| 深度学习基础知识(七) | 您所在的位置:网站首页 › fuse怎么发音 › 深度学习基础知识(七) |
深度学习基础知识(七)
|
在之前网络结构模型的介绍中,我们提到过利用重参数提升网络性能。 结构重参数化指的是首先构造一个结构用于训练,然后在推理阶段将参数等价转换为另一组参数。这样在训练过程中我们可以利用较大开销,但是在推理阶段使用小开销。也可以理解微重参数化结构在训练阶段加入了一些可以在推理阶段去掉的参数。 本文重点介绍重参数的理论和实现。先跟着论文ACNet续作重温下卷积的一些特性和多分支转换。 卷积的特性回顾了卷积的两大特性可加性和同质性。 假设输入I,输出O,卷积操作*,卷积核F_1和F_2,偏置项b,广播后偏置项REP(b)。 可加性 I * K_1 + I*K_2= I*(K_1+K_2) 两个并行卷积核处理结果相加,等于两个卷积核相加后再进行卷积操作。 同质性 I (pK) = p(I * K) 卷积核乘以一个常数后进行卷积操作,等于对卷积操作结果乘以常数。 多分支转换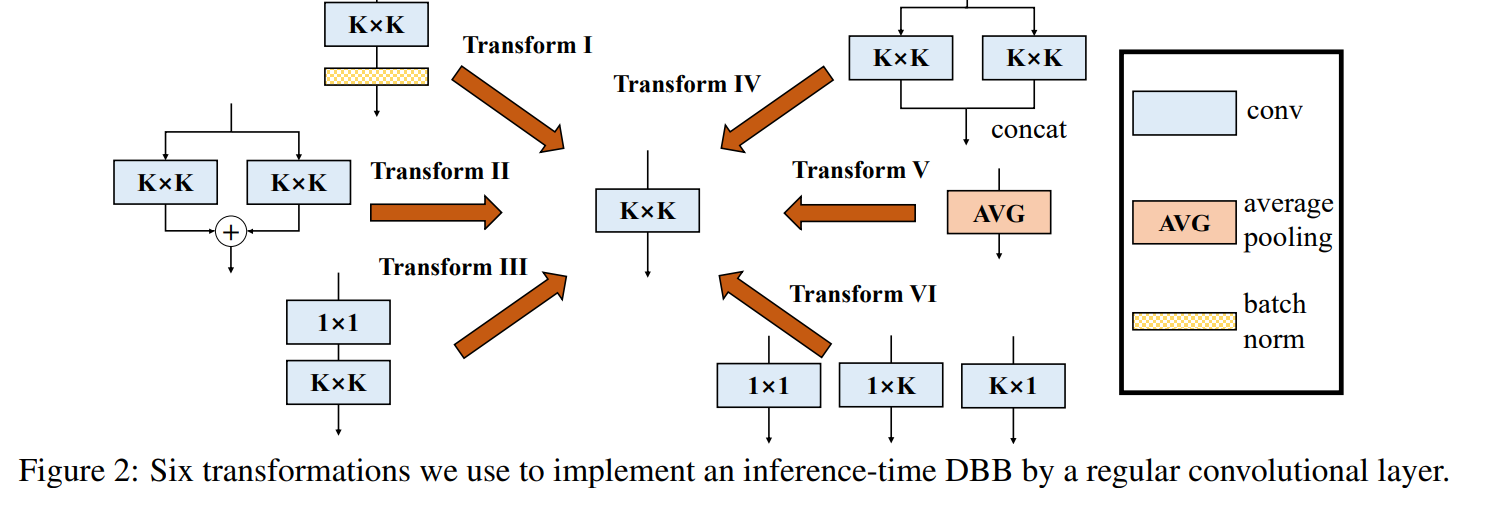 转换一 Conv+BN融合 卷积层和BN层结合,这个处理在前向计算的框架中比较常见。 卷积操作 O=I*F+REP(b)BN操作 BN(x)= \gamma \frac {x-mean}{\sqrt{var} }+\beta 卷积带入BN操作 BN(conv(x))= \gamma* \frac {I*F+REP(b)-mean}{\sqrt{var} }+\beta利用同质性 BN(conv(x))= I*(\frac{\gamma F}{\sqrt {var}}) +\frac{\gamma (REP(b)-mean)}{\sqrt {var}} +\beta等同于新的卷积操作,权重为\frac{\gamma F}{\sqrt {var}} ,偏置为\frac{\gamma (REP(b)-mean)}{\sqrt {var}} +\beta 转换二 卷积相加 就是利用可加性 卷积操作 O1=I*F_1+REP(b_1),O2=I*F_2+REP(b_2) 卷积并行相加结果 O=I*(F_1+F_2)+(REP(b_2)+REP(b_1))等同新的卷积操作,权重F_1+F_2,偏置REP(b1)+REP(b2) 转换三 序列卷积融合 网络结构中通常会有1*1卷积减少通道数,再接3*3卷积的操作。公式如下 O=(I*F_1+REP(b_1))*F_2+REP(b_2)利用相加性 O=I*F_1*F_2+REP(b_1)*F_2+REP(b_2)假设F1(C_{out1},C_{in},1,1),F2(C_{out2},C_{out1},k,k)。作者提出将F_1卷积核进行一次转换 F_1(C_{out1},C_{in},1,1)-->F_{trans}(C_{in},C_{out1},1,1)将F_2 作为输入和F_{trans} 进行卷积得到(C_{out2},C_{in},k,k) 等同于新的卷积操作,权重F_2 * F{trans} ,偏置REP(b1)*F2+REP(b_2) 转换四 拼接融合 CONCAT(I*F_1+REP(b_1),I*F_2+REP(b_2))=I*F+REB(b)两个卷积操作的拼接等同于将卷积核进行拼接,此处F即CONCAT(F_1,F_2) 转换五 平均池化层转换 平均池化操作是对每个通道通过一个滑动窗口求出平均值;卷积操作是对每个通道通过一个滑动窗口卷积再将结果相加。 平均池化可以转化为权重固定1/K*K,窗口大小为k*k的卷积核,而且需要对非当前通道权重设置为0(因为卷积操作是要对所有通道操作后相加)。 转换六 多尺度卷积融合 对于卷积核 k_h \times k_w(k_h \le k,K_w \le K) 等同于将卷积核通过补0的方式来等效K \times K 。 代码实现下面我们代码实现以上六种转换。 import torch from torch import nn from torch.nn import functional as F def transI_conv_bn(conv, bn): std = (bn.running_var + bn.eps).sqrt() gamma = bn.weight weight = conv.weight * (gamma/std).reshape(-1,1,1,1) if(conv.bias is not None): bias = bn.bias - gamma/std *bn.running_mean else: bias = bn.bias - gamma/std * bn.running_mean return weight, bias def transII_conv_branch(conv1, conv2): weight = conv1.weight.data + conv2.weight.data bias = conv1.bias.data + conv2.bias.data return weight, bias def transIII_conv_sequential(conv1, conv2): weight = F.conv2d(conv2.weight.data, conv1.weight.data.permute(1,0,2,3)) return weight def transIV_conv_concat(conv1, conv2): weight = torch.cat([conv1.weight.data, conv2.weight.data], 0) bias = torch.cat([conv1.bias.data, conv2.bias.data], 0) return weight, bias def transV_avg(channel, kernel): conv = nn.Conv2d(channel, channel, kernel, bias=False) conv.weight.data[:] = 0 for i in range(channel): conv.weight.data[i,i,:,:] = 1/(kernel*kernel) return conv def transVI_conv_scale(conv1, conv2, conv3): weight = F.pad(conv1.weight.data, (1,1,1,1)) +F.pad(conv2.weight.data,(0,0,1,1)) + F.pad(conv3.weight.data, (1,1,0,0)) bias = conv1.bias.data + conv2.bias.data + conv3.bias.data return weight, bias def test_convI(): input = torch.rand(1, 64, 7, 7) conv1 = nn.Conv2d(64, 64, 3, padding=1) bn1 = nn.BatchNorm2d(64) bn1.eval() out1 = bn1(conv1(input)) conv_fuse = nn.Conv2d(64, 64, 3, padding=1) conv_fuse.weight.data, conv_fuse.bias.data = transI_conv_bn(conv1, bn1) out2 = conv_fuse(input) print("difference:", ((out2 - out1) ** 2).sum().item()) def test_convII(): input = torch.randn(1, 64, 7, 7) conv1 = nn.Conv2d(64, 64, 3, padding=1) conv2 = nn.Conv2d(64, 64, 3, padding=1) out1 = conv1(input) + conv2(input) conv_fuse = nn.Conv2d(64, 64, 3, padding=1) conv_fuse.weight.data, conv_fuse.bias.data = transII_conv_branch(conv1,conv2) out2 = conv_fuse(input) print("difference:", ((out2 - out1) ** 2).sum().item()) def test_convIII(): input = torch.randn(1, 64, 7, 7) conv1 = nn.Conv2d(64, 64, 1, padding=0, bias=False) conv2 = nn.Conv2d(64, 64, 3, padding=1, bias=False) out1 = conv2(conv1(input)) conv_fuse = nn.Conv2d(64, 64, 3, padding=1, bias=False) conv_fuse.weight.data = transIII_conv_sequential(conv1, conv2) out2 = conv_fuse(input) print("difference:", ((out2 - out1) ** 2).sum().item()) def test_convIV(): input = torch.randn(1, 64, 7, 7) conv1 = nn.Conv2d(64, 32, 3, padding=1) conv2 = nn.Conv2d(64, 32, 3, padding=1) out1 = torch.cat([conv1(input), conv2(input)], dim=1) conv_fuse=nn.Conv2d(64, 64, 3, padding=1) conv_fuse.weight.data, conv_fuse.bias.data = transIV_conv_concat(conv1, conv2) out2=conv_fuse(input) print("difference:", ((out2 - out1) ** 2).sum().item()) def test_convV(): input = torch.randn(1, 64, 7, 7) avg = nn.AvgPool2d(kernel_size=3, stride=1) out1 = avg(input) conv = transV_avg(64, 3) out2 = conv(input) print("difference:", ((out2 - out1) ** 2).sum().item()) def test_convVI(): input = torch.randn(1, 64, 7, 7) conv1x1 = nn.Conv2d(64, 64, 1) conv1x3 = nn.Conv2d(64, 64, (1, 3), padding=(0, 1)) conv3x1 = nn.Conv2d(64, 64, (3, 1), padding=(1, 0)) out1 = conv1x1(input) + conv1x3(input) + conv3x1(input) conv_fuse = nn.Conv2d(64, 64, 3, padding=1) conv_fuse.weight.data, conv_fuse.bias.data = transVI_conv_scale(conv1x1, conv1x3, conv3x1) out2 = conv_fuse(input) print("difference:", ((out2 - out1) ** 2).sum().item())
参考 https://zhuanlan.zhihu.com/p/360939086 https://cloud.tencent.com/developer/article/1840919 https://github.com/xmu-xiaoma666/External-Attention-pytorch |
【本文地址】