|
一、前言
作者:tiezhu 本人和账号作者是朋友,以后将会公用此账号发布文章,也是一个学习爬虫的小白 此篇文章仅供学习交流,切勿用于其他用途,否则后果自负!
二、过程分析
需要使用的库
import base64
import requests
import re
import os
import http.cookiejar as cookielib
# import pickle
import execjs
import time
import json
from PIL import Image
from urllib import parse
首先进入到微博的主页:https://weibo.com/ 之后按下F12开始咱们的抓包过程 输入账号密码,点击登录  当然这里的账号密码,各位要输入自己正确的,之后会来到二维码扫码登录页面 很容易的就会找到包含二维码的api 当然这里的账号密码,各位要输入自己正确的,之后会来到二维码扫码登录页面 很容易的就会找到包含二维码的api  那我们是不是就可以请求这个接口来获取二维码,使用微博app扫码进行登录了呢 但是这个接口是需要很多参数的,必须找到这些参数的来源,才能获取下来二维码 那我们是不是就可以请求这个接口来获取二维码,使用微博app扫码进行登录了呢 但是这个接口是需要很多参数的,必须找到这些参数的来源,才能获取下来二维码  当然这些参数是肯定需要生成的,这个时候就可以继续看一下其他的包 会看到这个里面有一个image的url,刚好是咱们需要的二维码 还有一个qrid,这个时候我们是不知道这个参数是干嘛用的,咱们对它有个印象即可,没准后面需要呢? 当然这些参数是肯定需要生成的,这个时候就可以继续看一下其他的包 会看到这个里面有一个image的url,刚好是咱们需要的二维码 还有一个qrid,这个时候我们是不知道这个参数是干嘛用的,咱们对它有个印象即可,没准后面需要呢?  当然这个接口也是需要传参的,只不过我反复试了几次之后只有STK_后面的数字变了 网页分析多了之后,一眼就知道是时间戳,其他的没有变化 当然这个接口也是需要传参的,只不过我反复试了几次之后只有STK_后面的数字变了 网页分析多了之后,一眼就知道是时间戳,其他的没有变化  到这里我们就可以开写写咱们的代码了,当然各位可以直接提取image里面的url, 我这里是通过拼接方式来获取的url,当然全局是需要是要使用session()保持会话的, 在开头写下s = requests.session() 部分代码如下: 到这里我们就可以开写写咱们的代码了,当然各位可以直接提取image里面的url, 我这里是通过拼接方式来获取的url,当然全局是需要是要使用session()保持会话的, 在开头写下s = requests.session() 部分代码如下:
def image(self):
'''获取二维码,进行扫码验证登录'''
params = {
'entry': 'sso',
'size': '180',
'service_id': 'pc_protection',
'callback': 'STK_'+str(time.time()*10000)
}
res = s.get(self.image_url,headers = self.headers,params = params)
api_key = re.search('.*?api_key=(.*)"', res.text).group(1)
qrid = re.search('.*?"qrid":"(.*)?",', res.text).group(1)
# qrid 是获取扫描二维码状态url的重要参数
self.qrid = qrid
print(res.text, '\n', api_key, '\n', qrid)
这里我把url以及qrid都获取下来了,运行结果:  下一步,就可以使用这个url来获取二维码图片保存,上下两段代码在同一个函数里面 并且扫码进行登录了 代码如下: 下一步,就可以使用这个url来获取二维码图片保存,上下两段代码在同一个函数里面 并且扫码进行登录了 代码如下:
#拼接二维码图片url
img = 'https://v2.qr.weibo.cn/inf/gen?api_key='
img_url = img + str(api_key)
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
cha_page = s.get(img_url,headers = headers)
with open('img.jpg','wb') as f:
f.write(cha_page.content)
f.close()
try:
img = Image.open('img.jpg') #打开二维码
img.show() #显示二维码
# img.close() #关闭
except Exception as e:
print(u"请到当前目录下,找到二维码并扫描")
# 一般英文字符在使用各种编码下, 基本都可以正常解析, 所以一般不带u;但是中文, 必须表明所需编码, 否则一旦编码转换就会出现乱码。
这个时候二维码就被我们下载下来了  这个时候我们又要继续分析这个二维码的状态了,继续回到网页来 清空一下,会看到一直有数据在刷新,点击看一下, msg显示"未使用" retcode: 50114001 这个时候我们又要继续分析这个二维码的状态了,继续回到网页来 清空一下,会看到一直有数据在刷新,点击看一下, msg显示"未使用" retcode: 50114001  这个时候使用微博app,对二维码进行扫码,下面又刷新了, msg显示"成功扫描,请在手机点击确认以登录" retcode: 50114002 这个时候使用微博app,对二维码进行扫码,下面又刷新了, msg显示"成功扫描,请在手机点击确认以登录" retcode: 50114002  这个时候我们就可以知道,这个网页一直在刷新二维码的状态,是扫码了还是未扫码 或者二维码失效的状态了。我们来分析一下这个url里面包含有什么 这个时候我们就可以知道,这个网页一直在刷新二维码的状态,是扫码了还是未扫码 或者二维码失效的状态了。我们来分析一下这个url里面包含有什么  哎,这里面有一个qrid 的参数,是不是就是上面我们取出来的qrid呢 entry参数是不变的 最后一个就是一个15位的时间戳 哎,这里面有一个qrid 的参数,是不是就是上面我们取出来的qrid呢 entry参数是不变的 最后一个就是一个15位的时间戳 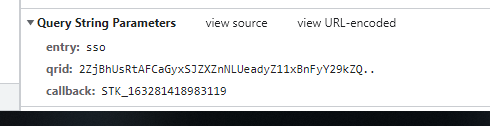 那么这些参数我们都可以拿到之后,是不是就可以判断二维码的状态了 使用While循环一直刷新判断里面的retcode,返回的数据是不规则的json数据 使用正则把里面的数据取出来,才会正常显示字体 里面的数值分表代表: 50114001:二维码未扫描状态 50114002:二维码已扫描未确认状态 20000000:二维码已确认状态 50114004:二维码已失效 附上判断代码: 那么这些参数我们都可以拿到之后,是不是就可以判断二维码的状态了 使用While循环一直刷新判断里面的retcode,返回的数据是不规则的json数据 使用正则把里面的数据取出来,才会正常显示字体 里面的数值分表代表: 50114001:二维码未扫描状态 50114002:二维码已扫描未确认状态 20000000:二维码已确认状态 50114004:二维码已失效 附上判断代码:
url = 'https://login.sina.com.cn/sso/qrcode/check?entry=sso&qrid={}&callback=STK_{}'
while 1:
'''扫描二维码登录,每隔1秒请求一次扫码状态'''
response = s.get(url.format(self.qrid,str(time.time()*100000)),headers = self.headers)
print(response.text)
data = re.search('.*?\((.*)\)',response.text).group(1)
data_js = json.loads(data)
'''
50114001:二维码未扫描状态
50114002:二维码已扫描未确认状态
20000000:二维码已确认状态
50114004:二维码已失效
'''
print(data_js)
if '50114001' in str(data_js['retcode']):
print('二维码未使用,请扫码!')
elif '50114002' in str(data_js['retcode']):
print('已扫码,请点击确认登录!')
elif '50114004' in str(data_js['retcode']):
print('该二维码已失效,请重新运行程序!')
elif '20000000' in str(data_js['retcode']):
print('登录成功!')
alt = data_js['data']['alt']
# print(alt)
break
else:
print('其他情况',str(data_js['retcode']))
time.sleep(1)
运行结果:  可以清楚的看到,我们在没有使用微博app扫码,以及扫码成功,以及点击确认登录的状态了 但是登录成功的时候会发现返回的数据里面多了一个 alt 的东西 这个又是干嘛的呢,我们现在也不知道,可以先记一下,顺便取出来 可以清楚的看到,我们在没有使用微博app扫码,以及扫码成功,以及点击确认登录的状态了 但是登录成功的时候会发现返回的数据里面多了一个 alt 的东西 这个又是干嘛的呢,我们现在也不知道,可以先记一下,顺便取出来
这个时候又要去抓包了,看一下扫码登录之后,会出现些什么
 这个时候我们就登录上来了,可以看到有四个url里面都或多或少的包含有 set-cookies 或者是cookie 接下来就是依次访问这些url可以得到cookie了,不过这四个url怎么来的呢 我们接着来分析,先看第一个,可以发现url里面有这个alt的参数 上面我们提前取出来了,以及其他的参数,都是固定的,最后一个STK_跟15位的时间戳 这个时候我们就登录上来了,可以看到有四个url里面都或多或少的包含有 set-cookies 或者是cookie 接下来就是依次访问这些url可以得到cookie了,不过这四个url怎么来的呢 我们接着来分析,先看第一个,可以发现url里面有这个alt的参数 上面我们提前取出来了,以及其他的参数,都是固定的,最后一个STK_跟15位的时间戳   那我们这个时候就可以构造这个url,先请求一下,看看返回了什么数据 部分代码如下: 那我们这个时候就可以构造这个url,先请求一下,看看返回了什么数据 部分代码如下:
alturl = 'https://login.sina.com.cn/sso/login.php?entry=qrcodesso&returntype=TEXT&crossdomain=1&cdult=3&domain=weibo.com&alt={}&savestate=30&callback=STK_{}'
response = s.get(alturl.format(alt,str(time.time()*100000)),headers = self.headers)
print(response.text)
data = re.search('.*\((.*)\);',response.text).group(1)
print(data)
data_js = json.loads(data)
print(data_js)
登录之后是可以看见咱的用户名以及uid的,运行结果如下:
 第一次输出人眼是看不懂的,这就是不规则json显示的,第二次通过正则取出 {} 里面的数据时候就会清楚的显示了,那这个时候就会发现有3个url了 和前面拥有cookie和set-cookies的url是一样的 那这样就方便明了了,咱们直接分别请求这三个URL之后就可以获取到cookie了 值得注意的是,第二个url后面需要加上 ‘&action=login’ 才正确 接下来就是使用s.cookies.save()来保存cookie了 也可以使用pickle,不过这个我用不来 第一次输出人眼是看不懂的,这就是不规则json显示的,第二次通过正则取出 {} 里面的数据时候就会清楚的显示了,那这个时候就会发现有3个url了 和前面拥有cookie和set-cookies的url是一样的 那这样就方便明了了,咱们直接分别请求这三个URL之后就可以获取到cookie了 值得注意的是,第二个url后面需要加上 ‘&action=login’ 才正确 接下来就是使用s.cookies.save()来保存cookie了 也可以使用pickle,不过这个我用不来
import http.cookiejar as cookielib
# import pickle
先创建一个cookies.txt来作为存储,写入的是字符串 代码如下:
def get_cookies(self):
'''获取cookies,创建一个txt文件保存'''
alt = self.login()
if not os.path.exists('cookies.txt'):
with open("cookies.txt", 'w') as f:
f.write("")
s.cookies = cookielib.LWPCookieJar(filename='cookies.txt')
alturl = 'https://login.sina.com.cn/sso/login.php?entry=qrcodesso&returntype=TEXT&crossdomain=1&cdult=3&domain=weibo.com&alt={}&savestate=30&callback=STK_{}'
response = s.get(alturl.format(alt,str(time.time()*100000)),headers = self.headers)
print(response.text)
data = re.search('.*\((.*)\);',response.text).group(1)
print(data)
data_js = json.loads(data)
print(data_js)
uid = data_js['uid']
nick = data_js['nick']
print('账户名:'+nick,'\n','uid:'+uid)
crossDomainUrlList = data_js['crossDomainUrlList']
print(crossDomainUrlList)
#依次访问另外三个url
s.get(crossDomainUrlList[0],headers = self.headers)
s.get(crossDomainUrlList[1] + '&action=login', headers=self.headers)
s.get(crossDomainUrlList[2], headers=self.headers)
s.cookies.save()
这里我们就可以获取cookie下来了 那我们使用的时候可以把字符串改成字典,用parmas拼接url 转成字典代码如下;
def cookie_dict(self):
'''加载cookies'''
self.get_cookies()
cookies = cookielib.LWPCookieJar('cookies.txt')
cookies.load(ignore_discard=True, ignore_expires=True)
# 将cookie转成字典
cookie_dict = requests.utils.dict_from_cookiejar(cookies)
print('cookies字典:', cookie_dict)
return cookie_dict
运行如下:  到此咱们的整个分析过程结束了,或许还有一些小细节没有说清楚,这个呢需要大家练习的时候慢慢去发现,另外cookiejar的具体用法,大家可以自行百度 到此咱们的整个分析过程结束了,或许还有一些小细节没有说清楚,这个呢需要大家练习的时候慢慢去发现,另外cookiejar的具体用法,大家可以自行百度
下一篇文章将会附上源码以及微博账号密码的js逆向解密过程
三、总结
好好学习 天天向上 不掉头发 事业有成~
码字不易,如果本篇文章对你有帮助请点个赞,谢谢~ 作者:tiezhu vx:T14589【注明来意】 QQ交流群:735418202 可以关注微信公众号查看其他文章学习 
*注:本文为原创文章,转载文章请附上本文链接!否则将追究相关责任,请自重!谢谢!
|