| 各公司大数据面试题汇总之Hadoop(MapReduce部分) | 您所在的位置:网站首页 › hadoop统计词频 › 各公司大数据面试题汇总之Hadoop(MapReduce部分) |
各公司大数据面试题汇总之Hadoop(MapReduce部分)
|
一、介绍下MapReduce 问过的一些公司:字节x2,字节(2021.09),美团,美团(2021.08),网易有道(2021.10) 回答技巧:结合MapReduce的优缺点回答(下一题) 参考答案: MapReduce 是一个分布式运算程序的编程框架,它的核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。 MapReduce的核心思想是将用户编写的逻辑代码和架构中的各个组件整合成一个分布式运算程序,实现一定程序的并行处理海量数据,提高效率。 海量数据难以在单机上处理,而一旦将单机版程序扩展到集群上进行分布式运行势必将大大增加程序的复杂程度。引入MapReduce架构,开发人员可以将精力集中于数据处理的核心业务逻辑上,而将分布式程序中的公共功能封装成框架,以降低开发的难度。 一个完整的mapreduce程序有三类实例进程 MRAppMaster:负责整个程序的协调过程 MapTask:负责map阶段的数据处理ReduceTask:负责reduce阶段的数据处理二、MapReduce优缺点问过的一些公司:小米 参考答案: 优点 1)MapReduce 易于编程 它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。 2)良好的扩展性 当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。 3)高容错性 MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行, 不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。 4)适合 PB 级以上海量数据的离线处理 可以实现上千台服务器集群并发工作,提供数据处理能力。 缺点 1)不擅长实时计算 MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。 2)不擅长流式计算 流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce 自身的设计特点决定了数据源必须是静态的。 3)不擅长 DAG(有向无环图)计算 多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘, 会造成大量的磁盘 IO,导致性能非常的低下。 三、MapReduce工作原理可回答:1)MapReduce(执行)流程;2)对MapReduce的理解;3)MapReduce过程;4)MapReduce 的详细过程;5)MapReduce原理;6)MapReduce中有没有涉及到排序;7)MapReduce提交job到YARN 的流程;8)MapReduce原理,map和reduce过程;9)说一下MapReduce流程 问过的一些公司:阿里×4,字节×7,字节(2021.08)x3-(2021.10),头条,滴滴,百度,腾讯×4,Shopee, 小米,爱奇艺,祖龙娱乐,360×5,商汤科技,网易×5,51×2,星环科技,招银网络,作业帮,映客直 播,美团×16,美团(2021.09)x2,字节×2,有赞,58×3,华为x2,创略科技,米哈游,快手,快手 (2021.09),京东×4,趋势科技,海康威视,顺丰,好未来x3,一点资讯,冠群驰骋,中信信用卡中心, 金山云,米哈游,途牛,大华(2021.07),京东(2021.07),Shopee(2021.08),多益(2021.09),荣耀 (2021.09),百度(2021.08、2021.09),阿里蚂蚁(2021.08),携程(2021.09),虎牙(2021.08),重庆富民银行 (2021.09),网易有道(2021.09),携程(2021.09),陌陌(2021.10),腾讯(2022.03) 参考答案: 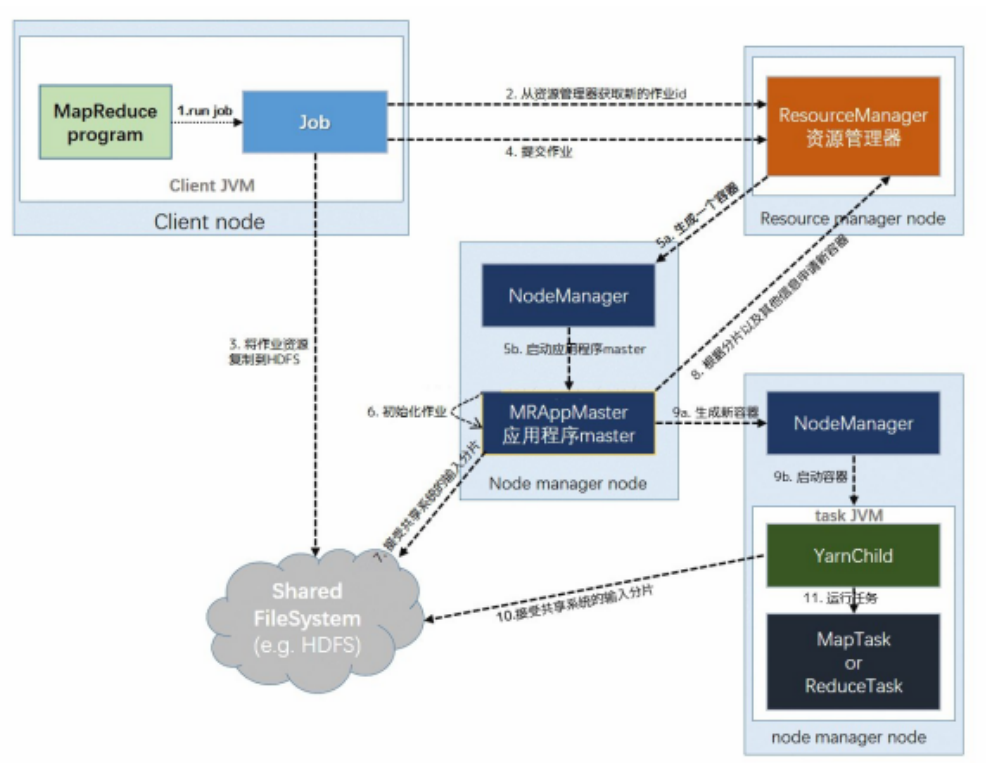 1、提交作业 Client提交Job: Client编写好Job后,调用Job实例的Sumit() 或者 waitForCompletion() 方法提交作业; 从RM(而不是Jobtracker)获取新的作业ID,在YARN命名法中它是一个Application ID(步骤2)。 Job提交到RM: Client检查作业的输出说明,计算输入分片,并将作业资源(包括作业JAR、配置和分片信息)复制到HDFS(步骤3); 调用RM的 submitApplication() 方法提交作业(步骤4)。 2、作业初始化 给作业分配ApplicationMaster: RM收到调用它的 submitApplication() 消息后,便将请求传递给 scheduler (调度器); scheduler分配一个 Container,然后 RM在该 NM的管理下在 Container中启动 ApplicationMaster(步骤5a & 5b)。 ApplicationMaster初始化作业: MR作业的ApplicationMaster 是一个Java应用程序,它的主类是 MRAppMaster。它对作业进行初始化:通过创建多个薄记对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告 (步骤6); ApplicationMaster 从HDFS中获取 在Client 计算的输入分片(map、reduce任务数)(步骤7)【对每一个分片创建一个 map 任务对象以及由 mapreduce.job.reduces 属性确定的多个 reduce 任务对象】。 3、任务分配 ApplicationMaster 为该作业中的所有 map 任务和 reduce 任务向 RM 请求 Container (步骤8); 【随着心跳信息的请求包括每个map任务的数据本地化信息,特别是输入分片所在的主机和相应机架信息。理想情况下,它将任务分配到数据本地化的节点,但如果不可能这么做,就会相对于本地化的分配优先使用机架本地化的分配】 4、任务执行 一旦 RM 的 scheduler 为任务分配了 Container, ApplicationMaster就通过与 NM通信来启动 Container (步骤9a & 9b); 该任务由主类为 YardChild 的Java应用程序执行。在它运行任务之前,首先将任务需要的资源本地化(包括作业的配置、JAR文件和所有来自分布式缓存的文件)(步骤10); 最后,运行 map 任务或 reduce 任务(步骤11)。 5、进度和状态的更新 在YARN下运行,任务每 3s通过 umbilical 接口向 ApplicationMaster 汇报进度和状态(包括计数 器),作为作业的汇聚试图(aggregate view)。 6、作业完成 除了向 ApplicationMaster 查询进度外,Client 每 5s还通过调用 Job 的 waitForCompletion() 来检查作业是否完成【查询的间隔可以通过 mapreduce.client.completion.pollinterval 属性进行设置】。 作业完成后, ApplicationMaster 和任务容器清理其工作状态, OutputCommitter 的作业清理方法会被调用。作业历史服务器保存作业的信息供用户需要时查询。 四、MapReduce中的Combine是干嘛的?有什么好处?问过的一些公司:字节 参考答案: 在MapReduce中,Combine 阶段是当Map阶段所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。 让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。 Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出k-v应该跟reducer的输入 k-v类型要对应起来。 五、MapReduce为什么一定要有Shuffle过程问过的一些公司:百度,头条,字节(2021.09) 参考答案: MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负 责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle 来获取数据。 从Map输出到Reduce输入的整个过程可以广义地称为Shuffle 。Shuffle 横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程。 六、MapReduce的Shuffle过程及其优化可回答:1)Hadoop的Shuffle过程;2)为什么Map端输出的时候需要排序?不排序直接输出难道不好吗?3)介绍下MapReduce的Shuffle机制;3)你觉得MapReduce有哪些需要优化的地方;4)哪些操作引起shuw le;5)说一下Shuffle机制;6)说一下reduce的Shuffle?7)Shuffle流程的细节是什么 问过的一些公司:字节×4,字节(2021.07)(2021.08),头条,百度×2,第四范式,360,猿辅导,美团×3, 美团(2021.08)(2021.09),平安,创略科技,网易x2,多益,顺丰,转转,抖音,一点咨询,作业帮×2,东方头条,大华(2021.07),字节(2021.08),荣耀(2021.09)x2,贝壳(2021.08),蔚来(2021.09) 参考答案: Shuffle的本义是洗牌、混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好。MapReduce中的Shuffle更像是洗牌的逆过程,把一组无规则的数据尽量转换成一组具有一定规则的数据。 为什么MapReduce计算模型需要Shuffle过程?我们都知道MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。 从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示: 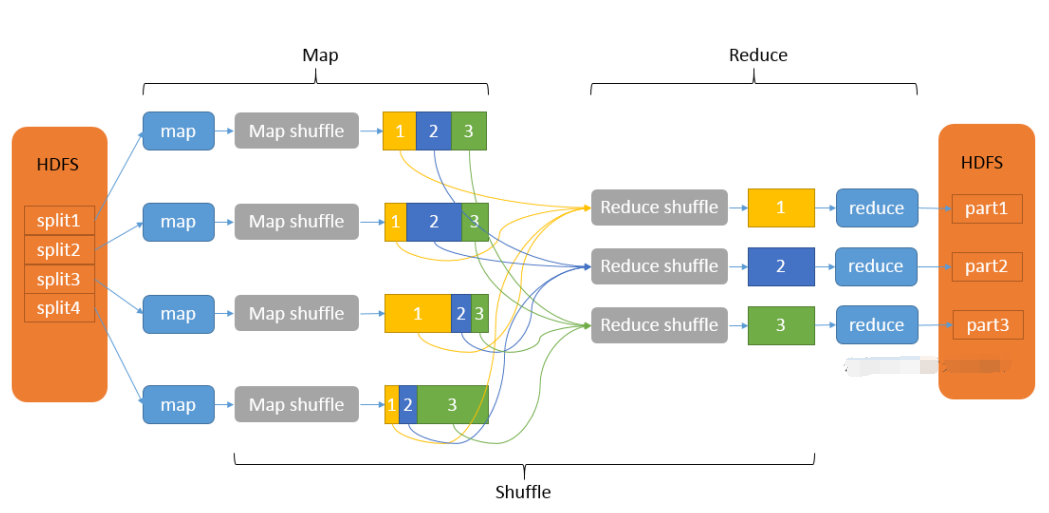 MapReduce Shuw le后续优化方向 压缩:对数据进行压缩,减少写读数据量; 减少不必要的排序:并不是所有类型的Reduce需要的数据都是需要排序的,排序这个nb的过程如果不需要最好还是不要的好; 内存化:Shuw le的数据不放在磁盘而是尽量放在内存中,除非逼不得已往磁盘上放;当然了如果有性能和内存相当的第三方存储系统,那放在第三方存储系统上也是很好的;这个是个大招; 网络框架:netty的性能据说要占优了; 本节点上的数据不走网络框架:对于本节点上的Map输出,Reduce直接去读吧,不需要绕道网络框架。七、shuffle为什么要排序?问过的一些公司:携程(2021.09),网易有道(2021.09) 参考答案: shuffle排序,按字典顺序排序的,目的是把相同的的key可以提前一步放到一起。 sort是用来shuffle的,shuffle就是把key相同的东西弄一起去,其实不一定要sort也能shuffle,那为什么要sort排序呢? sort是为了通过外排(外部排序)降低内存的使用量:因为reduce阶段需要分组,将key相同的放在一起进行规约,使用了两种算法:hashmap和sort,如果在reduce阶段sort排序(内部排序),太消耗内存,而map阶段的输出是要溢写到磁盘的,在磁盘中外排可以对任意数据量分组(只要磁盘够大),所以,map端排序(shuffle阶段),是为了减轻reduce端排序的压力。 八、map join的原理(实现)?应用场景?问过的一些公司:美团,阿里 参考答案: map join流程 Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多 份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。 MapJoin简单说就是在Map阶段将小表读入内存,顺序扫描大表完成Join。减少昂贵的shuffle操作及reduce操作 MapJoin分为两个阶段: 通过MapReduce Local Task,将小表读入内存,生成HashTableFiles上传至Distributed Cache中,这里会HashTableFiles进行压缩。 MapReduce Job在Map阶段,每个Mapper从Distributed Cache读取HashTableFiles到内存中,顺序扫描大表,在Map阶段直接进行Join,将数据传递给下一个MapReduce任务。使用场景 MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数 hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。 Hive0.7之前,需要使用hint提示 /*+ mapjoin(table) */才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true. 假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为MapJoin。 九、MapReduce为什么不能产生过多小文件问过的一些公司:好未来x2 参考答案: 默认情况下,TextInputFormat 切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切 片,都会单独交给一个 MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低 下。 MapReduce大量小文件的优化策略: 最优方案:在数据处理的最前端(预处理、采集),就将小文件合并成大文件,在上传到HDFS做后续 的分析 补救措施:如果HDFS中已经存在大量的小文件了,可以使用另一种Inputformat来做切片(CombineFileInputformat),它的切片逻辑跟FileInputformat不同,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个 MapTask 处理。 十、MapReduce分区及作用可回答:Map默认是HashPartitioner如何自定义分区 问过的一些公司:百度,头条,字节(2021.08) 参考答案: 1、默认分区 系统自动调用HashPartitioner类进行分区,默认分区是根据key的hashCode对ReduceTasks个数取模得到的。用户没法控制哪个key存储到哪个分区。 2、自定义分区 (1)自定义类继承Partitioner,重写getPartition()方法 (2)在Job驱动中,设置自定义Partitioner (3)自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的ReduceTask 3、全局排序 全局排序是通过将进入map端之前的数据进行随机采样,在采取的样本中设置分割点,通过分割点将数据进行分区,将设置的分割点保存在二叉树中,Map Task每输出一个数据就会去查找其对应的区间,以此来达到分区效果。 作用 根据业务实际需求将统计结果按照条件产生多个输出文件(分区) 多个reduce任务运行,提高整体job的运行效率 十一、MapReduce的reduce使用的是什么排序?问过的一些公司:美团 参考答案: 这里把map和reduce的都说一下 对于MapTask,它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,而当数据处理完毕后,它会对磁盘上所有文件进行归并排序。 对于ReduceTask,它从每个MapTask上远程拷贝相应的数据文件,如果文件大小超过一定阈值,则溢写磁盘上,否则存储在内存中。如果磁盘上文件数目达到一定阈值,则进行一次归并排序以生成一个更大文件;如果内存中文件大小或者 数目超过一定阈值,则进行一次合并后将数据溢写到磁盘上。当所有数据拷贝完毕后,ReduceTask统一对内存和磁盘上的所有数据进行一次归并排序。 十二、结合wordcount述说MapReduce,具体各个流程,map怎么做,reduce怎么做 可回答:1)给一个场景,mapreduce统计词频原理;2)WordCount在MapReduce中键值对的变化;3) 讲下MapReduce的具体任务过程;4)一次MapReduce过程 回答技巧:比如问结合实际场景说下MapReduce,可以说根据wordcount来讲一下MapReduce过程 问过的一些公司:字节,大华,趋势科技,一点资讯,奇安信,58同城(2021.08),阿里(2021.09) 参考答案: 先来看一张图  具体各个阶段做了什么 spliting :Documents会根据切割规则被切成若干块, map阶段:然后进行Map过程,Map会并行读取文本,对读取的单词进行单词分割,并且每个词以键值对形式生成。 combine阶段:接下来Combine(该阶段是可以选择的,Combine其实也是一种reduce)会对每个片相同的词进行统计。 shuffle阶段:将Map输出作为reduce的输入的过程就是shuffle, 次阶段是最耗时间,也是重点需要优化的阶段。shuffle阶段会对数据进行拉取,对最后得到单词进行统计,每个单词的位置会根据Hash来确定所在的位置,reduce阶段:对数据做最后的汇总,最后结果是存储在hdfs上。 十三、MapReduce数据倾斜产生的原因及其解决方案可回答:Hadoop数据倾斜问题怎么解决 问过的一些公司:腾讯,大华,多益,冠群驰骋,网易,端点数据(2021.07),阿里蚂蚁(2021.08),字节(2021.08),茄子科技(2021.09),快手(2021.09) 参考答案: 1、数据倾斜现象 数据倾斜就是数据的key的分化严重不均,造成一部分数据很多,一部分数据很少的局面。 数据频率倾斜——某一个区域的数据量要远远大于其他区域。 数据大小倾斜——部分记录的大小远远大于平均值。 2、数据倾斜产生的原因 (1)Hadoop框架的特性 Job数多的作业运行效率会相对比较低;countdistinct、group by、join等操作,触发了Shuw le动作,导致全部相同key的值聚集在一个或几个节点上,很容易发生单点问题。(2)具体原因 key 分布不均匀,某一个key的条数比其他key多太多; 业务数据自带的特性; 建表时考虑不全面; 可能某些 HQL 语句自身就存在数据倾斜问题。3、数据倾斜解决方案 从业务和数据方面解决数据倾斜 有损的方法:找到异常数据。 无损的方法: 对分布不均匀的数据,进行单独计算,首先对key做一层hash,把数据打散,让它的并行度变大,之后进行汇集 数据预处理Hadoop平台的解决方法 1)针对join产生的数据倾斜 场景一:大表和小表join产生的数据倾斜 ① 在多表关联情况下,将小表(关联键记录少的表)依次放到前面,这样能够触发reduce端减少操作次 数,从而减少运行时间。 ② 同时使用Map Join让小表缓存到内存。在map端完成join过程,这样就能省掉redcue端的工作。需要注意:这一功能使用时,需要开启map-side join的设置属性:set hive.auto.convert.join=true(默认是false) ③ 还可以对使用这个优化的小表的大小进行设置: set hive.mapjoin.smalltable.filesize=25000000(默认值25M)场景二:大表和大表的join产生的数据倾斜 ① 将异常值赋一个随机值,以此来分散key,均匀分配给多个reduce去执行 ② 如果key值都是有效值的情况下,需要设置以下几个参数来解决 set hive.exec.reducers.bytes.per.reducer = 1000000000也就是每个节点的reduce,其 默认是处理数据地大小为1G,如果join 操作也产生了数据倾斜,那么就在 hive 中设定 2)group by 造成的数据倾斜 解决方式相对简单: hive.map.aggr=true (默认true) 这个配置项代表是否在map端进行聚合,相当于Combiner hive.groupby.skewindata3)count(distinct)或者其他参数不当造成的数据倾斜 ① reduce个数太少 set mapred.reduce.tasks=800② HiveQL中包含count(distinct)时 使用sum...group byl来替代。例如select a,sum(1) from (select a, b from t group by a,b) group by a; 十四、MapReduce用了几次排序,分别是什么?可回答:MapReduce过程用到了哪些排序? 问过的一些公司:美团,米哈游,大华(2021.07),字节(2021.08) 参考答案: 在Map任务和Reduce任务的过程中,一共发生了3次排序 1)当map函数产生输出时,会首先写入内存的环形缓冲区,当达到设定的阀值,在刷写磁盘之前,后台线程会将缓冲区的数据划分成相应的分区。在每个分区中,后台线程按键进行内排序 2)在Map任务完成之前,磁盘上存在多个已经分好区,并排好序的,大小和缓冲区一样的溢写文件,这时溢写文件将被合并成一个已分区且已排序的输出文件。由于溢写文件已经经过第一次排序,所有合并文件只需要再做一次排序即可使输出文件整体有序。 3)在reduce阶段,需要将多个Map任务的输出文件copy到ReduceTask中后合并,由于经过第二次排序,所以合并文件时只需再做一次排序即可使输出文件整体有序在这3次排序中第一次是内存缓冲区做的内排序,使用的算法使快速排序,第二次排序和第三次排序都是在文件合并阶段发生的,使用的是归并排序 |
【本文地址】