| 爬取城市公交站点数据的一篇保姆级教程 | 您所在的位置:网站首页 › g665经过的站点 › 爬取城市公交站点数据的一篇保姆级教程 |
爬取城市公交站点数据的一篇保姆级教程
|
大家好,我是小一 萧萧的风在瑟瑟的吹,还是可以穿短袖的深圳,似乎也即将会变天 前几天,有一个读者在和我交流技术的时候,提出了一个小小的问题
这其实是一个很简单的事情,搁在之前,我早就分分钟写个脚本抛给他了。但是苦于最近的工作实在太多,各种文档报告写的头疼,也是拖了好几天才在上个周末抽了点时间把代码搞定了。 最近确实事情有点多,加上在和几个大佬一起组建交流群,所以也是在今天才有空写完爬虫对应的笔记教程,供大家参考学习。 如果说只是分享代码,那其实就是甩一个链接的事儿,但是这明显不符合小一我的气质 手把手教学,正式开始! 正文 今天爬取数据的链接是:https://www.8684.cn/ 这个是8684网站的网址,上面有各种公交站点、地铁站点、违章、资讯等等数据,小功能做的相当不错。 页面长这样:
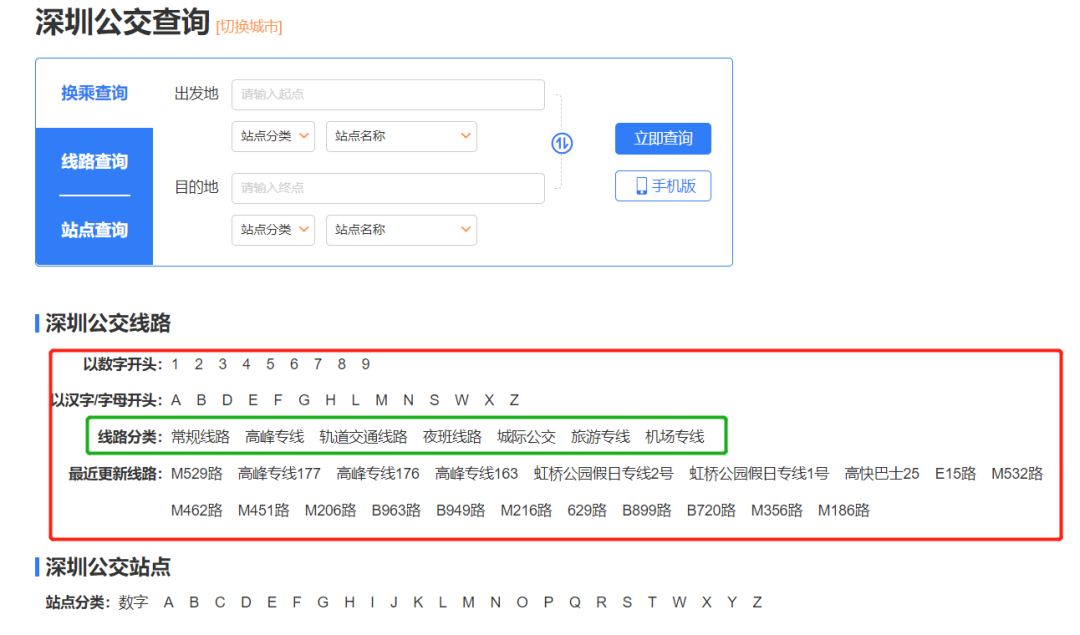
对应的我们点击热门公交中的某个城市,例如:深圳公交,注意看点击的时候网址栏发生的变化 此时的网址变成了:https://shenzhen.8684.cn/ 以此类推,其他城市对应的访问链接想必你会很容易构造出来 点进去之后的页面是这样的:
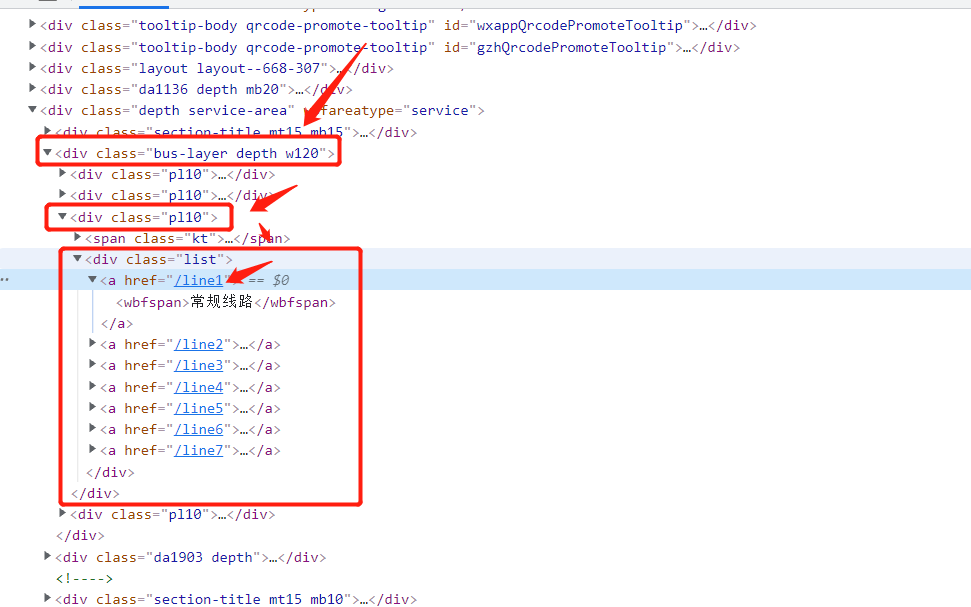
从我的经验来判断,我们想要的数据一定在红框里面。 而且从这几种网站的分类类型来看,绿框框出来的一定是最靠谱最有用的分类,而且在后期的分析过程中一定会最有用。 直接打开F12,进行源码分析(或者在某个超链接上点击右键->检查)内容一目了然:
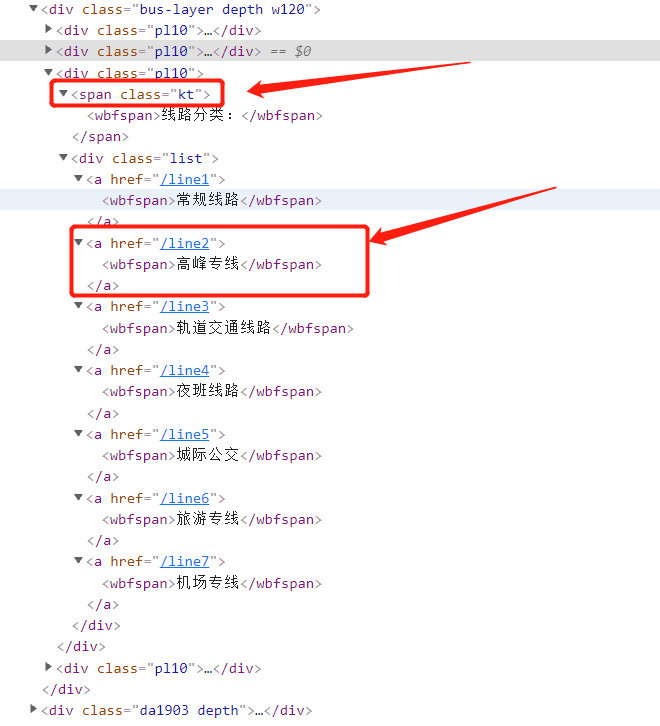
处理思路如下:定位到 bus-layer depth w120 的这个 div,然后定位到它的第三个 class为‘pl10’ 的子div,这个就是我们我们需要的线路分类 对应上面的网页显示内容,源码都展开之后是这样的:
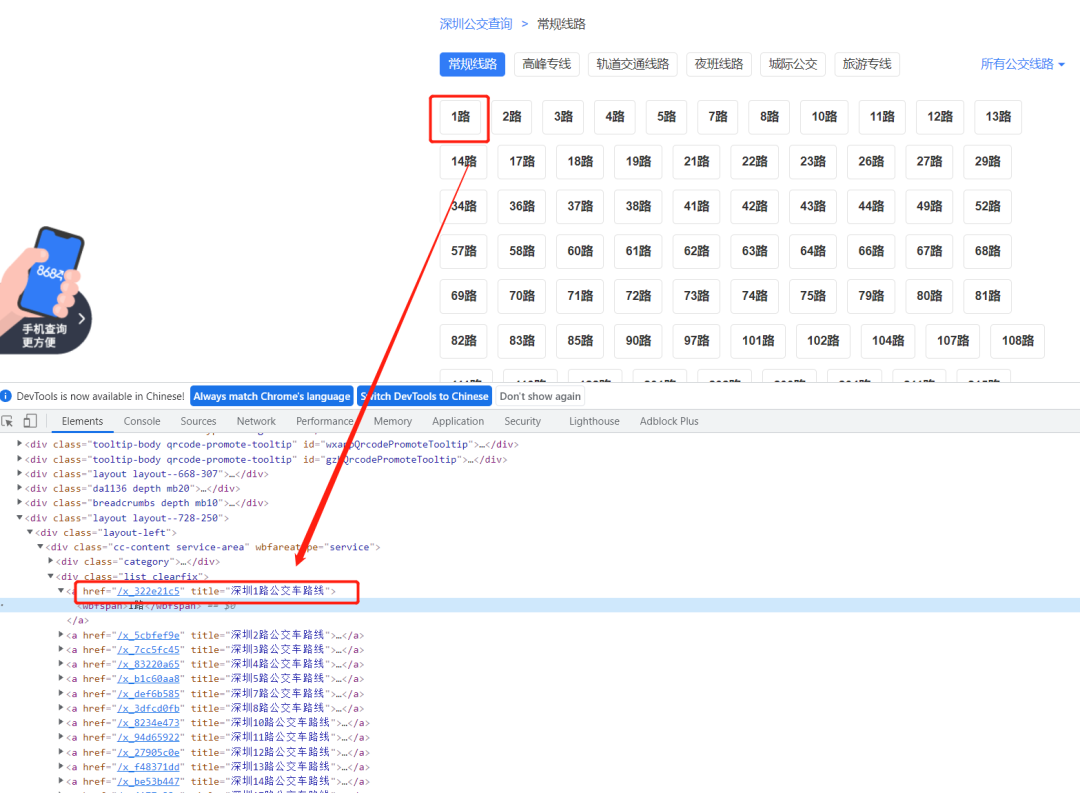
其中有两种标签:class="kt" 的span标签,对应的是分类的标题;class='list' 的div标签,子标签对应的是每一个分类的链接 href 和名称 wbfspan 标签。有用的是第二个标签。 正常点击网页上的某一种分类线路,例如:常规线路,注意看点击的时候网址栏发生的变化 此时的网址变成了:https://shenzhen.8684.cn/line1,也就是在之前链接的结尾加上上面的 href 内容 再回到我们的网页上,可以看到显示的公交路线,同样分析源码,内容如下:
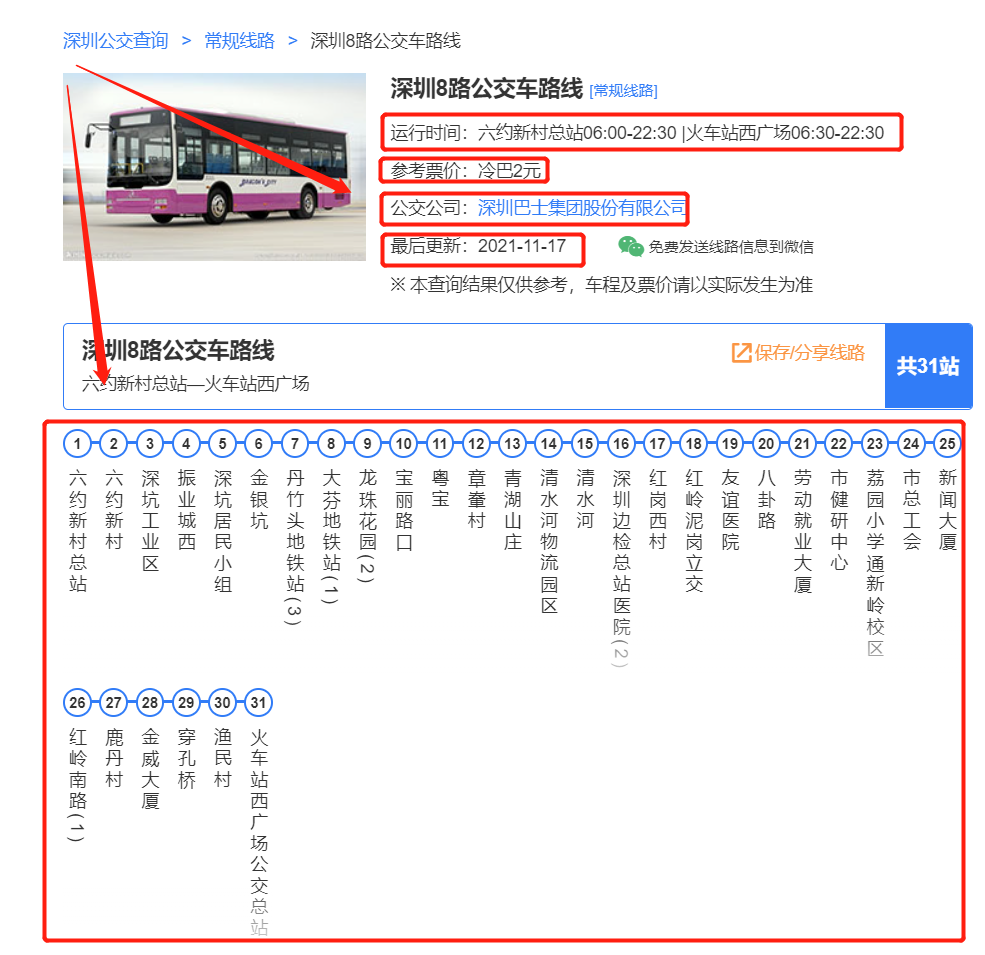
处理思路如下:定位到 list clearfix 的这个div,它下面的每一个子标签(a标签)对应的都是一条公交线路,href 同样为该公交线路的链接,wbfspan 同样为名称 随便点开某一条公交线路,例如:8号线,注意看点击的时候网址栏发生的变化 此时的网址变成了:https://shenzhen.8684.cn/x_3dfcd0fb,也就是将之前的 href 内容换成了最新的 href 内容 再回到我们的网页上,这个就是我们需要爬取数据的终极目标网页:
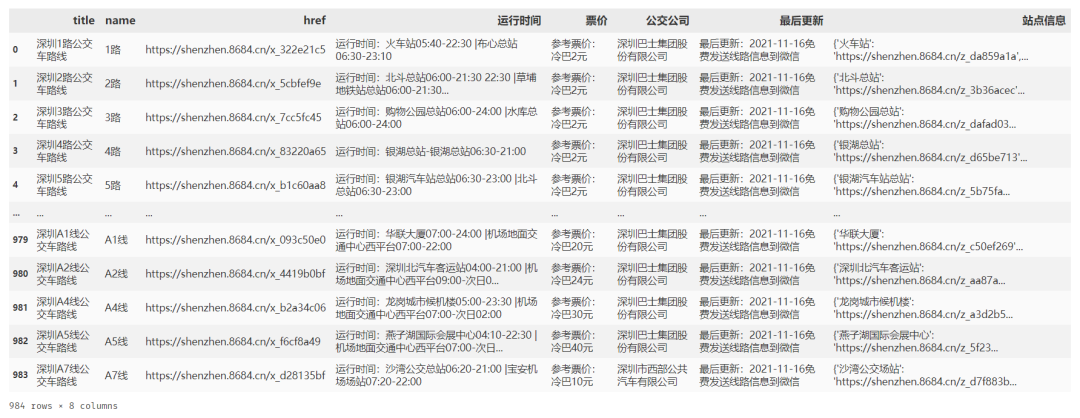
上半部分的公交详细信息:运行时间、票价、公司、更新时间等 下半部分的公交详细站点,以及每个站点的经纬度等 ok,来整理一下总体思路: 通过城市名称构造第一类访问 url 访问第一类 url 解析该城市的公交分类,获取到想要的分类类型,构造第二类访问 url 访问第二类 url 解析分类类型的每一个公交线路,构造第三类访问 url 访问第三类 url 解析该公交路线的上、下两部分数据 循环第二类 -> 第三类的过程,直到爬完所有数据 解析城市的公交分类,构造第二类访问 url 的核心代码如下: url = 'https://shenzhen.8684.cn/' response = requests.get(url=url, headers={'User-Agent': get_ua()}, timeout=10) """获取数据并解析""" soup = BeautifulSoup(response.text, 'lxml') soup_buslayer = soup.find('div', class_='bus-layer depth w120') # 解析分类数据 dic_result = {} soup_buslist = soup_buslayer.find_all('div', class_='pl10') for soup_bus in soup_buslist: name = soup_bus.find('span', class_='kt').get_text() if '线路分类' in name: soup_a_list = soup_bus.find('div', class_='list') for soup_a in soup_a_list.find_all('a'): text = soup_a.get_text() href = soup_a.get('href') dic_result[text] = "https://shenzhen.8684.cn" + href print(dic_result)上面的 dic_result 中存储的就是每一个分类的名称 text 和访问 href 对其进行遍历,即可获得每一个类型下的所有公交线路 核心代码如下: bus_arr = [] index = 0 for key,value in dic_result.items(): print ('key: ',key,'value: ',value) response = requests.get(url=value, headers={'User-Agent': get_ua()}, timeout=10) """获取数据并解析""" soup = BeautifulSoup(response.text, 'lxml') # 详细线路 soup_buslist = soup.find('div', class_='list clearfix') for soup_a in soup_buslist.find_all('a'): text = soup_a.get_text() href = soup_a.get('href') title = soup_a.get('title') bus_arr.append([title, text, "https://shenzhen.8684.cn" + href]) print(bus_arr)类似的, bus_arr 中存储的就是每一个公交路线的名称 text 和访问 href 同样的代码设计思路,遍历访问每个链接,解析最终的网页即可 最后我爬到的数据是这样的:
每个公交路线经过的站点列表我放入了一个字典,也就是上图的最后一列 对了,上述数据我没有做数据清洗,要清洗的话我建议: ①运行时间列进行拆分,构造最早发车、最晚发车、起始站、终点站 四个字段; ②票价列进行解析,识别出数字; ③最后更新列进行解析,识别出时间; ④站点信息列进行解析,统计总站点数、是否环形、经过哪些行政区等 另外,上文中提到了可以解析出站点经纬度信息,这个在上述笔记中没有写出来,感兴趣的自行摸索,或者在文末留言交流 写在最后的话 整体来说,虽然流程的设计比较繁琐,但是仍然是很基础的一篇内容 与本文相关的爬虫参数设置、简单爬虫伪装,网页解析都可以在以前的文章中找到,在此不一一提及 另外,建议大家在运行的过程中,适当的设置程序休眠,理性爬虫 本文源码和数据只能用于学习交流,不可用于商业用途,感兴趣的同学可以加小一好友备注:公交站点 获取本文源码
|
 ,所以我写了这篇笔记
,所以我写了这篇笔记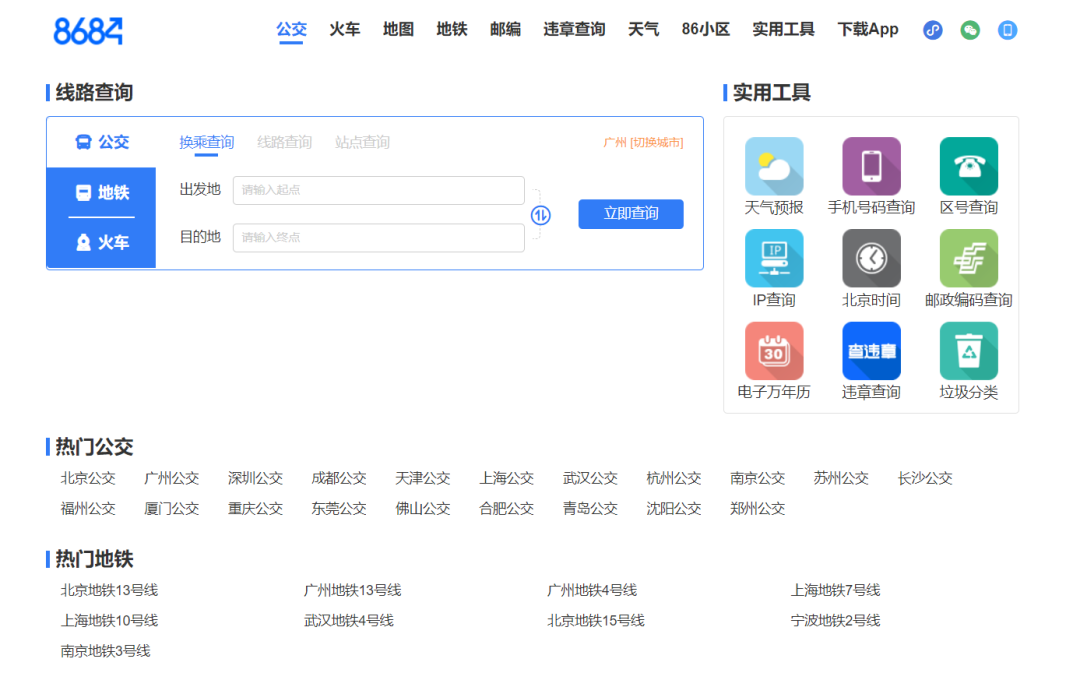
【本文地址】