于数组长度,并且分布均匀,但cpu在做/除法运算 或 %取余运算时,效率是很低的。所以jdk对改进了算法,首先在约定数组长度必须是2的整数幂,这样通过&与运算同样可以实现取余的效果(&与运算 比 %取模运算 的效率高)。
2. 为什么取模运算是用 hash % 数组长度 ,而&与运算是 hash & (数组长度 - 1) 呢? 思路清晰的麻烦分享以下哈,就是能用比较简短的言语回答的哪种😗😗
|

 hash值,是用来确定Node结点对象在Node数组中 存取位置 的一个重要数据。hash值经过**&**与运算后会得到一个索引值,它就是Node结点对象在Node数组中 存取位置。
hash值,是用来确定Node结点对象在Node数组中 存取位置 的一个重要数据。hash值经过**&**与运算后会得到一个索引值,它就是Node结点对象在Node数组中 存取位置。  1. 调用key对象的hashCode()方法,获得key的hashCode值。
1. 调用key对象的hashCode()方法,获得key的hashCode值。

 1. cpu执行 &与运算 的效率比执行 %取余运算高很多,那么HashMap中是如何将%取模运算 转换为 &与运算的呢?
1. cpu执行 &与运算 的效率比执行 %取余运算高很多,那么HashMap中是如何将%取模运算 转换为 &与运算的呢?
【本文地址】