| 循环神经网络RNN论文解读 | 您所在的位置:网站首页 › cnn近两年的论文 › 循环神经网络RNN论文解读 |
循环神经网络RNN论文解读
|
版权声明:本文为CSDN博主「了不起的赵队」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/zhaojc1995/article/details/80572098
论文名称:RECURRENT NEURAL NETWORK REGULARIZATION 论文地址:https://arxiv.org/pdf/1409.2329.pdf
1、RNN介绍 RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。从基础的神经网络中知道,神经网络包含输入层、隐层、输出层,通过激活函数控制输出,层与层之间通过权值连接。激活函数是事先确定好的,那么神经网络模型通过训练“学“到的东西就蕴含在“权值“中。这是一个标准的RNN结构图,图中每个箭头代表做一次变换,也就是说箭头连接带有权值。左侧是折叠起来的样子,右侧是展开的样子,左侧中h旁边的箭头代表此结构中的“循环“体现在隐层。图中O代表输出,y代表样本给出的确定值,L代表损失函数。
2、RNN特点: (1)权值共享,图中的W全是相同的,U和V也一样。 (2)前面的输出会影响后面的输出,适合处理序列数据。 (3)损失也是随着序列的推荐而不断积累的。
3、rnn多种变体 (1)输入为序列,单个输出(如:分类)
(2)单输入,输出为序列
(3)多输入M,多输出N,且M=N
(4)多输入M,多输出N,且M不等于N(encoder-decoder模型:从名字就能看出,这个结构的原理是先编码后解码。左侧的RNN用来编码得到c,拿到c后再用右侧的RNN进行解码。得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。)
4、标准RNN前向传播
各个符号的含义:x是输入,h是隐层单元,o为输出,L为损失函数,y为训练集的标签。这些元素右上角带的t代表t时刻的状态,其中需要注意的是,隐藏单元h在t时刻的表现不仅由此刻的输入决定,还受t时刻之前时刻的影响。V、W、U是权值,同一类型的权连接权值相同。 对于t时刻,隐藏层的输出:
t时刻的输出:
最终模型的预测输出为:
5、RNN反向传播BPTT BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。综上所述,BPTT算法本质还是BP算法,BP算法本质还是梯度下降法,求各个参数的梯度就是此算法的核心。
再次拿出这个结构图观察,需要寻优的参数有三个,分别是U、V、W。与BP算法不同的是,其中W和U两个参数的寻优过程需要追溯之前的历史数据,参数V相对简单只需关注目前,那么我们就来先求解参数V的偏导数。 (1)参数V的偏导数:
这个式子看起来简单但是求解起来很容易出错,因为其中嵌套着激活函数函数,是复合函数的求道过程。 RNN的损失也是会随着时间累加的,所以不能只求t时刻的偏导。
(2)L对W的偏导数为(W和U的偏导的求解需要涉及到历史数据,偏导求起来相对复杂,假设是在第三个时刻 ):
L在t时刻对W偏导数的通式:
(3)L在第三个时刻对U的偏导数:
L在t时刻对U偏导数的通式:
6、梯度消失问题 前面说过激活函数是嵌套在里面的,如果我们把激活函数放进去,拿出中间累乘的那部分: 累乘会导致激活函数导数的累乘,进而会导致“梯度消失“和“梯度爆炸“现象的发生。 sigmoid函数和导数图:
tanh函数和导数图:
由上图可知:sigmoid函数的导数范围是(0,0.25],tach函数的导数范围是(0,1],他们的导数最大都不大于1,这样累乘会引起梯度消失问题。具体参见激活函数对比:https://blog.csdn.net/qq_32172681/article/details/98474079 解决“梯度消失“的方法主要有: (1)选取更好的激活函数 (2)改变传播结构 对于(1),一般选用ReLU函数作为激活函数,ReLU函数的图像为:
ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了“梯度消失“的发生。 但是,如果左侧横为0的导数有可能导致把神经元学死,不过设置合适的步长(学习率)也可以有效避免这个问题的发生。 对于(2),提出了LSTM结构。
|







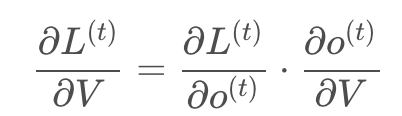

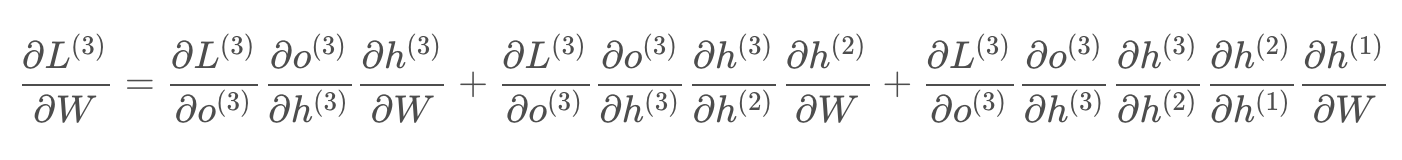
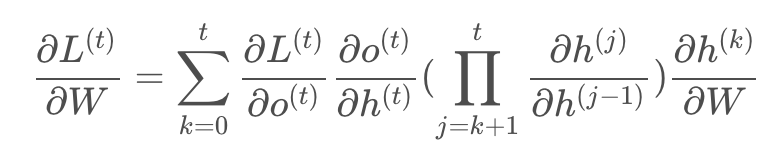
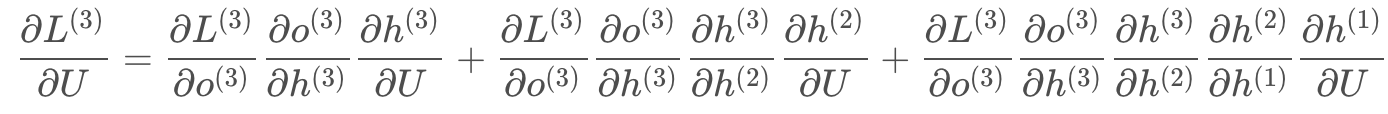





【本文地址】