| 【编译、链接、装载十三】内存中的栈 | 您所在的位置:网站首页 › csgo的运行内存是多少 › 【编译、链接、装载十三】内存中的栈 |
【编译、链接、装载十三】内存中的栈
|
【编译、链接、装载十三】内存中的栈——图解栈的运行过程
一、程序的内存布局二、栈1、什么是栈2、寄存器
三、函数执行四、结合汇编——分析函数调用1、demo2、反汇编3、反汇——图解反汇编、栈帧、寄存器
一、程序的内存布局
看看加上动态链接之后进程的地址空间是如何分布的。现代的应用程序都运行在一个内存空间里, 在32位的系统里, 这个内存空间拥有4GB(2的32次方) 的寻址能力。 用户可以使用一个32位的指针访问任意内存位置。 例如: int p = (int)0x12345678; ++*p; 这段代码展示了如何直接读写指定地址的内存数据。 大多数操作系统都会将4GB的内存空间中的一部分挪给内核使用, 应用程序无法直接访问这一段内存, 这一部分内存地址被称为内核空间。 Windows在默认情况下会将高地址的2GB空间分配给内核(也可配置为1GB) , 而Linux默认情况下将高地址的1GB空间分配给内核, 一般来讲, 应用程序使用的内存空间里有如下“默认”的区域。 栈: 栈用于维护函数调用的上下文, 离开了栈函数调用就没法实现。后面将对栈作详细的介绍。 栈通常在用户空间的最高地址处分配,通常有数兆字节的大小。 堆: 堆是用来容纳应用程序动态分配的内存区域, 当程序使用malloc或new分配内存时, 得到的内存来自堆里。堆会后面详细介绍。 堆通常存在于栈的下方(低地址方向) , 在某些时候, 堆也可能没有固定统一的存储区域。 堆一般比栈大很多, 可以有几十至数百兆字节的容量。 可执行文件映像: 这里存储着可执行文件在内存里的映像,前面已经提到过,由装载器在装载时将可执行文件的内存读取或映射到这里。在此不再详细说明。 保留区: 保留区并不是一个单一的内存区域, 而是对内存中受到保护而禁止访问的内存区域的总称,例如, 大多数操作系统里, 极小的地址通常都是不允许访问的, 如NULL。 通常C语言将无效指针赋值为0也是出于这个考虑, 因为0地址上正常情况下不可能有有效的可访问数据。 下图是Linux下一个进程里典型的内存布局。 栈(stack) 是现代计算机程序里最为重要的概念之一, 几乎每一个程序都使用了栈, 没有栈就没有函数, 没有局部变量, 也就没有我们如今能够看见的所有的计算机语言。 在经典的计算机科学中, 栈被定义为一个特殊的容器, 用户可以将数据压入栈中(入栈, push) , 也可以将已经压入栈中的数据弹出(出栈,pop) , 但栈这个容器必须遵守一条规则: 先入栈的数据后出栈(First In Last Out, FIFO) 在计算机系统中, 栈则是一个具有以上属性的动态内存区域。 程序可以将数据压入栈中, 也可以将数据从栈顶弹出。 压栈操作使得栈增大, 而弹出操作使栈减小。 在经典的操作系统里, 栈总是向下增长的。 在栈上压入数据会导致esp减小,弹出数据使得esp增大。相反,直接减小esp的值也等效于在栈上开辟空间,直接增大esp的值等效于在栈上回收空间。 栈在程序运行中具有举足轻重的地位。最重要的,栈保存了一个函数调用所需要的维护信息,这常常被称为堆栈帧(Stack Frame)或活动记录(Activate Record)。 堆栈帧一般包括如下几方面内容: 函数的返回地址和参数。临时变量:包括函数的非静态局部变量以及编译器自动生成的其他临时变量。保存的上下文:包括在函数调用前后需要保持不变的寄存器。 2、寄存器在x86系统的CPU中,rsp是栈指针寄存器,这个寄存器中存储着栈顶的地址。 rbp中存储着栈底的地址。 函数栈空间主要是由这两个寄存器来确定的。当程序运行时,栈指针RSP可以移动,栈指针和帧指针rbp一次只能存储一个地址,所以,任何时候,这一对指针指向的是同一个函数的栈帧结构。而帧指针rbp是不移动的,访问栈中的元素可以用-4(%rbp)或者8(%rbp)访问%rbp指针下面或者上面的元素。 ebp固定在图中所示的位置,不随这个函数的执行而变化,相反地,esp始终指向栈顶,因此随着函数的执行,esp会不断变化。固定不变的ebp可以用来定位函数活动记录中的各个数据。 总结 这些寄存器是cup中的,不是内存。寄存器存的是内存地址。通过这个地址来操作。rsb、rbp等这些寄存器只有一个。一个rsb,一个rbp.rsp,存储的地址是变动的。rbp,栈底的地址是不变的,但是可以通过-4(%rbp)访问局部变量。 三、函数执行函数总是这样调用的: 把所有或一部分参数压入栈中, 如果有其他参数没有入栈, 那么使用某些特定的寄存器传递。把所有或一部分参数压入栈中, 如果有其他参数没有入栈, 那么使用某些特定的寄存器传递。把当前指令的下一条指令的地址压入栈中。跳转到函数体执行。其中第2步和第3步由指令call一起执行。 跳转到函数体之后即开始执行函数, 而i386函数体的“标准”开头是这样的(但也可以不一样) : 第1步push ebp: 把ebp的值压入栈中(把上一个函数栈帧的栈底的值,也就是rbp的值,压入栈中。) 。 第2步mov ebp, esp: ebp = esp(这时ebp保存的值指向栈顶, 而且我们之前说过,栈顶是变化的) 。我们上一步把ebp的值保存了,现在又给ebp赋了新值,新值是啥呢?当然就是那个变动的栈帧的值了。 第3步【可选】 sub esp, XXX: 在栈上分配XXX字节的临时空间。这个空间的大小和这个程序内的局部变量的多少有关系的,不包括调用的函数。我做过实验,如果被调用函数比较简单,没有调用其他的话,可能就没有这一句,也就是不用分配临时空间。 分了临时空间,栈顶的值就又变了呵。比如sub $0x10,%rsp $0x10代表16个字节的空间,rsp-10,就是新的rsp的值了。 这个值是以16字节递增的,比如你的临时变量用10个字节,那么就会分16个字节,如果用了20个字节,那么就会分32个字节。 四、结合汇编——分析函数调用 1、demo #include int g_y =2; int add(int a,int b) { int c = a+b; printf("c = %d",c); return c; } int main() { int x = 1; int stack1 = 1; int stack2= 1; int sum = add(x,g_y); printf("sum = %d",sum); return 1; } 2、反汇编 [dev1@localhost test]$ gcc main.c [dev1@localhost test]$ objdump -d -x a.out 00000000004004d7 : 4004d7: 55 push %rbp 4004d8: 48 89 e5 mov %rsp,%rbp 4004db: 48 83 ec 20 sub $0x20,%rsp 4004df: 89 7d ec mov %edi,-0x14(%rbp) 4004e2: 89 75 e8 mov %esi,-0x18(%rbp) 4004e5: 8b 55 ec mov -0x14(%rbp),%edx 4004e8: 8b 45 e8 mov -0x18(%rbp),%eax 4004eb: 01 d0 add %edx,%eax 4004ed: 89 45 fc mov %eax,-0x4(%rbp) 4004f0: 8b 45 fc mov -0x4(%rbp),%eax 4004f3: 89 c6 mov %eax,%esi 4004f5: bf f0 05 40 00 mov $0x4005f0,%edi 4004fa: b8 00 00 00 00 mov $0x0,%eax 4004ff: e8 ec fe ff ff callq 4003f0 400504: 8b 45 fc mov -0x4(%rbp),%eax 400507: c9 leaveq 400508: c3 retq 0000000000400509 : 400509: 55 push %rbp 40050a: 48 89 e5 mov %rsp,%rbp 40050d: 48 83 ec 10 sub $0x10,%rsp 400511: c7 45 fc 01 00 00 00 movl $0x1,-0x4(%rbp) 400518: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp) 40051f: c7 45 f4 01 00 00 00 movl $0x1,-0xc(%rbp) 400526: 8b 15 f8 0a 20 00 mov 0x200af8(%rip),%edx # 601024 40052c: 8b 45 fc mov -0x4(%rbp),%eax 40052f: 89 d6 mov %edx,%esi 400531: 89 c7 mov %eax,%edi 400533: e8 9f ff ff ff callq 4004d7 400538: 89 45 f0 mov %eax,-0x10(%rbp) 40053b: 8b 45 f0 mov -0x10(%rbp),%eax 40053e: 89 c6 mov %eax,%esi 400540: bf f7 05 40 00 mov $0x4005f7,%edi 400545: b8 00 00 00 00 mov $0x0,%eax 40054a: e8 a1 fe ff ff callq 4003f0 40054f: b8 01 00 00 00 mov $0x1,%eax 400554: c9 leaveq 400555: c3 retq 400556: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1) 40055d: 00 00 00 3、反汇——图解反汇编、栈帧、寄存器《程序员的自我修养》这本书挺好的,但是这个章节的分析,不少地方很容易让人误解和曲解,所以,我就不贴里面的图和分析了。 我们从main函数开始分析。 push %rbp: 将 %rbp 寄存器的值压入栈,为后续的函数调用准备栈帧。 400509: 55 push %rbp 图解:内存的那里我写了rbp,是想表达rbp寄存器存的值是这个位置,为了大家更好的理解。并非说寄存器在内存中,这里大家心中明白就行,后面我不再单独说明了。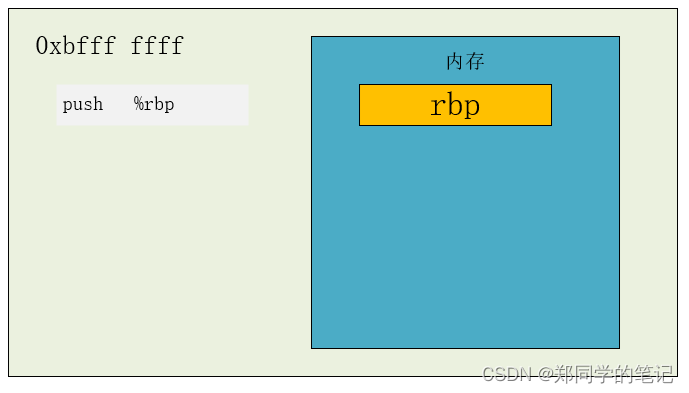 mov %rsp,%rbp: 将当前栈指针 %rsp 的值复制到基址指针 %rbp,建立当前函数的栈帧。
40050a: 48 89 e5 mov %rsp,%rbp
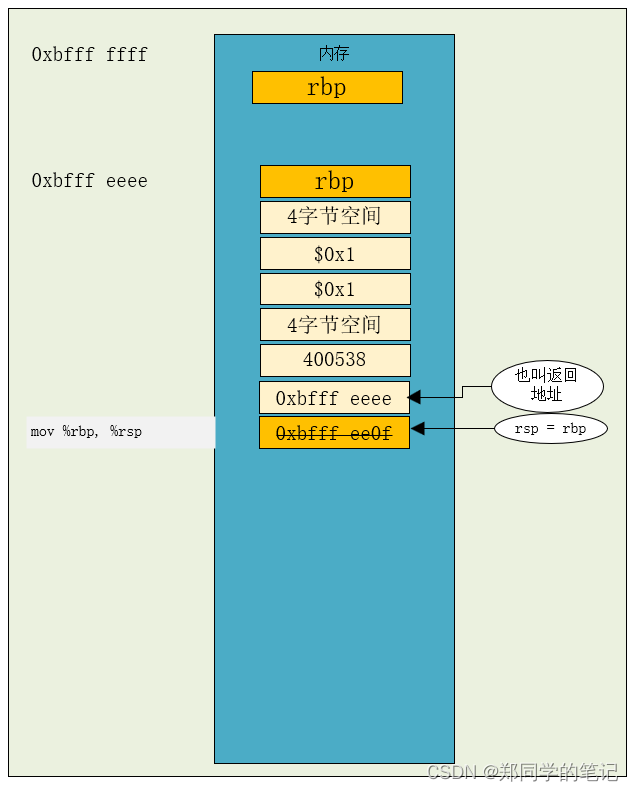
图解:我们假设,rsp的值就在图中的位置
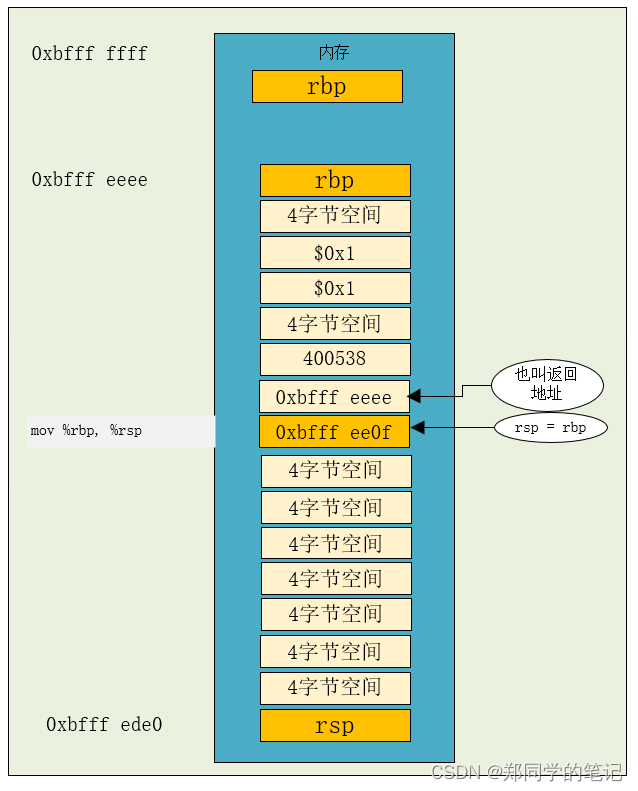
mov %rsp,%rbp: 将当前栈指针 %rsp 的值复制到基址指针 %rbp,建立当前函数的栈帧。
40050a: 48 89 e5 mov %rsp,%rbp
图解:我们假设,rsp的值就在图中的位置 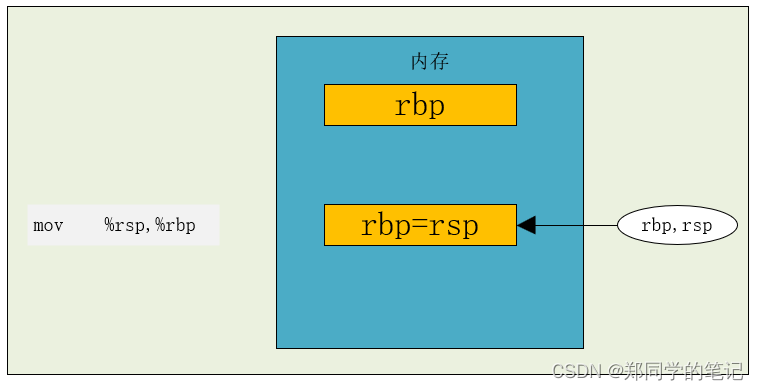 sub $0x10,%rsp: 从栈指针 %rsp 中减去 16 字节(0x10),为局部变量分配空间。这创建了一个大小为 16 字节的栈帧。
40050d: 48 83 ec 10 sub $0x10,%rsp
图解
sub $0x10,%rsp: 从栈指针 %rsp 中减去 16 字节(0x10),为局部变量分配空间。这创建了一个大小为 16 字节的栈帧。
40050d: 48 83 ec 10 sub $0x10,%rsp
图解 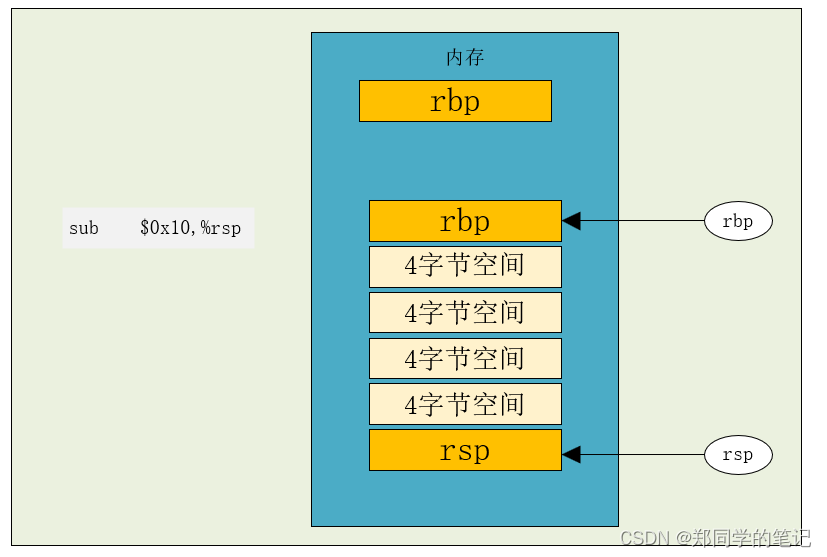
sub $0x10,%rsp会改变栈顶的值吗 ChatGPT 是的,sub $0x10,%rsp 指令会改变栈顶的值。这条指令的作用是将栈指针 %rsp 的值减去 16 字节(0x10),以在栈上为局部变量分配空间。 由于栈向下增长,减去一个较小的值(16 字节)将使栈指针向下移动,即将栈顶指针向下推移。这样,栈顶的位置会向较低的地址移动,为新分配的局部变量提供空间。 在这种情况下,sub $0x10,%rsp 指令会将栈顶指针向下移动 16 字节,为后续的局部变量分配提供空间。 movl $0x1,-0x4(%rbp): 将值 1 存储在相对于 %rbp 偏移为 -4 的位置,即在栈帧中分配一个 4 字节的整数变量。 400511: c7 45 fc 01 00 00 00 movl $0x1,-0x4(%rbp) 图解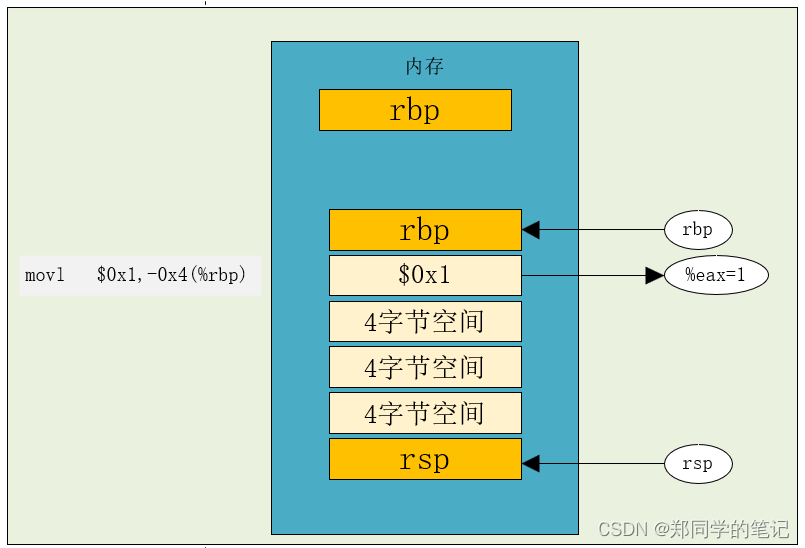 movl $0x1,-0x8(%rbp): 将值 1 存储在相对于 %rbp 偏移为 -8 的位置,再分配一个 4 字节的整数变量。
400518: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp)
movl $0x1,-0xc(%rbp): 将值 1 存储在相对于 %rbp 偏移为 -12 的位置,分配一个额外的 4 字节的整数变量。
40051f: c7 45 f4 01 00 00 00 movl $0x1,-0xc(%rbp)
图解
movl $0x1,-0x8(%rbp): 将值 1 存储在相对于 %rbp 偏移为 -8 的位置,再分配一个 4 字节的整数变量。
400518: c7 45 f8 01 00 00 00 movl $0x1,-0x8(%rbp)
movl $0x1,-0xc(%rbp): 将值 1 存储在相对于 %rbp 偏移为 -12 的位置,分配一个额外的 4 字节的整数变量。
40051f: c7 45 f4 01 00 00 00 movl $0x1,-0xc(%rbp)
图解 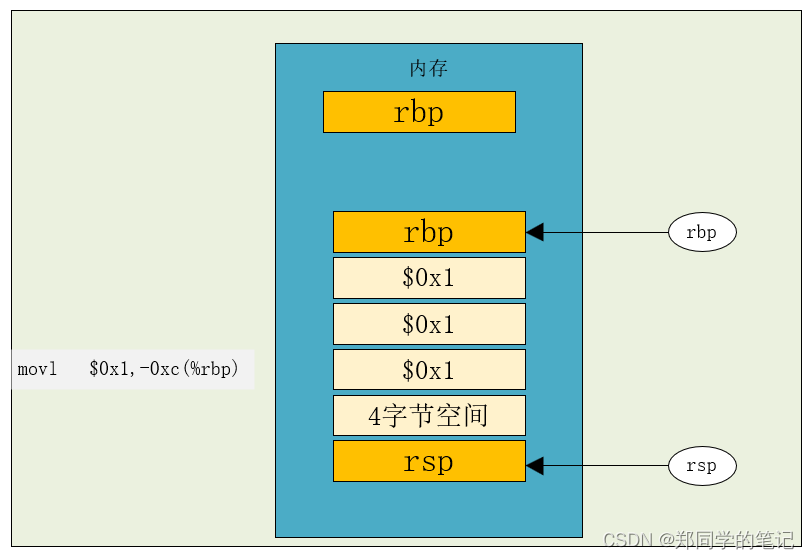 mov 0x200af8(%rip),%edx: 从相对于 %rip 偏移为 0x200af8 的内存位置读取值到 %edx 寄存器中。这是一个全局变量 g_y 的值。
400526: 8b 15 f8 0a 20 00 mov 0x200af8(%rip),%edx # 601024
mov -0x4(%rbp),%eax: 将相对于 %rbp 偏移为 -4 的位置的值读取到 %eax 寄存器中,即读取前面存储的值 1。
40052c: 8b 45 fc mov -0x4(%rbp),%eax
图解
mov 0x200af8(%rip),%edx: 从相对于 %rip 偏移为 0x200af8 的内存位置读取值到 %edx 寄存器中。这是一个全局变量 g_y 的值。
400526: 8b 15 f8 0a 20 00 mov 0x200af8(%rip),%edx # 601024
mov -0x4(%rbp),%eax: 将相对于 %rbp 偏移为 -4 的位置的值读取到 %eax 寄存器中,即读取前面存储的值 1。
40052c: 8b 45 fc mov -0x4(%rbp),%eax
图解 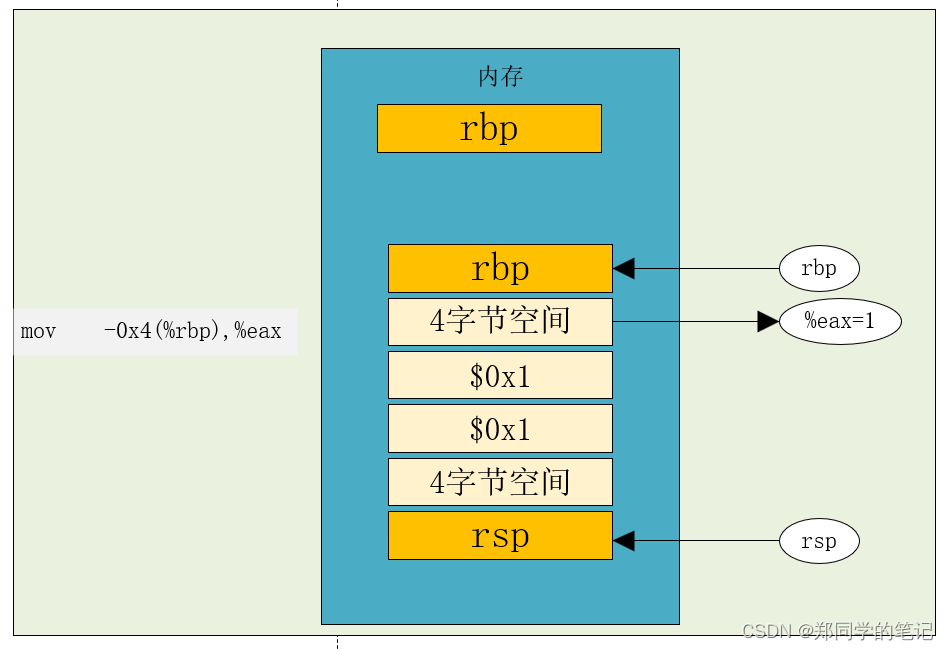 mov %edx,%esi: 将 %edx 寄存器的值复制到 %esi 寄存器,为函数调用准备第一个参数。
40052f: 89 d6 mov %edx,%esi
mov %eax,%edi: 将 %eax 寄存器的值复制到 %edi 寄存器,为函数调用准备第二个参数。
400531: 89 c7 mov %eax,%edi
callq 4004d7 : 调用 add 函数,执行函数调用并跳转到地址 4004d7。
400533: e8 9f ff ff ff callq 4004d7
mov %edx,%esi: 将 %edx 寄存器的值复制到 %esi 寄存器,为函数调用准备第一个参数。
40052f: 89 d6 mov %edx,%esi
mov %eax,%edi: 将 %eax 寄存器的值复制到 %edi 寄存器,为函数调用准备第二个参数。
400531: 89 c7 mov %eax,%edi
callq 4004d7 : 调用 add 函数,执行函数调用并跳转到地址 4004d7。
400533: e8 9f ff ff ff callq 4004d7
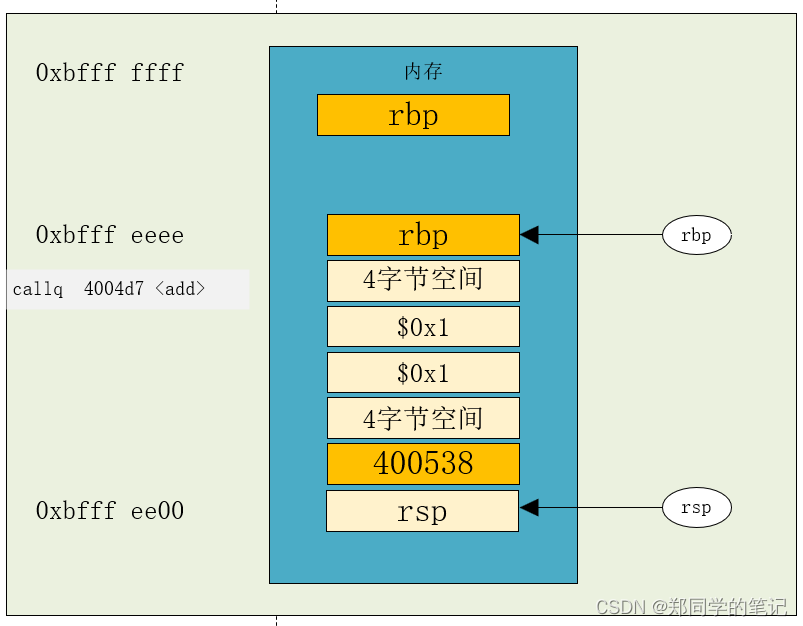
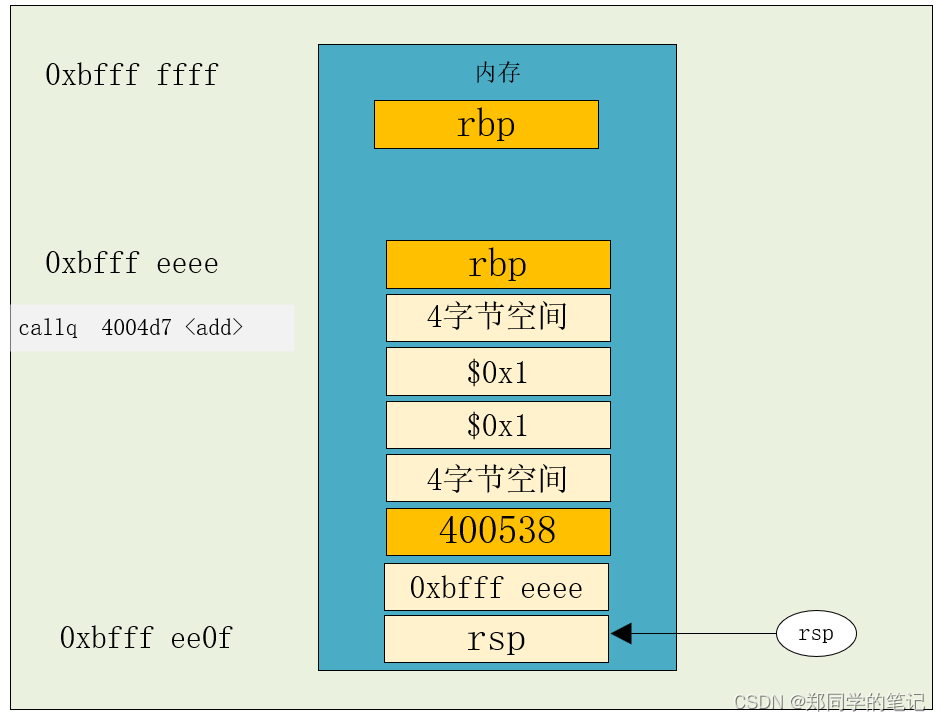
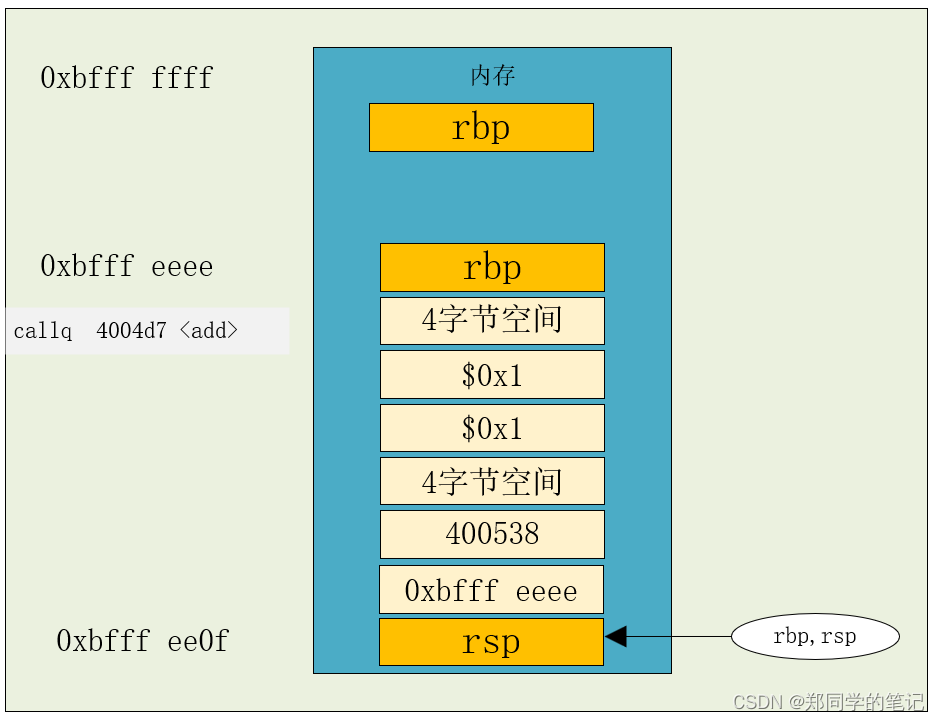
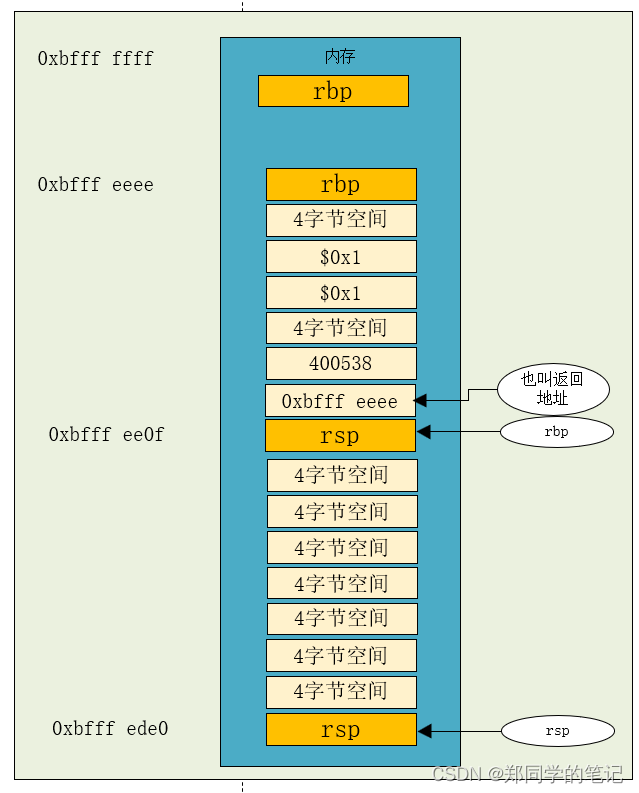
这里其实有两个过程, 第一步:把当前指令的下一条指令的地址——压入栈中。 第二步:跳转到函数执行 接下来,我们跳转到了add函数,我们来分析下。其实前三行指令,和main函数中是一样的。我们假设跳转前,原来rbp的值是oxbfff eeee,rsp的值为0xbfff ee00 12.同main中一样,add中的前三行指令 00000000004004d7 : 4004d7: 55 push %rbp 4004d8: 48 89 e5 mov %rsp,%rbp 4004db: 48 83 ec 20 sub $0x20,%rsp第1步,保存rbp的值,把rbp压入栈中,(你没看错,压入rbp的值,rsp的值又变小了) 第2步,rbp = rsp 第3步,分配32字节的空间 在这段代码中,可以看到指令 leaveq,它的作用是恢复栈帧并返回。 指令 leaveq 的作用等效于以下两条指令的组合: mov %rbp, %rsp pop %rbp 首先,mov %rbp, %rsp 将栈指针 %rsp 的值设置为基址指针 %rbp 的值,这会将栈指针移回到调用者的栈帧上。1.也就是rsp=rbp。开始进函数时rbp=rsb,把rsp的值赋值给rbp,现在离开了把rbp的值赋值给rsp,有没有觉得,rsp又恢复到调用前了,对不对,老铁。 2.弹出rbp 然后,pop %rbp 会从栈上弹出之前保存的基址指针 %rbp 的值,恢复调用者的栈帧。 add函数中,从寄存器取值我们就不说了,原理很简单,main函数往寄存器里面存值,add函数中从寄存器中取值,毕竟都是一个寄存器吗。 因为栈是向下生长的,因此,我们的图解,也是向下生长的。 到此,我们就分析完了,现在有没有觉得函数调用过程,栈帧,寄存器,调用过程清晰多了? 参考 1、《程序员的自我修养链接装载与库》 |
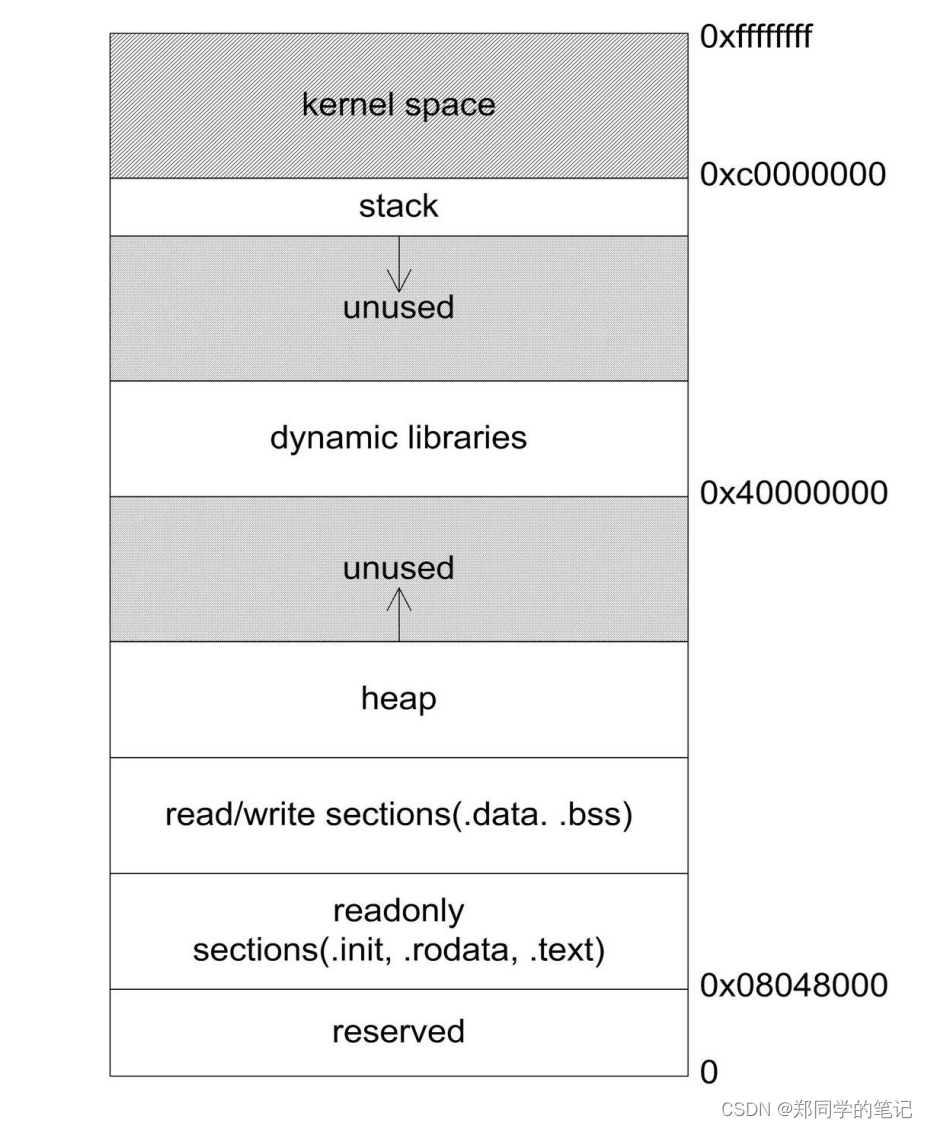 图中的箭头标明了几个大小可变的区的尺寸增长方向, 在这里可以清晰地看出栈向低地址增长, 堆向高地址增长。 当栈或堆现有的大小不够用时, 它将按照图中的增长方向扩大自身的尺寸, 直到预留的空间被用完为止。
图中的箭头标明了几个大小可变的区的尺寸增长方向, 在这里可以清晰地看出栈向低地址增长, 堆向高地址增长。 当栈或堆现有的大小不够用时, 它将按照图中的增长方向扩大自身的尺寸, 直到预留的空间被用完为止。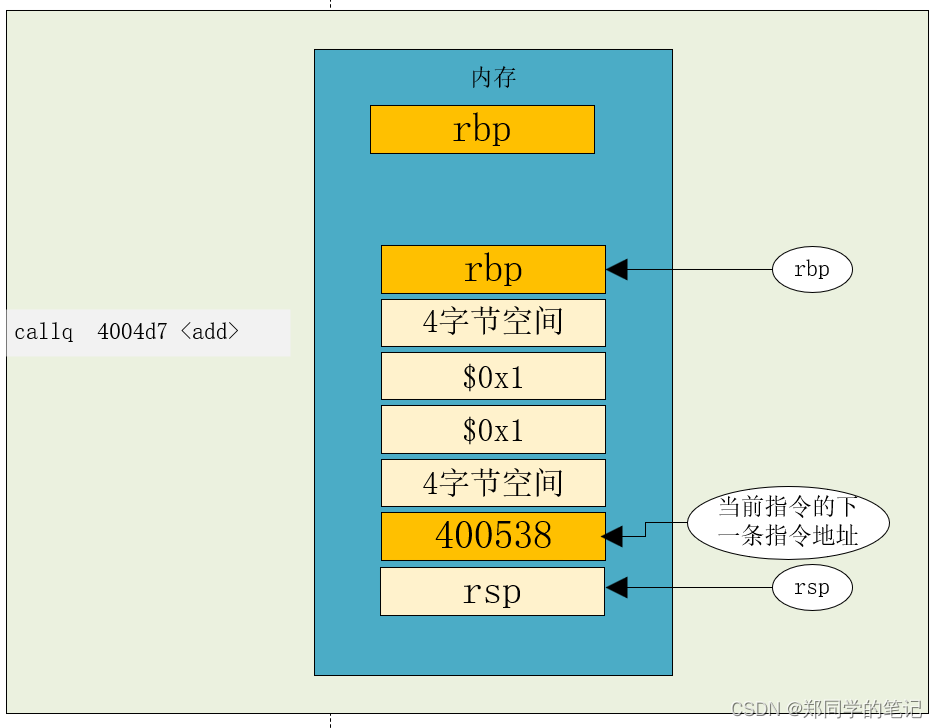
【本文地址】