| EViews教程 | 您所在的位置:网站首页 › eviews怎么做模型残差图 › EViews教程 |
EViews教程
|
ARMA模型
2024 | 10937 | 7 | 0
ARMA(Autoregressive Moving Average,自回归移动平均)模型是应用最广的时间序列模型(time series model)。在教科书中,ARMA(p,q)模型一般会写为:$$y_t = \beta_0 +\sum_{i=1}^p \beta_i y_{t-i} + e_t + \sum_{i=1}^q \gamma_i e_{t-i} $$其中,误差\(e_t\)是一个零期望的白噪声。这一模型是用于平稳时间序列的最基础的预测模型。 注意,时间序列模型和前面讲的时间序列回归模型不一样。时间序列模型研究的是时间序列数据的生成机制,而时间序列回归模型研究的是一个时间序列变量如何受其他变量影响。前者应用的目标主要是做预测,后者应用的最高目标是探寻因果关系。 白噪声检验ARMA模型的建模,最关键的一步是确定p和q的取值。如果一条时间序列经由单位根检验(见[分析预备]一讲)显示可能是平稳的,在进行ARMA建模之前,白噪声检验是必不可少的。这是因为,如果序列本身是白噪声,就无需再讨论p和q应该是多少(它们都为0),此时,历史数据的样本平均就是对未来最好的预测。 最流行的白噪声检验是Ljung–Box Q检验。以[数据导入]一讲练习中生成的demo.wf1为例,如果我们想要对gdp的对数差分进行白噪声检验,只需使用命令correl: series dlgdp = dlog(gdp) dlgdp.correl(12)括号中的数字指检验数据的前12阶自相关系数都为0,可以设为其他值。检验的结果如下: 
其中,Q统计量列在右侧Q-Stat一栏,从上到下依次对应检验数据的前k阶自相关系数都为0(k = 1、…、12)。Q-Stat右侧的Prob一栏是对应检验的p值。 相关图(correlogram)相关图是ARMA建模中进行模型识别(model identification)的重要工具。模型识别,即估计模型前确定p和q的过程。 上面的图的左侧就是时间序列的相关图:Autocorrelation一栏是自相关图;Partial Correlation一栏是偏自相关图;AC一栏是前12阶自相关系数的数值;PAC是偏自相关系数的数值。相关图中,中线两侧的两条小竖线对应±2除以样本量的平方根,在正态分布假设下,这对应95.45%的置信区间。 在EViews中,获取序列的相关图或Q统计量的鼠标操作为:在series对象窗口左上选View/Correlogram,然后在弹出的窗口选择是使用原始的数据(level)?还是使用数据的一阶差分或二阶差分?并输入要报告的自相关系数的最大阶数。 模型估计确定了p和q后,就可以估计模型了。EViews估计ARMA模型仍然使用ls命令,但是,EViews默认使用的估计方法是最大似然法(maximum likelihood)。我的建议是,不要用最大似然法,理由有二:一、最大似然法假设模型误差为正态分布,很多时候这是不靠谱的;二、正态假设同时意味着同方差假设,很多时候这也是不靠谱的。相比最大似然法,最小二乘法是更靠谱的估计方法。 使用最小二乘法估计ARMA模型需要用到命令ls的可选参数arma,令其等于cls即是告诉EViews用最小二乘法,cls即conditional least squares之意。看看下面的例子: equation eq1 eq1.ls(arma=cls,cov=white) dlgdp c ar(1 to 2) ma(1)上面的代码估计了一个ARMA(2,1)模型。如果缺少可选参数arma,ls会实施最大似然估计,此时,cov=white是无效的,原因如上所述。ar(1 to 2)表示模型自回归部分包含序列的一到二阶滞后,在代码中,ar(1 to 2)也可写为ar(1) ar(2)。ma(1)表示模型移动平均部分仅包含误差的一阶滞后。注意,代码中的c不是指截距,而是指平稳时间序列的期望,所以,EViews实际上估计的是以下模型:$$\dot{y}_t = \beta_1 \dot{y}_{t-1} + \beta_2 \dot{y}_{t-2} + e_t + \gamma_1 e_{t-1}$$ $$\dot{y}_t = y_t – \mu$$ $$y_t = log(gdp_t) – log(gdp_{t-1})$$代码中的c即是这里的\(\mu\)。在EViews中,命令ls是不会估计ARMA模型的截距的。 模型的估计结果如下图所示: 
报告的第二行显示估计的方法是最小二乘法,第六行显示最优化过程是收敛的,第七行显示使用了异方差一致的协方差矩阵。除了红线与红框的部分,其他内容前面的教程都介绍过,我就不再重复了。 如果估计的模型里含有移动平均部分,使用最小二乘估计就需要提前设定移动平均部分白噪声的初始值,红线显示了设定初始值的默认方法:Backcasting。EViews还提供了另一种设定方法:把白噪声的所有初始值设为0,要使用这种设定,你只需加上可选参数z: equation eq2 eq2.ls(arma=cls,z,cov=white) dlgdp c ar(1 to 2) ma(1)估计完模型后,你就会发现红线的部分会显示MA Backcast: OFF,表示没有使用Backcasting。红框部分报告了ARMA模型自回归部分特征方程的逆根与移动平均部分特征方程的逆根,它们分别决定了模型是否是平稳的、是否是可逆的。 模型诊断估计完一个ARMA模型后,至少要做两个诊断检验来判断模型的设定是否有问题。一个检验是通过模型的特征方程的逆根来检查估计的模型是否是平稳可逆的:所有逆根都在单位圆内(即模都小于1)则表明模型是平稳可逆的。这是一个非正式的“检验”,因为它没有用到统计检验的技术。估计完模型后,利用命令arma就能实施这一检验: eq1.arma '注意,这里的arma不是上面说的可选参数代码执行的效果如下: 
图中蓝色空心的点是模型自回归部分特征方程的逆根,橙色实心的点是模型移动平均部分特征方程的逆根,它们都在单位圆内,因此,模型是平稳可逆的。 另一个必做的诊断检验是模型误差的白噪声检验,如果误差不是白噪声,模型就会有内生性问题,最小二乘估计和最大似然估计都无法得到一致的估计量。这种情况下,一般可以通过增大自回归或移动平均部分的滞后阶数来“修正”模型。 比较流行白噪声检验的还是Ljung–Box Q检验,使用的命令仍是correl: eq1.correl(12)代码执行的结果如下: 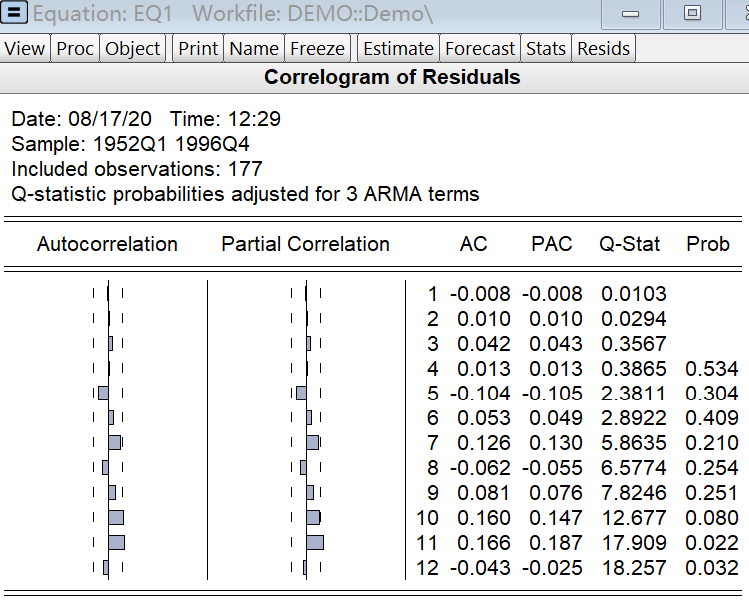
由于使用的数据是残差而不是真实的误差,Q统计量的分布(卡方分布)的自由度会进行调整,所以,如你所见,这里的前三阶Q检验的p值是没有的,因此,只有第四阶开始的Q统计量才是可用的。 进行上述两个诊断检验的鼠标操作为:在equation对象窗口左上选ARMA Structure或View/Residual Diagnostics/Correlogram – Q-statistics。 命令复习 (.)ls(arma=cls):对ARMA模型实施最小二乘估计 .corrle(12):显示数据或模型残差的相关图和Q统计量 .arma:显示ARMA模型的特征方程的逆根的结构[注] ( . )命令表示命令可单独使用,也可跟在对象后使用;.命令表示命令只能跟在对象后使用。 练习 对demo.wf1中的变量m1,取其对数差分作为一个变量,重复一遍上述的各项操作。 内生性 预测 读后有收获欢迎打赏站长吃两个牛舌饼😂
 点赞
扫一扫,点右上角⋯分享
给站长留言 取消回复
点赞
扫一扫,点右上角⋯分享
给站长留言 取消回复
|
【本文地址】