| 机器学习里的K | 您所在的位置:网站首页 › cross_val_score参数scoring › 机器学习里的K |
机器学习里的K
|
在这前面的几篇文章中,介绍了什么是机器学习,线性回归模型、逻辑回归模型、优化方法、防止过拟合以及机器学习项目应用。这里介绍一下在机器学习项目里怎么为了防止过拟合而采取的一种技术,叫K-fold交叉验证。这种方法思想其实很简单,但是实施起来其实花样还挺多。 1.什么是K-fold交叉验证?K-fold交叉验证是一种数据拆分技术,被定义为一种用于在未见过的数据上估计模型性能的方法。你可以使用k>1折来实现用于不同目的的样本划分,也是一种用于超参数优化的技术,以便可以训练具有最优超参数值的模型。这是一种无需增添或者修改样本的重采样技术。这种方法的优点是,每个样本案例仅用于训练和验证(作为测试折的一部分)一次。与传统方法相比,这种方法可以很好降低模型性能的方差。 之所以使用此技术,是因为它有助于避免过度拟合,当使用所有数据训练模型时,可能会发生过度拟合。通过使用k-fold交叉验证,我们能够在k个不同的数据集上"测试"模型。K-Fold Cross Validation 也称为 k-cross、k-fold CV 和 k-folds。k-fold交叉验证技术可以使用Python手动划分实现,或者使用scikit learn包轻松实现(它提供了一种计算k折交叉验证模型的简单方法)。在这里重要的是要学习交叉验证的概念,以便进行模型调整,最终目标是选择具有高泛化性能的模型。作为数据科学家/机器学习工程师,你必须对交叉验证概念有很好的理解。 2.为什么使用交叉验证技术?训练和测试模型的传统技术是将数据拆分为两种不同的拆分,称为训练和测试拆分,两者比例一般为70%:30%。但是这种方式会产生一些问题:为了训练最佳性能的模型,我们需要手动对超参数进行适当的调整,以利用测试数据实现良好的模型性能,这种静态的方式会导致在测试集上出现过度拟合的风险。因为有关测试集的知识活着信息会"泄漏"到模型中,评估指标就不是真实的反映模型泛化性能。 为了解决上述问题,进一步做训练,验证和测试三个拆分。模型超参数使用训练和验证集进行优化,最后使用测试数据确定模型泛化性能。但是这种技术也有缺点,通过将数据划分为三组,会减少用于学习模型的样本数量,而且结果取决于对(训练、验证)集的特定随机选择。 因此为了克服上述种种问题,交叉验证技术就应运而生。我们对数据进行两种不同的拆分,即训练和测试拆分,然后通过再对训练数据的K折划分,其中(K-1) 折用于训练,剩下一折用于验证,这个过程重复K次,并通过获取训练的所有K个模型的平均值和标准差来计算一组特定超参数的模型性能分数,计算给出最优模型的超参数。最后,模型使用最优超参数在整个训练数据集上再次训练,并通过计算测试数据集上的评估分数来计算泛化性能。就像下面这张图: 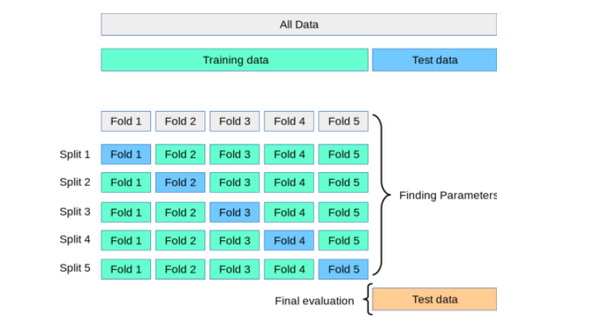 图 1.为什么选择K-Fold交叉验证 K-fold交叉验证也用于模型选择,可以把它与其他模型选择技术(如Akaike信息准则和贝叶斯信息准则)进行比较。 3.怎么进行K-fold交叉验证?K-fold交叉验证的过程分为下面几步: 把数据集分为训练数据集和测试数据集。然后将训练数据集拆分为K份;在K-folds样本中,(K-1)份用于训练,1份用于验证,把每次模型的性能记录下来。重复第2步,直到每个k-fold 都用到了验证(这就是为什么它被称为k-fold交叉验证)。通过获取步骤2中为所有K个模型计算的模型分数来计算模型性能的均值和标准差。对不同的超参数值重复步骤2到步骤5。最后选择产生最优分数均值和标准值的模型超参数。在测试数据集上计算评估模型性能。下图这个十折交叉验证表示是上面步骤2到步骤4:  图 2.计算使用K折训练的模型性能的平均分数 4.怎样选择K的值?K的标准值为10,一般默认都是这个值,但是也要看数据集大小情况。对于非常大的数据集,可以使用K的值为5 ,因为这样可以在获得模型平均性能的准确估计的同时降低在不同折上多次拟合和评估模型的计算成本;如果数据相对较小,可以适当增加K的值,但是如果k的值越大,会导致交叉验证算法产生的模型性能估计具有更高的方差;对于非常小的数据集,使用一次叉验证( LOOCV )技术,这种方式又称留一法,验证数据仅由一行数据组成。在大多数情况下建议使用分层k折叠交叉验证,以便获得更好的偏差和方差估计,特别是在类比例不平衡的情况下。 5.Python实现K-fold 交叉验证按照上面的思路,我们可以自己用Python构建交叉验证的方法,但是因为Sklearn有很方便的交叉验证生成器,所以我们一般不自己费劲造轮子。下面给出的交叉验证生成器返回训练集和测试集拆分的索引,通过轮换使用这些索引进行切片创建训练集和测试集来训练不同的模型,然后计算不同模型的性能的均值和标准差,以评估超参数值的有效性并进一步适当地进行调优。 下面是Python代码,它使用了Class StratifiedKFold类(sklearn.model_selection) :1.创建StratifiedKFold的实例,传递fold参数(n_splits= 10);2.在StratifiedKFold的实例上调用Split方法,切分出K折的训练集和测试集的索引;3.把训练集和测试集数据传递到管道(pipeline)实例中,管道是Sklearn很好的一个类,它相当于构建了一个工作流;4.计算不同模型的评估分数;5.最后计算模型分数的均值和标准差; from sklearn.model_selection import cross_val_score from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import StratifiedKFold #创建一个管道(Pipeline)实例,里面包含标准化方法和随机森林模型 pipeline = make_pipeline(StandardScaler(), RandomForestClassifier(n_estimators=100, max_depth=4)) # 创建一个用于得到不同训练集和测试集样本的索引的StratifiedKFold实例,折数为10 strtfdKFold = StratifiedKFold(n_splits=10) #把特征和标签传递给StratifiedKFold实例 kfold = strtfdKFold.split(X_train, y_train) #循环迭代,(K-1)份用于训练,1份用于验证,把每次模型的性能记录下来。 scores = [] for k, (train, test) in enumerate(kfold): pipeline.fit(X_train.iloc[train, :], y_train.iloc[train]) score = pipeline.score(X_train.iloc[test, :], y_train.iloc[test]) scores.append(score) print('Fold: %2d, Training/Test Split Distribution: %s, Accuracy: %.3f' % (k+1, np.bincount(y_train.iloc[train]), score)) print('\n\nCross-Validation accuracy: %.3f +/- %.3f' %(np.mean(scores), np.std(scores)))上述代码执行的输出如下所示: 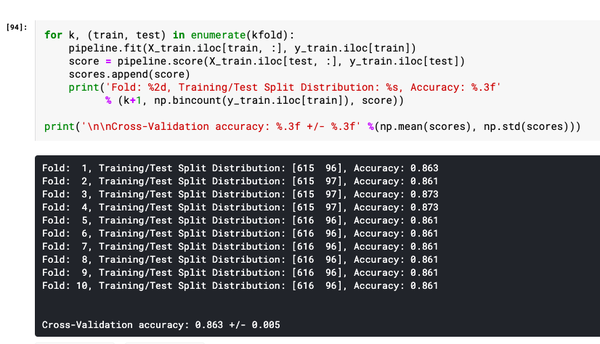 图 3.使用分层KFold交叉验证器生成器的交叉验证分数 6.模型调优(sklearn.cross_val_score对象)上面只是简单的把数据集轮换划分,但是交叉验证技术往往是用来进行模型优化(超参数优化)。在sklearn.model_selection模块中有一个cross_val_score类用于计算交叉验证分数,它通过将数据重复拆分为训练集和测试集,使用训练集训练估计器,并根据交叉验证的每次迭代的测试集计算分数。cross_val_score的参数包括估计器(具有fit和predict方法)或者是管道 (sklearn.pipeline)、交叉验证对象(object),其中参数cv如果是一个整数,表示分层KFold交叉验证器中的折叠数,如果是小数,表示训练集和验证集的比例;如果没有指定 cv,默认使用5折交叉验证。下面是代码: from sklearn.model_selection import cross_val_score from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier #创建一个管道(Pipeline)实例,里面包含标准化方法和随机森林模型估计器 pipeline = make_pipeline(StandardScaler(), RandomForestClassifier(n_estimators=100, max_depth=4)) # 设置交叉验证折数cv=10 表示使用带有十折的StratifiedKFold,再把管道和数据集传到交叉验证对象中 scores = cross_val_score(pipeline, X=X_train, y=y_train, cv=10, n_jobs=1) print('Cross Validation accuracy scores: %s' % scores) print('Cross Validation accuracy: %.3f +/- %.3f' % (np.mean(scores),np.std(scores)))下面是执行上述代码的结果输出:  图 4.用于K交叉验证Sklearn.model_selection方法cross_val_score 7.k-fold 交叉验证的缺点是什么?k-fold 交叉验证的缺点是执行速度可能很慢,并且很难并行化。此外,k-fold 交叉验证并不总是所有类型的数据集的最佳选择。例如,当相对于测试示例的数量而言训练示例很少时,k-fold 交叉验证可能不那么准确,在这些情况下,可能留一法交叉验证可能更合适。k 折交叉验证也不适用于时间序列数据。 总结基本上上面的内容可以概括为下面这几点: 1.K-fold 交叉验证本身是用作数据拆分,但主要目的是用于模型调优/超参数调优。 2.K-fold 交叉验证是将数据轮换拆分为训练数据集和测试数据集,交叉训练和验证,选择性能最佳的模型。 3.有很多种交叉验证生成器,例如KFold,StratifiedKFold,可对应不同的数据测试哪个效果最好。 4.K值的选择一般10。对非常小的数据集使用LOOCV方法。对于非常大的数据集,可以使用5折。 5.建议使用分层k折交叉验证,以便获得更好的偏差和方差估计,特别是在类比例不平衡的情况下。 6.Sklearn.model_selection模块的cross_val_score封装了K-fold 交叉验证和参数调优的过程,简单易用。 最后欢迎大家关注我,我是拾陆,关注同名"二八Data",更多干货持续为你奉献。  
|
【本文地址】