| 机器学习中的数学(八):卡方分布(Chi | 您所在的位置:网站首页 › f分布图像特点 › 机器学习中的数学(八):卡方分布(Chi |
机器学习中的数学(八):卡方分布(Chi
|
前言
有很多统计推断是基于正态分布的假设,以标准正态分布变量为基石而构造的三个著名统计量在实际中有广泛的应用,这是因为这三个统计量不仅有明确背景,而且其抽样分布的密度函数有显式表达式,它们被称为统计中的“三大抽样分布”。这三大抽样分布即为著名的卡方分布,t分布和F分布。 卡方分布(Chi-squared Distribution) 卡方分布的基本描述具有k个自由度的卡方分布是一个由k个独立标准正态随机变量的和所构成的分布。卡方分布经常用于我们常见的卡方检验中。卡方检验一方面可以用来衡量观测分布和理论分布之间的拟合程度,另一方面也可以测量定性数据两个分类标准间的独立性。事实上,卡方检验还有很多其它的作用。 卡方分布的定义如果Z1,......,Zk是独立标准正态随机变量,那么这些变量的平方和就呈现出了k个自由度的卡方分布。平方和式子如下 通常,卡方分布可以表示为一下形式。 要注意的是,卡方分布只有一个参数k,k是一个正整数,表明了分布中自由度的数目。 卡方分布的概率密度函数卡方分布的概率密度函数如下:
卡方分布的其它属性
若 X ∼ t”,是伟大的Fisher为之取的名字。Fisher最早将这一分布命名为“Student's distribution”,并以“t”为之标记。 Student,则是William Sealy Gosset(戈塞特)的笔名。他当年在爱尔兰都柏林的一家酒厂工作,设计了一种后来被称为t检验的方法来评价酒的质量。因为行业机密,酒厂不允许他的工作内容外泄,所以当他后来将其发表到至今仍十分著名的一本杂志《Biometrika》时,就署了student的笔名。所以现在很多人知道student,知道t,却不知道Gosset。(相对而言,我们常说的正态分布,在国外更多的被称为高斯分布……高斯~泉下有知的话,说不定会打出V字手势~欧耶!) 在概率论和统计学中,学生t-分布(t-distribution),可简称为t分布,用于根据小样本来估计 呈正态分布且方差未知的总体的均值。如果总体方差已知(例如在样本数量足够多时),则应该用正态分布来估计总体均值。 t分布定义设随机变量 T ∼ 该密度函数的图形如下
此处 t分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df->∞时,t分布曲线为标准正态分布曲线。 若T ∼ F分布 F分布的定义 若随机变量 Z ∼
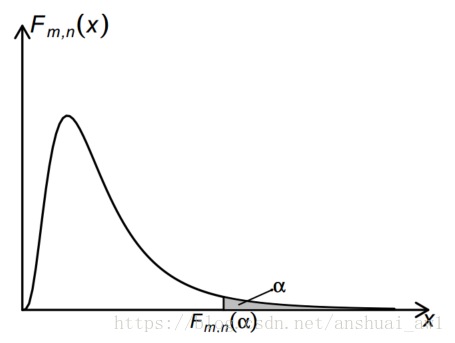
注意 F 分布的自由度 m 和 n 是有顺序的, 当 若 F ∼ 以上性质中 (1) 和 (2) 是显然的, (3) 的证明不难. 尤其性质 (3)在求区间估计和假设检验问题时会常常用到. 因为当 α 为较小的数, 如 α = 0.05 或 α = 0.01, m, n 给定时, 从已有的 F 分布表上查不到 和之值, 但它们的值可利用性质(3) 求得, 因为和是可以通过查 F 分布表求得的. 总结数据在使用前要注意采用有效的方法收集数据, 如设计好抽样方案, 安排好试验等等. 只有有效的收集了数据, 才能有效地使用数据,开展统计推断工作.获得数据后, 根据问题的特点和抽样方式确定抽样分布, 即统计模型. 基于统计模型, 统计推断问题可以按照如下的步骤进行: 1、确定用于统计推断的合适统计量; 2、寻求统计量的精确分布; 在统计量的精确分布难以求出的情形,可考虑利用中心极限定理或其它极限定理找出统计量的极限分布. 3、基于该统计量的精确分布或极限分布, 求出统计推断问题的精确解或近似解. 4、根据统计推断结果对问题作出解释 其中第二步是最重要, 但也是最困难的一步. 统计三大分布及正态总体下样本均值和样本方差的分布, 在寻求与正态变量有关的统计量精确分布时, 起着十分重要作用. 尤其在求区间估计和假设检验问题时可以看得十分清楚 附录 自由度统计学上,自由度是指当以样本的统计量来估计总体的参数时,样本中独立或能自由变化的数据的个数,称为该统计量的自由度。 直白的说,自由度是通过样本统计量来估计总体参数时必须涉及的一个基本概念,指的是计算样本统计量时能自由取值的数值个数。当做t检验时,是用样本方差去对总体方差进行估计。需要变量减去观测样本的均值,故而样本中只有n-1个自由取值。确定了n-1个数,基于均值,第n个数就确定了。所以一般来讲,丧失的自由度数目也就是需要估计的参数的数目,或者约束条件的数目。 自由度的解释: 若存在两个变量a,b,且条件是a+b=1,显然,我们只要知道其中一个数(a),另一个数(b=1-a)会依赖a的值变化而变化,所以这组数的自由度为1估计总体的平均数(有一个有4个数据(n=4)的样本,其平均值m等于5,即受到m=5的条件限制,在自由确定4、2、5三个数据后, 第四个数据只能是9,否则 伽玛函数(Gamma Function)作为阶乘的延拓,是定义在复数范围内的亚纯函数,通常写成 (1)在实数域上伽玛函数定义为: (2)在复数域上伽玛函数定义为: 其中 (3)除了以上定义之外,伽马函数公式还有另外一个写法: 我们都知道 (4)伽马函数还可以定义为无穷乘积: 为方便讨论正态总体样本均值和样本方差的分布, 我们先给出正态随机变量的线性函数的分布. 正态变量线性函数的分布 正态变量样本均值和样本方差的分布 正态变量样本均值和样本方差的分布
下述定理给出了正态变量样本均值和样本方差的分布和它们的独立性. 5 几个重要推论 下面几个推论在正态总体区间估计和假设检验问题中有着重要应用. 参考原文:https://blog.csdn.net/anshuai_aw1/article/details/82735201#2%20t分布 |



 表示的是一个gamma函数,它是整数k的封闭形式。
表示的是一个gamma函数,它是整数k的封闭形式。










 自由度为 m, n 的 F 分布的密度函数如下图:
自由度为 m, n 的 F 分布的密度函数如下图: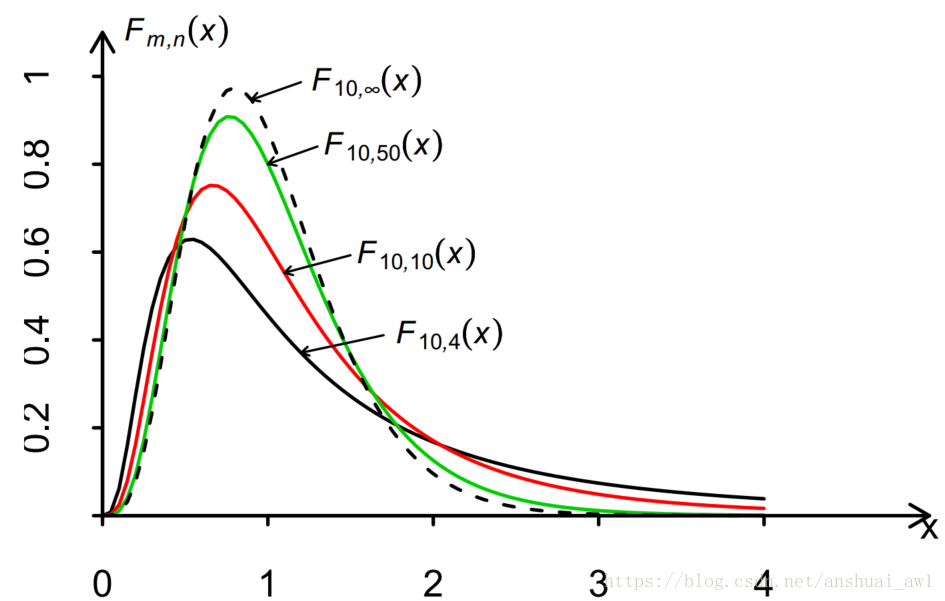









【本文地址】