| 压缩视频质量增强论文DEFORMABLE CONVOLUTION DENSE NETWORK FOR COMPRESSED VIDEO QUALITYENHANCEMENT阅读笔记 | 您所在的位置:网站首页 › crowded变形 › 压缩视频质量增强论文DEFORMABLE CONVOLUTION DENSE NETWORK FOR COMPRESSED VIDEO QUALITYENHANCEMENT阅读笔记 |
压缩视频质量增强论文DEFORMABLE CONVOLUTION DENSE NETWORK FOR COMPRESSED VIDEO QUALITYENHANCEMENT阅读笔记
|
论文来源:ICASSP2022 作者团队:阿里云 abstract与传统的视频质量增强不同,压缩视频质量增强的目标是减少视频压缩带来的伪影。现有的用于压缩视频质量增强的多帧方法严重依赖于光流,这不仅效率低下,而且性能有限。本文提出了一种基于可变形卷积的多帧残差密度网络(MRDN),利用高质量帧来补偿低质量帧,以提高压缩视频的质量。具体而言,所提出的网络由开发的运动补偿(MC)模块和质量增强(QE)模块组成,分别用于补偿和增强输入帧的质量。此外,为了在训练过程中增强边缘结构,在增强帧上引入了一种新的边缘增强损失。最后,在公共基准上的实验结果表明,在压缩视频质量增强任务中,我们的方法优于最先进的方法(未对比STDF,在QP37与32上的性能不如STDF-R3L)。 1. INTRODUCTION为了减少所需的带宽和存储空间,视频压缩算法被广泛应用于许多实际应用场景[1],但这些算法也带来了视频质量下降的问题。因此,如何提高压缩视频的质量是研究界和业界共同关注的问题。作为减少压缩伪影的一种重要方法,压缩视频质量增强包括去除块伪影、减少边缘/纹理浮动以及从蚊式噪声和抖动中重建视频的技术[2]。然而,由于压缩过程中会丢失细节,因此从失真帧中重建高质量帧是一个挑战。 最近,人们提出了许多用于增强压缩图像/视频质量的方法,特别是借助深度学习[3,4,5]。早期的方法[5,6,7,8]独立地增强每个帧,这些方法很简单,但无法利用相邻帧的细节。为了利用时间信息,Yang等人[9]首先提出了一种用于压缩视频质量增强的多帧策略。此后,Guan等人[10]通过细化关键模块进一步发展了该方法。然而,由于视频内容因压缩伪影而严重失真,现有大多数基于多帧的方法中使用的光流方法不够可靠。因此,增强的视频远远不能令人满意。 与在像素级预测光流相比,在感受野中提取特征对于增强压缩视频质量而言更为鲁棒。基于这个想法,我们提出了一种具有可变形卷积的多帧网络[11,12],以实现对多个运动对象的运动补偿。具体而言,与视频任务中使用的传统可变形卷积网络[13,14,15]不同,我们开发了一种新的金字塔可变形结构来提取多尺度对齐信息,并添加了新的约束来减少参考帧中的噪声。 此外,基于残差密集网络在图像超分辨率任务[16]中的应用,我们开发了一种新的具有残差块的密集连接网络,称为MRDN,以进一步提高提取更多层次特征的能力,从而实现更好的压缩视频质量增强。此外,通过对压缩视频的分析,我们发现压缩视频的质量下降通常发生在视频中的对象边缘。因此,设计了一种边缘增强损失,使网络更加关注边缘重建。 本文的主要贡献如下:(1)提出了一种新的压缩视频质量增强方法。该方法开发了一种新的具有有效运动补偿约束的金字塔形可变形结构,并采用残差密集网络进行质量增强;(2) 通过对压缩视频质量下降原因的分析,我们提出了一种新的损失来提高边缘重建的性能;(3) 我们在压缩视频质量增强基准数据库上评估了所提出的方法,并获得了最先进的性能。 2. THE PROPOSED SYSTEM 2.1. Overview
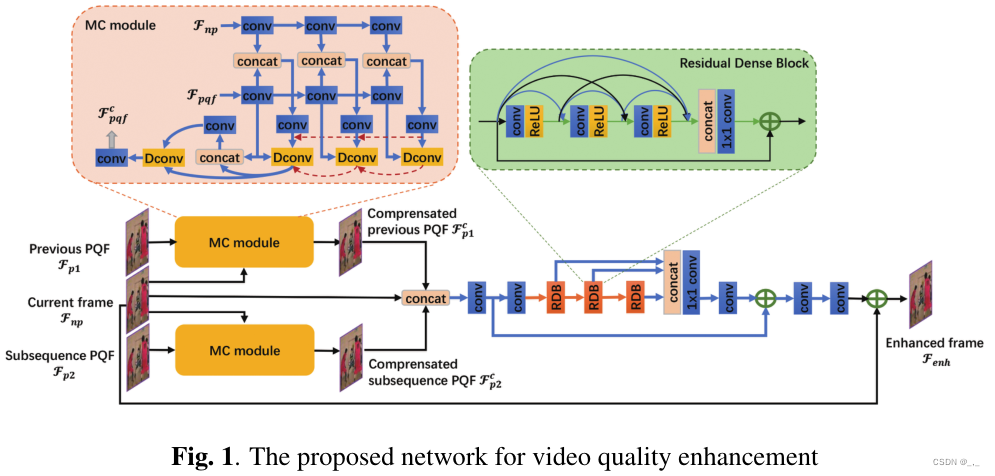
与传统的视频质量增强不同,压缩视频增强的目标是减少或消除视频压缩带来的伪影和模糊。为此,受[9]的启发,我们提出了一种能够利用峰值质量帧(PQF)的多帧网络。如图1所示,网络由开发的MC模块和QE模块组成。Fnp为当前帧,Fp1和Fp2分别是最近的前/后PQF。以PQF(Fp1或Fp2)为参考帧,开发了一个基于可变形卷积的MC模块,用于预测时间运动并更详细地补偿输入帧Fnp。随后,补偿帧被级联为QE模块的输入,QE模块被开发用于进一步提高帧的质量。最后,对增强帧进行一种新的边缘增强损失,以增强训练过程中的边缘结构。我们的新MC、QE和边缘增强损失的详细信息将在以下章节中介绍。 2.2. MC module对于视频相关任务中的传统可变形卷积网络,大多数工作学习参考帧上的偏移δ,然后使用可变形卷曲提取当前帧上的对齐特征。所获得的具有N个像素的对齐特征Fa被定义为:
考虑到帧上通常同时存在多个运动对象,我们将多个可变形卷积构造成金字塔结构,以提取多尺度对齐特征,并通过级联增强信息交互。具体来说,金字塔形可变形结构有3层,每层从具有不同分辨率的输入中提取对齐特征。层越深,输入分辨率越小。同时,通过级联,偏移量 f、 g和h都是使用ReLU激活的非线性变换层, 在获得补偿PQF(F cp1和F cp2)后,QE模块需要融合补偿帧和当前帧之间的信息,从而进一步提高当前帧的质量。为了提高QE模块的长期记忆能力,我们采用参数为θQE的残差稠密网络来提取更多层次特征。所提出的QE模块将补偿帧和当前帧级联为输入,然后输出残差Rθqe。通过将该残差添加到当前帧,可以生成更高质量的帧Fenh:
在压缩视频质量增强中,均方误差(MSE)被广泛使用。然而,MSE损失不能很好地指导网络改善物体边缘的质量。为了使网络更加关注边缘重建,我们提出了一种边缘增强损失。给定包含N个像素的增强帧Fenh及其对应的原始帧Fraw,它们之间的边缘增强损失定义为: 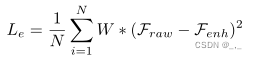
其中, 与其他视频任务不同,压缩视频质量增强任务对噪声非常敏感。因此,我们不仅优化了qe模块的参数θ。具体而言,对于MC模块,补偿帧不仅需要提供对齐的结果,而且还需要保留原始帧Fraw的类似质量。对于QE模块,增强帧Fenh要求与原始帧一样高质量。因此,总损失定义为:
 4. CONCLUSION
4. CONCLUSION
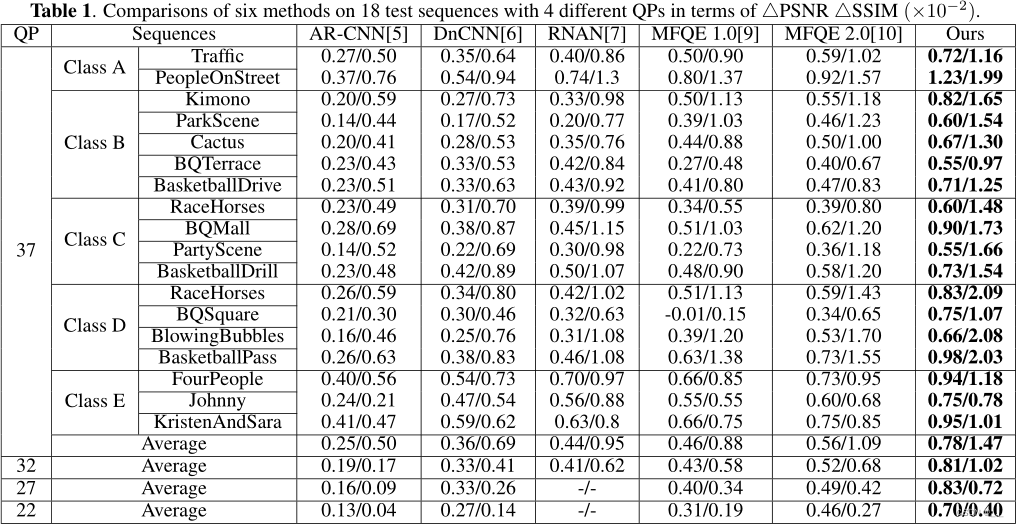
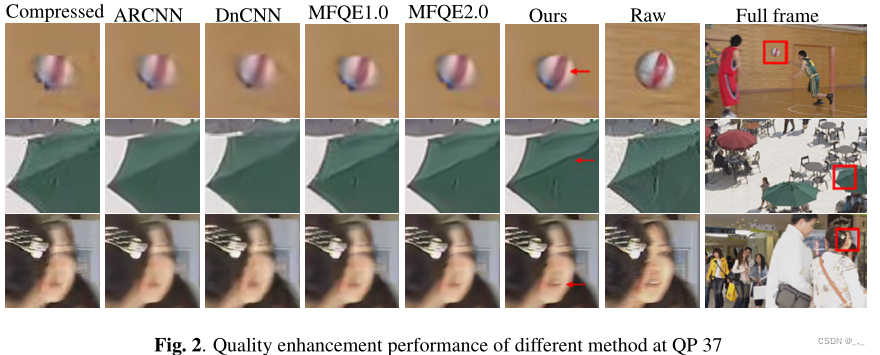
在本文中,我们提出了一种新的用于压缩视频质量增强的多帧网络,该网络使用金字塔形可变形结构来补偿运动,并通过多帧残差密集网络来增强压缩帧的质量。此外,还设计了一种边缘增强损失,用于强大的边缘重建。该模型在基准数据库上达到了最先进的性能,模型大小为1.32M,比大多数比较方法都小。未来的工作将集中于进一步降低计算复杂性。
|
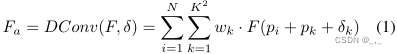
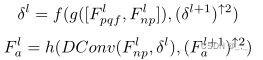
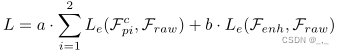
【本文地址】