| Python实现基于ClipCap的看图说话Image Caption模型 | 您所在的位置:网站首页 › clip和sub文件夹 › Python实现基于ClipCap的看图说话Image Caption模型 |
Python实现基于ClipCap的看图说话Image Caption模型
|
资源下载地址:https://download.csdn.net/download/sheziqiong/85908050 资源下载地址:https://download.csdn.net/download/sheziqiong/85908050 ClipCap:让计算机学会看图说话 项目简介Image Caption即我们常说的看图说话:给定一张图片,生成该图片对应的自然语言描述。 该任务涉及到了图像与自然语言两个模态,然而图像空间与自然语言空间本就十分庞大,并且两者之间存在巨大的语义鸿沟。 如何将两个庞大的语义空间进行对齐,这是该任务的重点。本项目对ClipCap: CLIP Prefix for Image Captioning 论文进行介绍,并且对论文在Flickr30k中文数据集上进行实验复现和效果展示。 论文概述 模型总览ClipCap提出了一种基于Mapping Network的Encoder-Decoder模型,其中Mapping Network扮演了图像空间与文本空间之间的桥梁。模型主要分为三部分: 图像编码器:采用CLIP模型,负责对输入的图像进行编码,得到一个图片向量clip_embed。Mapping Network:扮演图像空间与文本空间之间的桥梁,负责将图片向量clip_embed映射到文本空间中,得到一个文本提示向量序列prefix_embeds。文本解码器:采用GPT2模型,根据提示向量序列prefix_embeds,生成caption。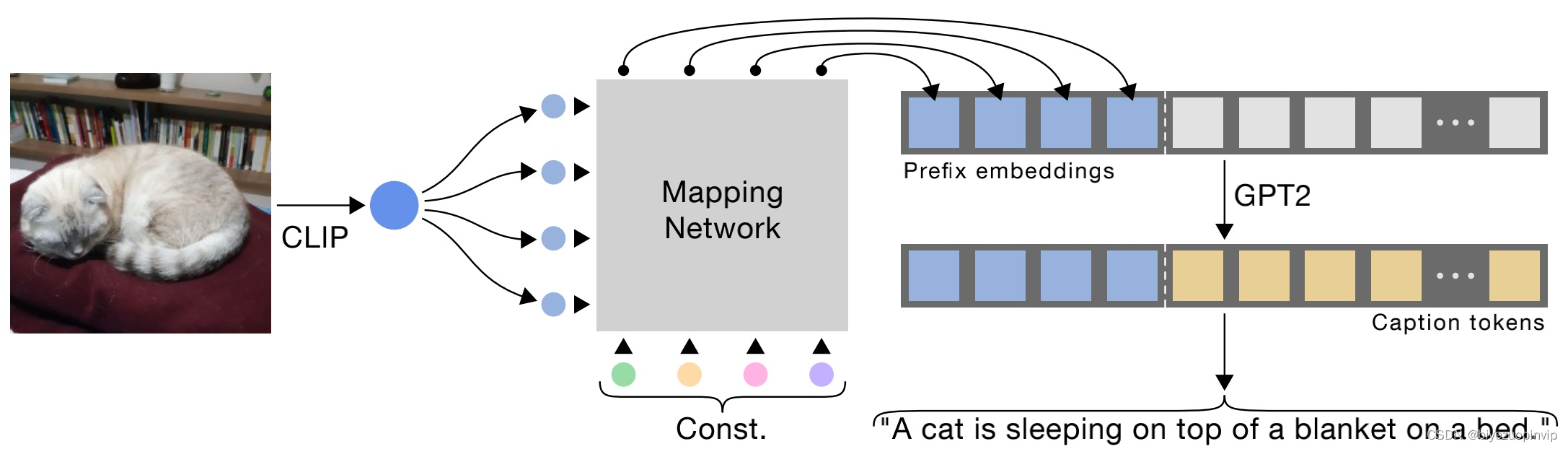
论文中直接使用了预训练好的CLIP与GPT2-Large权重,两者分别是非常优秀的图像编码器和文本生层器, 能够将图像与文本映射到较好的语义空间中。然而两个模型是使用不同的任务进行训练的,语义空间没有进行对齐。 对于该问题,作者设计了两种Mapping Network,负责将图像与文本空间进行对齐。 MLP Mapping Network使用多层全连接层作为CLIP与GPT2模型之间的桥梁。 具体做法如下:首先将图片向量clip_embed经过两层全连接层,映射成提示向量prefix_embeds,该向量作为提示信息输入到GPT2模型中, 然后GPT2模型根据prefix_embeds生成图片对应的caption。
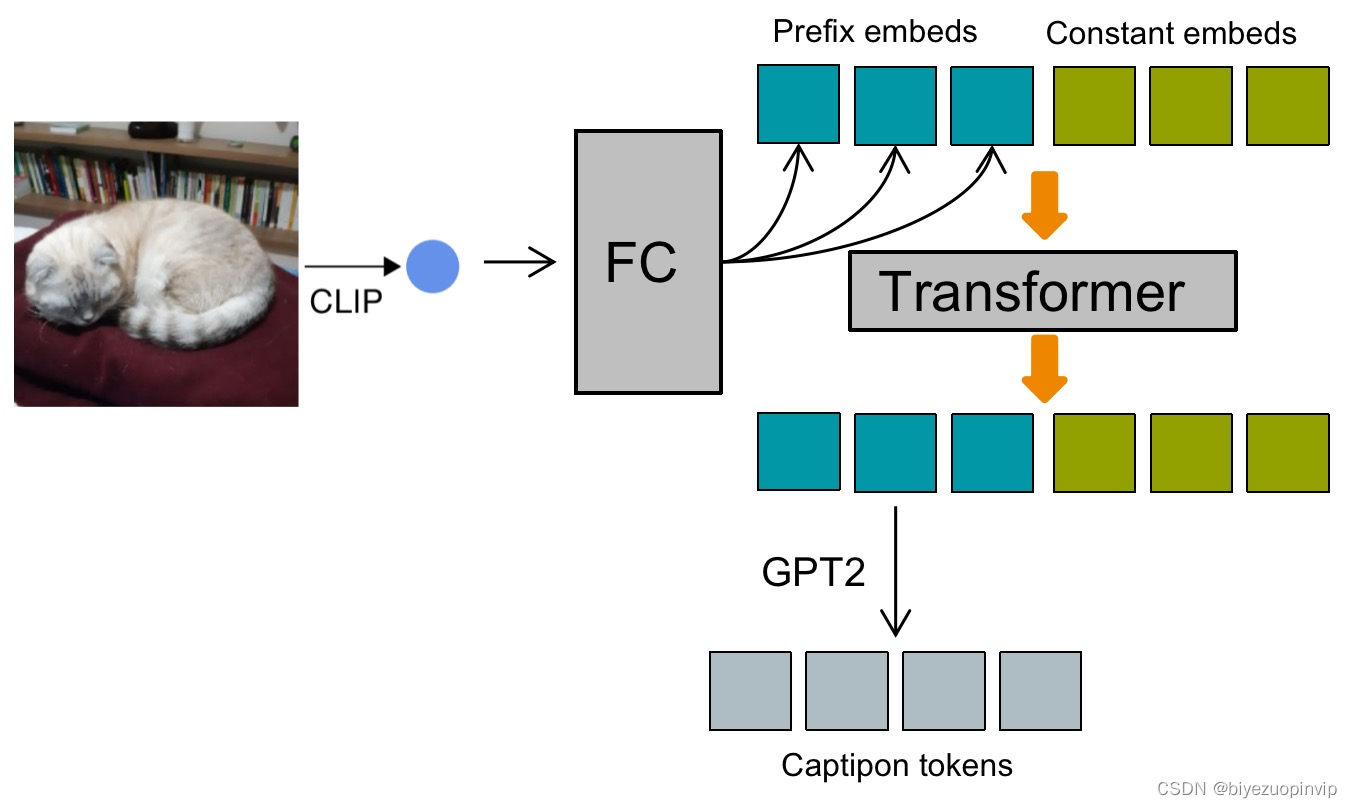
使用Transformer作为CLIP与GPT2模型之间的桥梁。具体做法如下: 首先将图片向量clip_embed经过一层全连接层,映射成提示向量序列prefix_embeds。Transformer中还维护了一个可学习的constant_embeds,将prefix_embeds与constant_embeds进行concat操作,然后输入到Transforemer中,让prefix_embeds与constant_embeds进行充分的交互。将prefix_embeds在Transformer对应的输出作为最终的prefix_embeds,作为GPT2模型的提示信息,生成最终的caption。在该方法中,作者引入了constant embeds,这是一个向量序列,目的是为了让其能够在多头注意力中,捕获到prefix_embeds中携带的语义信息。
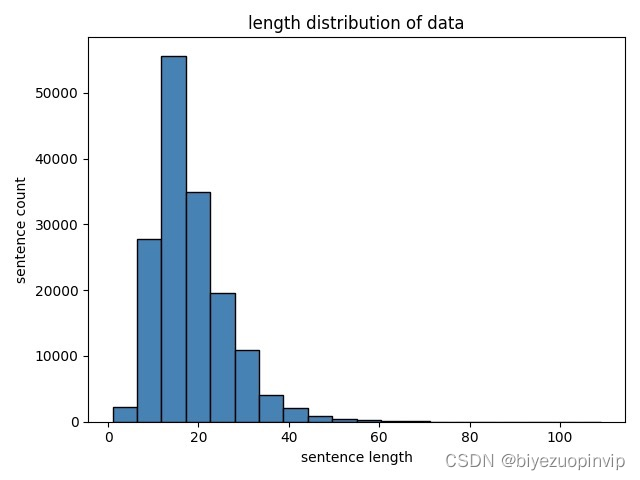
安装依赖包: pip install -r requirements.txt数据预处理(主要是对图像进行编码,得到train.pkl): python process_flickr.py训练MLP+GPT2 tuning: bash scripts/train_finetune_gpt2.sh训练Bert+GPT2 no_tuning: bash scripts/train_no_finetune_gpt2.sh使用MLP+GPT2 tuning进行生成: bash scripts/predict_finetune_gpt2.sh使用Bert+GPT2 no_tuning进行生成: bash scripts/predict_no_finetune_gpt2.sh 实验介绍 数据集图片与caption分别来自:Flickr30k数据集 与 机器翻译得到的中文caption数据 使用脚本,对caption进行预处理: python process_caption.pycaption被统一处理成以下格式,其中第一列为image_id,第二列为caption,并且每张图有多个caption: 1000092795 两个年轻小伙子的头发浓密的看着他们的手在院子里闲逛 1000092795 两只年轻的白色的男性在附近的许多灌木丛 1000092795 绿色衬衫的男人站在一个院子里 1000092795 一个穿蓝色衬衫的人站在花园里 1000092795 朋友们一起享受时光 10002456 几名在硬帽的男人是一个巨大的滑轮系统 10002456 工人从上面的一块设备上往下看 10002456 一个戴着头盔的机器的男人 10002456 四个男人在一个高大的结构上 10002456 三个男人在一个大的钻机caption的长度分布如下图:
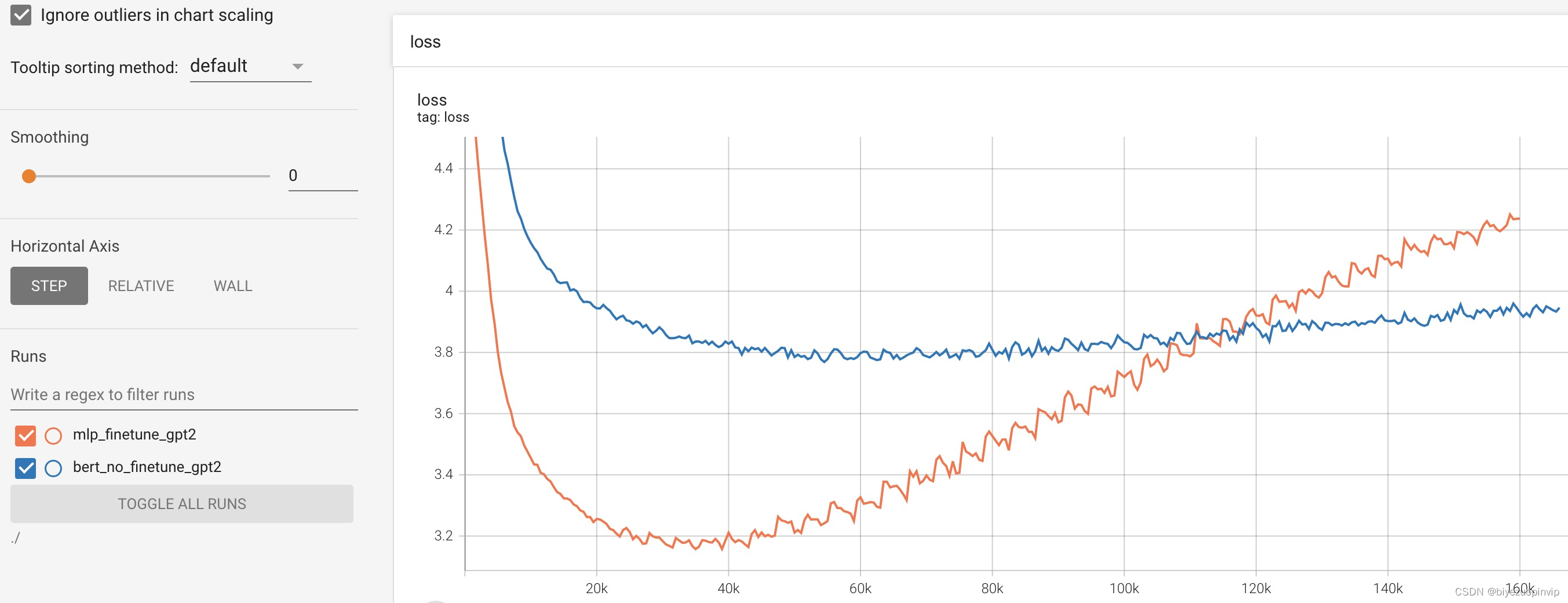
由于caption是使用机器翻译的,所以数据集中会存在翻译结果不佳的问题。翻译的badcase如下: 1003428081 至少有四个房间的窗帘玩乐器演奏单簧管等乐器 1003428081 四名妇女在一个客厅其中三个是清楚地演奏一种乐器 1003428081 一群老年妇女发挥单簧管一起为他们读出乐谱 100444898 一个大的结构已经坏了正在铺设一个巷道 1007205537 看门人推小车在管理员工具 10082348 在一个咖啡杯小便一个人站 100845130 五人走在五彩的天空背景除此之外,据观察数据集中存在很大一部分数据是以【一个、一群、一对】等数量为开头的caption,所以该数据集是有偏的。例如: 106691539 一个外科手术的外科医生和病人 1067180831 一只黑白相间的狗正试图在一个低切码中捕捉到一个黄色和紫色的物体 1067180831 一只黑色的狗正跳起来去抓一只紫色和绿色的玩具 1067180831 一只黑白相间的狗一只黄色的玩具跳了起来 1067180831 一只狗跳起来抓玩具 1067675215 一个人躺在一个棕色的和皮卡之间的门黄在停车场的垫子 1067675215 一个赤裸上身的男子躺在一条繁忙的马路中间 1067675215 一个穿着蓝色短裤的人在停车场外面躺了下来 1067675215 一个穿着蓝色短裤的人躺在街上 1067790824 一条白色和黑色的狗一只棕色的狗在沙地上基于flickr中文caption存在以上问题,后续会尝试使用更高质量的中文数据集进行训练。 实验细节 图像编码器与文本生成器分别使用CLIP与中文GPT2,预训练权重分别使用的是【ViT-B/32 】 【GPT2模型分享-通用中文模型 】。Mapping Network分别使用MLP与Bert进行实现(原文的Transformer本质上也是8层多头注意力进行堆叠)训练的时候,CLIP模型的权重均被冻结。在MLP+GPT2 tuning的训练中MLP与GPT2的权重均进行finetune;而在Bert+GPT2 no_tuning的训练中,只对Bert的权重进行finetune,并且Bert没有加载预训练权重,为随机初始化。Bert为8层多头注意力的堆叠。训练时的batch size为40,epoch为40,学习率为2e-5,prefix_len为10,constant_len为10,clip_size为512,warmup_step为5000。在生成阶段,对于每张图片,使用topp采样(核采样)生成10个候选的caption, 其中p设为0.8。 训练过程分析训练过程中,模型在验证集上的loss的变化,可以在output文件夹下查看,运行如下脚本: tensorboard --logdir ./output训练过程中,模型在验证集上的变化曲线如下图: 简单的总结: 仅从验证集loss的角度,可以看到,相比于Bert+GPT2 no_tuning,MLP+GPT2 tuning的收敛速度更快,并且能够达到更好的效果。 这也比较符合常理,因为在MLP+GPT2 tuning中,MLP与GPT2模型的参数是一起训练的,使得文本空间往图像空间靠拢。而在Bert+GPT2 no_tuning中, 只有Bert参数在进行训练,而GPT2是固定的,因此Bert的训练难度更高。训练30-40k步的时候,模型趋于收敛,继续训练模型loss不降反升,说明此时模型已经过拟合了。可以尝试使用更大的数据集来解决该问题。 生成效果为了验证模型的caption生成效果,我们分别在dev和test这两个小批量图片上进行caption生成。对于每张图片,使用topp采样(核采样)生成10个候选的caption, 其中p设为0.8。dev与test数据说明如下: 数据数据来源数据路径生成路径dev训练时候的验证数据datasets/devoutput/devtest从flickr blog 网站首页随机下载的图片datasets/testoutput/test Dev生成效果下表展示了模型在Dev图片上的生成效果。其中每张图对应两个生成caption,其中第一行为MLP+GPT2 tuning生成的,第二行为Bert+GPT2 no_tuning生成的
下面为多结果展示,可以明显看到MLP+GPT2 tuning的生成效果好于Bert+GPT2 no_tuning。更多生成caption可查看目录output/dev。
MLP+GPT2 tuning生成的10个case如下: 一个穿红色衬衣和牛仔裤的人在木制的建筑物外面走 一个穿着牛仔裤和恤衫的年轻人站在一个棕色的混凝土结构外 一个穿红色衬衣的人正在走下楼梯 一个穿着牛仔裤和一件红色恤衫的人在楼梯上走着 一个穿着蓝色牛仔裤和红色恤衫的人在外面 一个人走在一个高高的篱笆上 一个人站在一个残桩上一个水桶 一个穿着牛仔裤和恤衫的年轻人站在一个木门旁边一个手推车 一个男人正走在一个停车场 一个人带着一顶红色的帽子和一条红色的围巾看起来他正走在一个小木屋里Bert+GPT2 no_tuning生成的10个case如下: 一个穿着红色衬衫的人在一个自行车棚 一个穿红色衬衫的男人在一个空旷的街道 一个年轻的男人走在一个小的院子 一个穿着灰色裤子和灰色衬衫的人是在一个农庄里走的 一个穿红色衬衫的年轻人走在红色衬衫外面的围栏外 一个穿着灰色和黑色夹克的男人走在一个地方 一个人在房间里打着什么 一个人踩在一个红色的高跟鞋的门槛上 一个年轻人从楼上的建筑物开始跑步穿着拖鞋在院子里 一个穿着衬衫和蓝色牛仔裤的男人正在操作他的人 Test生成效果下表展示了MLP+GPT2 tuning模型在Test图片上的生成效果。更多生成caption可查看目录output/test。
可以看到模型生成的前几个caption,无论语义还是流畅度都与图片相符,即使后面几个case在流畅性方面存在不足,但是却都能捕获到图片中【女人、白色衣服】这一关键信息。
可以看到,在下列生成的10个caption里,几乎所有caption都捕获到了关键信息【电脑】,并且绝大部分caption都能较为准确地对图片进行描述
可以看到,模型倾向于以【一个】作为开头去生成caption,这是由于训练集本身就是有偏的,大部分数据都是以数量词作为开头。 对于该图片,虽然模型生成的大部分caption都没能百分百准确地描述语义信息,但是却生成了【湖、敲、夕阳、日落、水】等于图片语义相关的关键词, 所以模型在一定程度上还是能够将图片与文本的语义信息联系起来。 资源下载地址:https://download.csdn.net/download/sheziqiong/85908050 资源下载地址:https://download.csdn.net/download/sheziqiong/85908050 |







【本文地址】