| 你还在用excel整理临床数据吗?繁琐易出错!来试试Epidata | 您所在的位置:网站首页 › crf表模版 › 你还在用excel整理临床数据吗?繁琐易出错!来试试Epidata |
你还在用excel整理临床数据吗?繁琐易出错!来试试Epidata
|
Hi,大家好,在上一期的分享中我们提到,通过标准的CRF得到的数据可以直接被统计软件读取并分析。但是相信大家还是有一个疑惑,既然CRF表这么好用,那怎么把数据录入到CRF表中呢?是纸质问卷打印下来填写?还是放在excel中逐条填入数据?显然这些都不是最好的数据管理办法。 一般来说,进行医学科研工作都有如下基本步骤:  一份好的研究设计有利于后续数据资料的整理与分析,同样先来了解如何进行数据管理即录入什么样的数据、如何录入,也可以帮助我们在研究设计时确定变量条目及类型。 在数据管理中,选择合适的软件是保证数据质量的重要方面。而Epidata作为一款免费的数据录入经典工具,目前的Epidata3.1版本,从2008年投入使用至今已经十余年,依然深受研究者们的喜爱,源自它的诸多优点: 软件小巧,安装简易( 仅1Mb大小)设计界面友好,易学易用(官网有中文操作手册)数据导出格式多样(Excel、SAS、SPSS、Stata等)可进行数据核查,一致性检验等 出于数据录入的需要,我们可以只下载数据库录入模块——在官网的“EpidataEntry”下载区,有英文、中文等多种语言版本。 相信如果你有被安排过用Epidata录入数据,那么你对下面这幅图一定有种莫名的亲切感,这就是Epidata的REC文件(数据文件)——用于录入和存放数据。  PS:蓝色的框表示正要输入的变量,黄色的框表示后面需要录入的内容。 那如何才能得到这样的录入界面呢?我们先揭晓谜底——那就是在得到REC文件之前,我们首先需要创建下面的QES文件(调查表文件)——用于定义调查表(问卷)的结构,也就是将我们所要收集的变量内容按照一定规则进行编辑。  话不多说,下面就跟着小编一起来学习Epidata的使用吧~ 总的来说,Epidata数据库的建立流程包含三步: (1)建立调查表文件(*.qes) (2)在调查表文件的基础上创建数据库文件(*.rec) (3)建立核查文件(*.chk)  1、建立调查表文件(*.qes) (1).打开软件,建立新QES文件 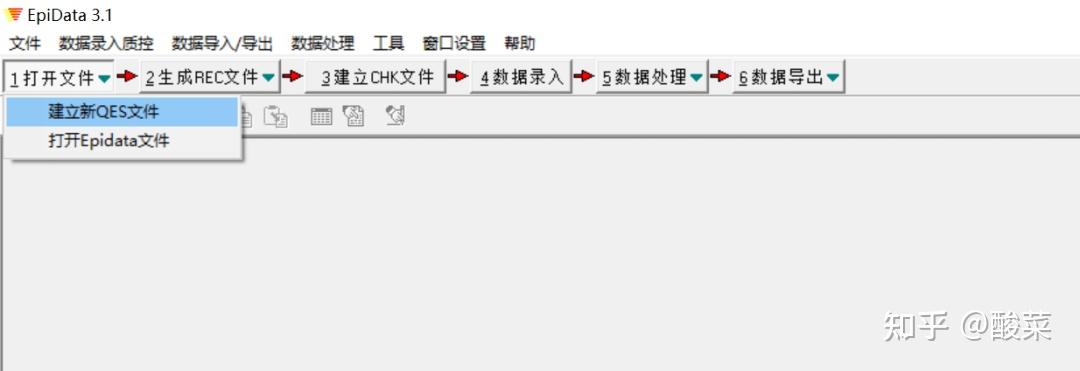 (2)定义变量名及变量标签 调查表中变量由三部分组成:变量名、变量标签、字段类型(及长度)。除这三部分外,我们通常会加入该变量的录入说明,比如“性别”变量下,录入“1”为女,“2”为男。  变量名或字段名的命名方式有两种,分别是:  a.以调查表第一个词命名 因为Epidata不能识别中文变量名,若在调查表为中文时我们选择该命名方式,则生成的REC文件中默认第一个变量为“FIELD1/field1”,第二个变量为“FIELD2/field2”,以此类推…那么在后期数据处理时,除非翻阅原始调查表,否则我们无法快速识别每一个变量的含义。  当然,有小伙伴可能已经想到了,既然不能识别中文,那么我们在中文变量前给每一个变量取个英文名是不是就可以了呢?确实如此,但这里需要注意,若执意选择这种命名方式,一定要英文(拼音)名称在前,中文变量标签在后。  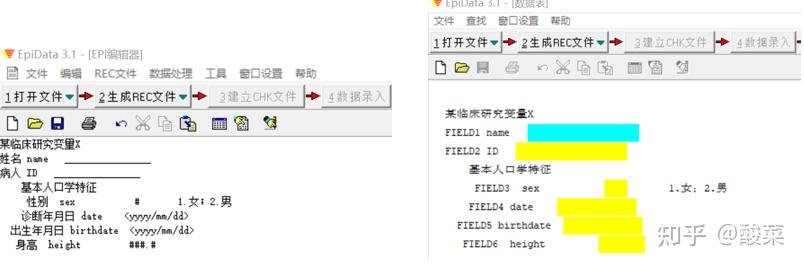 b.使用{}内的内容自动添加字段名(注意:变量名需用{}括起来,且必须用英文字母)PS:作为“控制欲”比较强的同学来说,我们还是推荐使用这个方法来添加字段名,这样你就可以准确定义每个变量名的英文名字,可以采用拼音等方式,方便后期数据处理的时候一眼就能识别对应的变量是什么意思。而且,这种方式下可以不受变量名和变量标签前后顺序的限制。 (若有调查表的word文件,可以在编辑框中直接复制粘贴) (3).定义字段类型及长度 (1)点击编辑→字段编辑器 或者直接点击工具栏的字段编辑器图标   (2)根据需要选择合适的字段类型(数字/文本/日期等)及长度,确认后点击插入。比如在编辑“姓名”这一变量时,字段类型选择“文本”,中文一个字占据2个字符,所以我们如果认为名字最长有4个汉字,那么就需要设定字符长度为8。  在编辑身高、体重等变量时,可以根据需要设置小数点保留位数。比如这里身高设置为“###.#”表示这个数小数点前有3位,小数点后有1位数。 在我们录入数据时,如果小数点没有输入的话,也会自动补0。但是如果你想输入2位小数点的数字,就输不进去了。 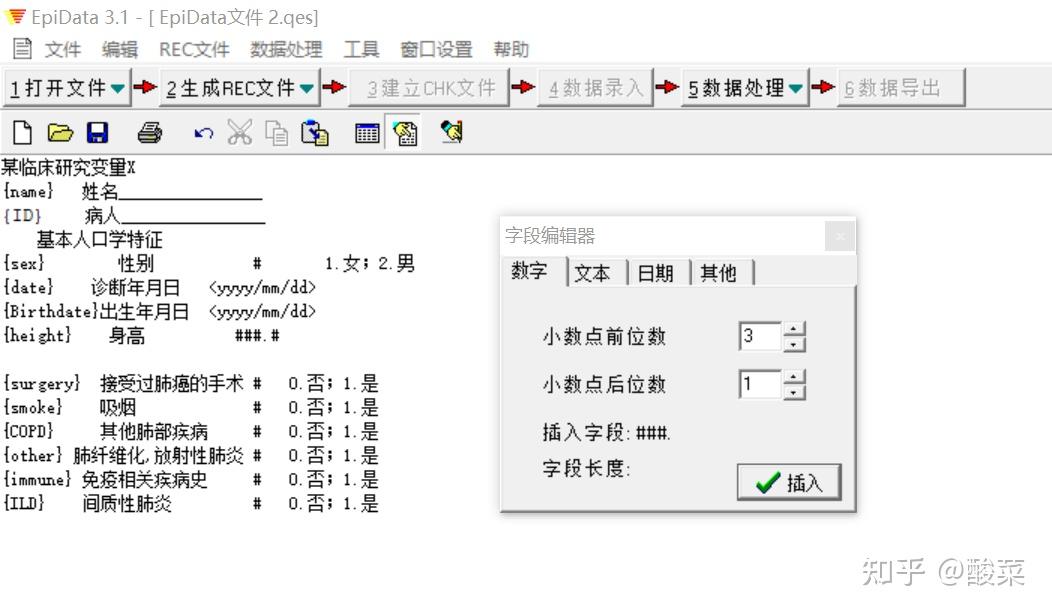 这里需要注意的是: 数值型变量:########,最长允许14个字符;且数值型变量只允许录入数字、减号和小数点。 字符型变量: ,最长允许80个字符,一个中文为2个字符。 2、创建数据库(*.rec) 数据库的创建在Epidata中表现为生成“.REC”文件,该文件是基于调查表文件(qes)而产生的。在所有字段设置完成之后,即可生成rec文件,有两种方式可以实现: a.菜单栏:REC文件→生成REC文件  b.工作流程栏:生成REC文件   这里需要注意的是: 覆盖文件操作一定要慎重!!!若原来数据库已存在数据,一经覆盖则数据将被清空! 3、建立核查文件(*.chk) 关闭qes文件与rec文件,根据REC文件建立CHK文件,目的是数据录入过程中在一定程度保证数据的合理性与正确性,同时可以控制数据录入的流程(跳转问题)。 比如在“sex”变量下,定义了“1.女2.男”,录入的数据如果出现1和2以外的结果,这样在后续分析时就是异常值。所以我们的目标是:一旦录入员输入1、2以外的数值,应该跳出弹窗,提醒输入错误 建立核查文件实现方式有以下两种: a.菜单栏:数据录入质控→添加/修改录入质控程序  b.工作流程栏:建立CHK文件 打开刚刚建立的REC文件  设置数据核对窗口,首先选择需要定义的变量,根据需要在不同选项下设置对该变量的数据要求,常用功能如下:  Range,Legal:定义变量的允许范围、合法值 如:输入“1,2”表示只能录入1或者2; 输入“1-10”表示可以录入从1至10的任何数值; 输入“1-10,99”表示可以录入从1至10的任何数值或者99。 Jumps:在输入数据后决定是否跳转 如:“1>V10”,表示如果在这个变量下输入1将跳转到V10变量,紧接着开始在V10中继续输入。 此处可定义多个跳转,中间用“,”隔开,比如“1>V10,2>V15,3>V20”,表示如果在这个变量下输入1将跳转到V10变量,输入2将跳转到V15变量,输入3将跳转到V20变量。 Mustenter:选择“Yes”表示必须输入,不得缺项。这样在数据录入过程中,如果该变量未录入任何数据,则会提示,可以避免数据录入遗漏。   Repeat:重复,选择“Yes”表示上一条记录中该变量的值将会在下一条记录中重复显示,从而加快数据录入速度(该重复值可修改)。 Valuelabel:添加数值标签,对于分类数据,定义数值的具体意义 如:在“sex”变量中,1female,2male 所有需要定义的变量均完成设置后,点击存盘即可。 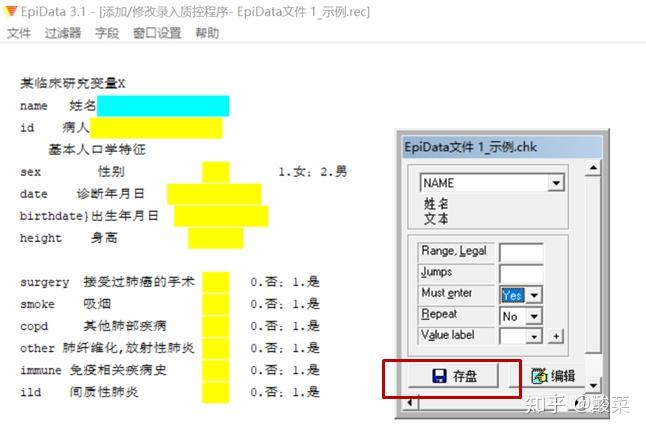 这里需要提醒的是,建立的CHK文件必须与数据库的文件名(REC文件)相同。 完成以上三个步骤再次打开REC文件就可以开始数据录入。录入时,字段填满光标自动跳转到下一个字段,如果未自动跳转,我们仅需按回车即可。 每一个记录下所有变量录入完成,跳出“是否将记录存盘”,点击“是”我们的一条记录就算录入完成啦~ 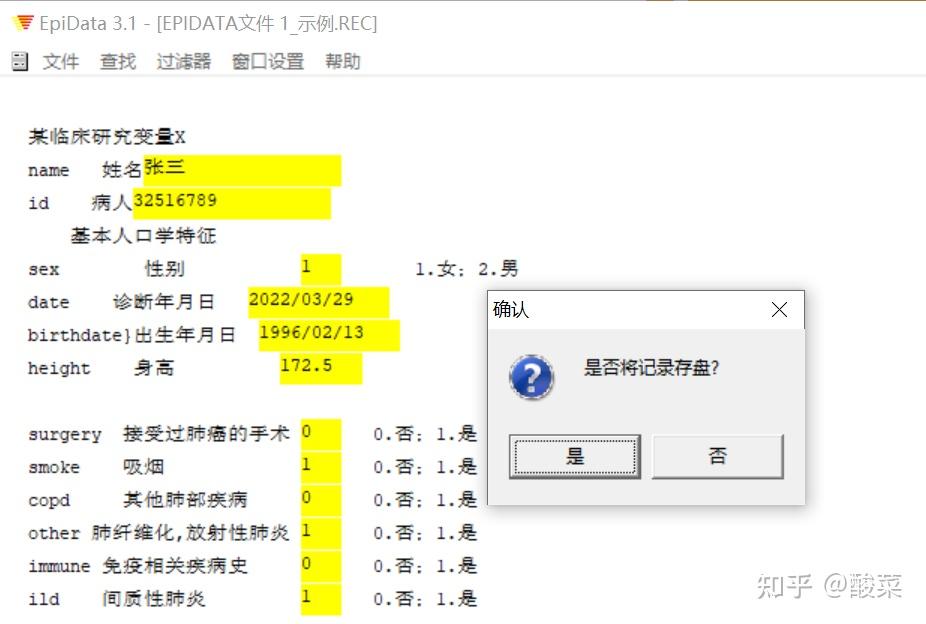 今天介绍的关于Epidata建库的内容都是比较常用的简单操作,可以满足基础使用的需求。除此之外还有一些内容,比如数据库的修改、合并等,如果有需要可以自行查阅操作手册,也可以给我们留言哦~ 本期我们就到这里啦,下期开始我们就进入临床常用量表解读介绍系列,涉及营养状态、生活质量和心理三大方面,量表的使用结合临床资料将有助于我们在研究中挖掘创新变量。我们下期见! 作者: 筱琳 本文首发于“ 解螺旋”微信公众号 转载请注明:解螺旋·临床医生科研成长平台 
|
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |