| Ceph 管理和使用 | 您所在的位置:网站首页 › ceph的端口 › Ceph 管理和使用 |
Ceph 管理和使用
|
ceph 管理
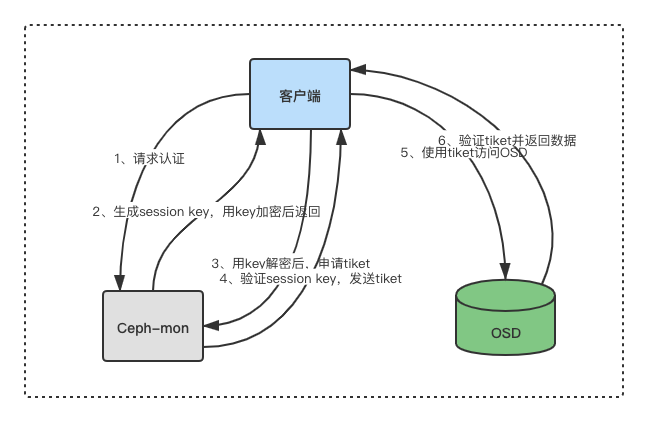
上次介绍了Ceph集群架构并且搭建了ceph集群,本节介绍ceph用户认证流程和挂载、cephFS、ceph RBD以及ceph mds高可用 1. ceph 授权流程和用户权限管理 1.1. ceph 认证机制Ceph 使用 cephx 协议对客户端进行身份认证。cephx 用于对 ceph 保存的数据进行认证访问和授权,用于对访问 ceph 的请求进行认证和授 权检测,与 mon 通信的请求都要经过 ceph 认证通过,但是也可以在 mon 节点关闭 cephx 认证,但是关闭认证之后任何访问都将被允许,因此无法保证数据的安全性。 1.1.1. 授权流程首先客户端向 ceph-mon 服务请求数据,mon 节点会返回用于身份认证的数据结构,其中包含获取 ceph 服务时用到的 session key,session key 通过客户端秘钥进行加密,秘钥是在客户端提前配置好的,/etc/ceph/ceph.client.admin.keyring,客户端使用key解密后得到session key, 然后使用 session key 向 ceph-mon 请求所需要的服务,ceph-mon 收到请求后会向客户端提供一个 tiket,用于向实际处理数据的 OSD 等服务验证客户端身份, ceph-mon 和 ceph-osd 服务共享同一个 secret,因此 ceph-osd 会信任所有 ceph-mon 发放的 tiket。 每个 ceph-mon 节点都可以对客户端进行身份认证并分发秘钥,因此多个 ceph-mon 节点就不存在单点故障和认证性能瓶颈。同时请注意,tiket 存在有效期,认证流程图如下:
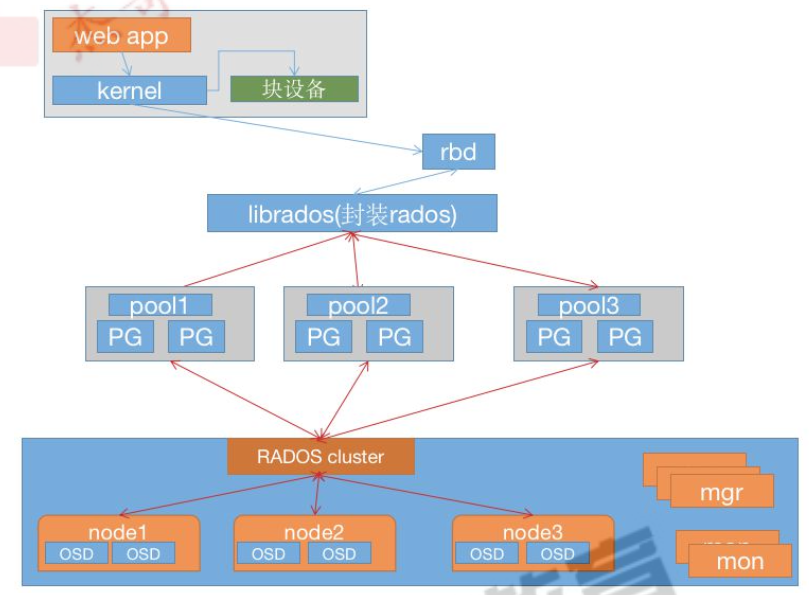
无论 ceph 客户端是哪种类型,例如块设备、对象存储、文件系统,ceph 都会在存储池中将所有数据存储为对象: ceph 用户需要拥有存储池访问权限,才能读取和写入数据 ceph 用户必须拥有执行权限才能使用 ceph 的管理命令 1.2 ceph 用户管理用户是指个人(ceph 管理者)或系统参与者(MON/OSD/MDS)。通过创建用户,可以控制用户或哪个参与者能够访问 ceph 存储集群、以及可访问的存储池 及存储池中的数据。ceph 支持多种类型的用户,但可管理的用户都属于 client 类型区分用户类型的原因在于,MON/OSD/MDS 等系统组件都使用 cephx 协议,但是它们不算是客户端。 用户管理功能可让 Ceph 集群管理员能够直接在 Ceph 集群中创建、更新和删除用户。 在 Ceph 集群中创建或删除用户时,可能需要将密钥分发到客户端,以便将密钥添加到密钥环文件中/etc/ceph/ceph.client.admin.keyring,此文件中可以包含一个或者多个用户认证信息,凡是拥有此文件的节点,将具备访问 ceph 的权限,而且可以使用其中任何一个账户的权限,此文件类似于 linux 系统的中的/etc/passwd 文件。 # 列出用户 ubuntu@ceph-deploy:~$ sudo ceph auth list installed auth entries: osd.0 key: AQD2GxphV+RyDBAAQFRomuzg4uDfIloEq5BI1g== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.1 key: AQC6HBph1knDMhAA35GE09CWb6OLmS5JqmJQOQ== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.10 key: AQBUHRphi4mpBBAAoWWLdTr4g6o6ACRS5N1OQw== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.11 key: AQBfHRphtKOUDRAA29zlbCF0ucKFP7lAo+zrIQ== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.12 key: AQBsHRphvK+HORAAT5bs2AlrqrMEw7gtu21bMQ== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.13 key: AQB4HRphOHNuEhAAa98YTpyZFo/mrS3BmNHnTg== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.14 key: AQCDHRphWeMVGxAA+NagThVA2EhR/f8w5a+3SA== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.15 key: AQCOHRphFZOUJxAArQGoaoRw3B8D1aJ6ixv+9g== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.2 key: AQDFHBphCMUdNRAAZnDeDQE5QqTkBSiE2aXYeA== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.21 key: AQAMZCBhQAFIHhAAM5NaqCIldLooGGV0EI3j3A== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.3 key: AQAnryFhN432FBAAeUMWfj0O7jraGwRfMXMoJQ== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.4 key: AQANHRphwInjJBAA7vOTTU2kfLVthu0tuRTjRw== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.5 key: AQAYHRph3xokMRAAyqYTH0DBO8RPbhEH/mn7vQ== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.6 key: AQAjHRphKMkMMRAAOPxDEQK/zQ+HDO31ONl95A== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.7 key: AQAuHRphiH+cOhAAAdQNL/bausHnAWyokLISEg== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.8 key: AQA9HRph8Xp0ExAAVNo/SvF9GNZWZT69+eDgeQ== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * osd.9 key: AQBIHRphEYHPNhAAkOM4JfKztb+RpVaJ2gyplQ== caps: [mgr] allow profile osd caps: [mon] allow profile osd caps: [osd] allow * client.admin key: AQD+BBphi27lEhAAMrU7KnwfJfn8SvOTVubqZQ== caps: [mds] allow * caps: [mgr] allow * caps: [mon] allow * caps: [osd] allow * client.bootstrap-mds key: AQD+BBphn4TlEhAAZIRY7MzA5EmBBn6VIB0NWQ== caps: [mon] allow profile bootstrap-mds client.bootstrap-mgr key: AQD+BBphFJPlEhAAXIb6KfAtBAS6SDU6TW9pCA== caps: [mon] allow profile bootstrap-mgr client.bootstrap-osd key: AQD+BBph8p/lEhAAlZzVZrUoKFMsHqzZV/eT+g== caps: [mon] allow profile bootstrap-osd client.bootstrap-rbd key: AQD+BBphwK3lEhAAkx5vuPcOg25bLKS+14HoFA== caps: [mon] allow profile bootstrap-rbd client.bootstrap-rbd-mirror key: AQD+BBphXrvlEhAAtPPtNSikm8u8zPmamAUhqQ== caps: [mon] allow profile bootstrap-rbd-mirror client.bootstrap-rgw key: AQD+BBph7cflEhAA9LZFIKACQh7CeK6E/EeB+Q== caps: [mon] allow profile bootstrap-rgw mgr.ceph-mgr1 key: AQCmFBphsiG/NRAAKgyv3gbmwv30PDMgmMPegw== caps: [mds] allow * caps: [mon] allow profile mgr caps: [osd] allow * mgr.ceph-mgr2 key: AQBQJBphSEBXNhAAH+NZhGJipY8IRw4YOIeOww== caps: [mds] allow * caps: [mon] allow profile mgr caps: [osd] allow * # 列出指定用户信息 ubuntu@ceph-deploy:~$ sudo ceph auth get client.admin exported keyring for client.admin [client.admin] key = AQD+BBphi27lEhAAMrU7KnwfJfn8SvOTVubqZQ== caps mds = "allow *" caps mgr = "allow *" caps mon = "allow *" caps osd = "allow *"注意: TYPE.ID 表示法 针对用户采用TYPE.ID表示法,例如osd.0指定是osd类并且ID为0的用户(节点),client.admin 是 client 类型的用户,其 ID 为 admin。 另请注意,每个项包含一个 key=xxx 项,以及一个或多个 caps 项。 可以结合使用-o 文件名选项和 ceph auth list 将输出保存到某个文件 $ ceph auth list -o client.admin.key 1.2.1. ceph授权ceph 基于使能/能力(Capabilities,简称 caps )来描述用户,可针对 MON/OSD 或 MDS 使用的授权范围或级别。 通用的语法格式:daemon-type 'allow caps' [...] 能力一览表: 权限 说明 r 向用户授予读取权限。访问监视器(mon)以检索 CRUSH 运行图时需具有此能力。 w 向用户授予针对对象的写入权限。 x 授予用户调用类方法(包括读取和写入)的能力,以及在监视器中执行 auth 操作的能力。 * 授予用户对特定守护进程/存储池的读取、写入和执行权限,以及执行管理命令的能力 class-read 授予用户调用类读取方法的能力,属于是 x 能力的子集。 class-write 授予用户调用类写入方法的能力,属于是 x 能力的子集。 profile osd 授予用户以某个 OSD 身份连接到其他 OSD 或监视器的权限。授予 OSD 权限,使 OSD 能够处理复制检测信号流量和状态报告。 profile mds 授予用户以某个 MDS 身份连接到其他 MDS 或监视器的权限。 profile bootstrap-osd 授予用户引导 OSD 的权限(初始化 OSD 并将 OSD 加入 ceph 集群),授 权给部署工具,使其在引导 OSD 时有权添加密钥。 profile bootstrap-mds 授予用户引导元数据服务器的权限,授权部署工具权限,使其在引导 元数据服务器时有权添加密钥。MON 能力: 包括 r/w/x 和 allow profile cap(ceph 的运行图),示例: mon 'allow rwx' mon 'allow profile osd'OSD 能力: 包括 r、w、x、class-read、class-write(类读取))和 profile osd(类写入),另外 OSD 能力还允许进行存储池和名称空间设置。 osd 'allow capability' [pool=poolname] [namespace=namespace-name]MDS 能力: 只需要 allow 或空都表示允许。 mds 'allow' 1.2.2. 管理操作添加一个用户会创建用户名 (TYPE.ID)、机密密钥,以及包含在命令中用于创建该用户的所 有能力,用户可使用其密钥向 Ceph 存储集群进行身份验证。用户的能力授予该用户在 Ceph monitor (mon)、Ceph OSD (osd) 或 Ceph 元数据服务器 (mds) 上进行读取、写入或执行的 能力,可以使用以下几个命令来添加用户: ceph auth add此命令是添加用户的规范方法。它会创建用户、生成密钥,并添加所有指定的能力。 # 先创建一个存储池,现有集群一共16个osd,根据官方建议,每个osd一般建议100~200个PG,而我们的osd磁盘控件较小,定为60个PG每个osd,总的可设置的PG 16 x 60 / 3 = 320个可设置的PG,每个存储池的PG暂定为32个总共可设置10个pool # 1、创建存储池 ubuntu@ceph-deploy:~$ sudo ceph osd pool create mypool1 32 32 pool 'mypool1' created ubuntu@ceph-deploy:~$ sudo ceph osd lspools 1 device_health_metrics 5 mypool1 # 给客户端alice添加认证key ubuntu@ceph-deploy:~$ sudo ceph auth add client.alice mon 'allow r' osd 'allow rwx pool=mypool1' added key for client.alice ubuntu@ceph-deploy:~$ sudo ceph auth get client.alice exported keyring for client.alice [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=mypool1" ceph auth get-or-createceph auth get-or-create 此命令是创建用户较为常见的方式之一,它会返回包含用户名(在方括号中)和密钥的密钥文,如果该用户已存在,此命令只以密钥文件格式返回用户名和密钥, 还可以使用 -o 指定文件名选项将输出保存到某个文件。 # 创建一个新用户 ubuntu@ceph-deploy:~$ sudo ceph auth get-or-create client.tom mon 'allow r' osd 'allow rwx pool=mypool1' [client.tom] key = AQAzBSJhCK/wIBAAxdwEVBMIy53xxRLOHjPVYg== # 验证用户 ubuntu@ceph-deploy:~$ sudo ceph auth get client.tom exported keyring for client.tom [client.tom] key = AQAzBSJhCK/wIBAAxdwEVBMIy53xxRLOHjPVYg== caps mon = "allow r" caps osd = "allow rwx pool=mypool1" # 再次创建 ubuntu@ceph-deploy:~$ sudo ceph auth get-or-create client.tom mon 'allow r' osd 'allow rwx pool=mypool1' [client.tom] key = AQAzBSJhCK/wIBAAxdwEVBMIy53xxRLOHjPVYg==ceph auth get-or-create-key 此命令是创建用户并仅返回用户密钥,对于只需要密钥的客户端(例如 libvirt),此命令非 常有用。如果该用户已存在,此命令只返回密钥。您可以使用 -o 文件名选项将输出保存到 某个文件。 创建客户端用户时,可以创建不具有能力的用户。不具有能力的用户可以进行身份验证,但 不能执行其他操作,此类客户端无法从监视器检索集群地图,但是,如果希望稍后再添加能 力,可以使用 ceph auth caps 命令创建一个不具有能力的用户。 典型的用户至少对 Ceph monitor 具有读取功能,并对 Ceph OSD 具有读取和写入功能。此外,用户的 OSD 权限通常限制为只能访问特定的存储池。 ubuntu@ceph-deploy:~$ sudo ceph auth get-or-create-key client.tom mon 'allow r' osd 'allow rwx pool=mypool1' AQAzBSJhCK/wIBAAxdwEVBMIy53xxRLOHjPVYg== # 用户有 key 就显示没有就创建 ceph auth print-key只获取单个指定用户的 key 信息 ubuntu@ceph-deploy:~$ sudo ceph auth print-key client.alice AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== 修改用户能力使用 ceph auth caps 命令可以指定用户以及更改该用户的能力,设置新能力会完全覆盖当前 的能力,因此要加上之前的用户已经拥有的能和新的能力,如果看当前能力,可以运行 ceph auth get USERTYPE.USERID,如果要添加能力,使用以下格式时还需要指定现有能力: # ceph auth caps USERTYPE.USERID daemon 'allow [r|w|x|*|...] \ [pool=pool-name] [namespace=namespace-name]' [daemon 'allow [r|w|x|*|...] \ [pool=pool-name] [namespace=namespace-name]']示例 # 查看用户当前权限 ubuntu@ceph-deploy:~$ sudo ceph auth get client.tom exported keyring for client.tom [client.tom] key = AQAzBSJhCK/wIBAAxdwEVBMIy53xxRLOHjPVYg== caps mon = "allow r" caps osd = "allow rwx pool=mypool1" # 修改用户权限 ubuntu@ceph-deploy:~$ sudo ceph auth caps client.tom mon 'allow r' osd 'allow rw pool=mypool1' updated caps for client.tom # 验证 ubuntu@ceph-deploy:~$ sudo ceph auth get client.tom exported keyring for client.tom [client.tom] key = AQAzBSJhCK/wIBAAxdwEVBMIy53xxRLOHjPVYg== caps mon = "allow r" caps osd = "allow rw pool=mypool1" 删除用户 # 要删除用户使用 ceph auth del TYPE.ID,其中 TYPE 是 client、osd、mon 或 mds 之一,ID 是用户名或守护进程的 ID。 ubuntu@ceph-deploy:~$ sudo ceph auth del client.tom updated ubuntu@ceph-deploy:~$ sudo ceph auth get client.tom Error ENOENT: failed to find client.tom in keyring ubuntu@ceph-deploy:~$ sudo ceph auth get client.alice exported keyring for client.alice [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=mypool1" 1.3. 秘钥环管理ceph 的秘钥环是一个保存了 secrets、keys、certificates 并且能够让客户端通认证访问 ceph 的 keyring file(集合文件),一个 keyring file 可以保存一个或者多个认证信息,每一个 key 都有一个实体名称加权限,类型为: {client、mon、mds、osd}.name当客户端访问 ceph 集群时,ceph 会使用以下四个密钥环文件预设置密钥环设置: /etc/ceph/...keyring # 保存单个用户的 keyring /etc/ceph/cluster.keyring # 保存多个用户的 keyring /etc/ceph/keyring # 未定义集群名称的多个用户的 keyring /etc/ceph/keyring.bin # 编译后的二进制文件 1.3.1. 通过秘钥环文件备份与恢复用户使用 ceph auth add 等命令添加的用户还需要额外使用 ceph-authtool 命令为其创建用户秘钥环文件。创建 keyring 文件命令格式: ceph-authtool --create-keyring FILE 1.3.1.1 导出用户认证信息至 keyring 文件 # 创建密钥环文件 ubuntu@ceph-deploy:~$ ceph-authtool --create-keyring ceph.client.alice.keyring creating ceph.client.alice.keyring ubuntu@ceph-deploy:~$ ls ceph-cluster ceph.client.alice.keyring ubuntu@ceph-deploy:~$ cat ceph.client.alice.keyring ubuntu@ceph-deploy:~$ file ceph.client.alice.keyring ceph.client.alice.keyring: empty # 导出 keyring 到指定文件 ubuntu@ceph-deploy:~$ sudo ceph auth get client.alice -o ceph.client.alice.keyring exported keyring for client.alice ubuntu@ceph-deploy:~$ cat ceph.client.alice.keyring [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=mypool1"在创建包含单个用户的密钥环时,通常建议使用 ceph 集群名称、用户类型和用户名及 keyring 来命名,并将其保存在 /etc/ceph 目录中。例如为 client.alice 用户创建 ceph.client.alice.keyring。 1.3.1.2 从 keyring 文件恢复用户认证信息可以使用 ceph auth import -i 指定 keyring 文件并导入到 ceph,其实就是起到用户备份和恢复的目的: # 验证用户 ubuntu@ceph-deploy:/etc/ceph$ sudo ceph auth get client.alice exported keyring for client.alice [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=mypool1" # 删除用户 ubuntu@ceph-deploy:/etc/ceph$ sudo ceph auth del client.alice updated # 验证 ubuntu@ceph-deploy:/etc/ceph$ sudo ceph auth get client.alice Error ENOENT: failed to find client.alice in keyring ubuntu@ceph-deploy:/etc/ceph$ cd ~/ ubuntu@ceph-deploy:~$ ls ceph-cluster ceph.client.alice.keyring # 恢复账户 ubuntu@ceph-deploy:~$ sudo ceph auth import -i ceph.client.alice.keyring imported keyring # 验证用户 ubuntu@ceph-deploy:~$ sudo ceph auth get client.alice exported keyring for client.alice [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=mypool1" 1.3.2 秘钥环文件多用户一个 keyring 文件中可以包含多个不同用户的认证文件。 将多用户导出至秘钥环: # 创建一个空的 keyring ubuntu@ceph-deploy:~$ ceph-authtool --create-keyring ceph.client.user1.keyring creating ceph.client.user1.keyring # 把指定的 admin 用户的 keyring 文件内容导入到 user1 用户的 keyring 文件 ubuntu@ceph-deploy:~$ sudo ceph-authtool --import-keyring /etc/ceph/ceph.client.admin.keyring ceph.client.user1.keyring importing contents of /etc/ceph/ceph.client.admin.keyring into ceph.client.user1.keyring # 验证 ubuntu@ceph-deploy:~$ sudo ceph-authtool -l ceph.client.user1.keyring [client.admin] key = AQD+BBphi27lEhAAMrU7KnwfJfn8SvOTVubqZQ== caps mds = "allow *" caps mgr = "allow *" caps mon = "allow *" caps osd = "allow *" # 导入另一个用户的密钥环 ubuntu@ceph-deploy:~$ sudo ceph-authtool --import-keyring ceph.client.alice.keyring ceph.client.user1.keyring importing contents of ceph.client.alice.keyring into ceph.client.user1.keyring # 验证 ubuntu@ceph-deploy:~$ sudo ceph-authtool -l ceph.client.user1.keyring [client.admin] key = AQD+BBphi27lEhAAMrU7KnwfJfn8SvOTVubqZQ== caps mds = "allow *" caps mgr = "allow *" caps mon = "allow *" caps osd = "allow *" [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=mypool1" 2. 普通用户挂载rbd和cephfs 2.1 Ceph RBD 使用RBD 架构图 Ceph 可以同时提供对象存储 RADOSGW、块存储 RBD、文件系统存储 Ceph FS,RBD 即 RADOS Block Device 的简称,RBD 块存储是常用的存储类型之一,RBD 块设备类似磁盘可以被挂载, RBD 块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在 Ceph 集 群的多个 OSD 中。 条带化技术就是一种自动的将 I/O 的负载均衡到多个物理磁盘上的技术,条带化技术就是将一块连续的数据分成很多小部分并把他们分别存储到不同磁盘上去。这就能使多个进程同时访问数据的多个不同部分而不会造成磁盘冲突,而且在需要对这种数据进行顺序访问的时候可以获得最大程度上的 I/O 并行能力,从而获得非常好的性能。
创建 img 映像 # rbd 存储池并不能直接用于块设备,而是需要事先在其中按需创建映像(image),并把映像文件作为块设备使用。rbd 命令可用于创建、查看及删除块设备相在的映像(image), 以及克隆映像、创建快照、将映像回滚到快照和查看快照等管理操作。例如,下面的命令能够在指定的 RBD 即 rbd-1 创建一个名为 rbd-img-1 的映像 ubuntu@ceph-deploy:~$ sudo rbd create rbd-img-1 --size 3G --pool rbd-pool-1 --image-format 2 --image-feature layering ubuntu@ceph-deploy:~$ sudo rbd create rbd-img-2 --size 5G --pool rbd-pool-1 --image-format 2 --image-feature layering # 验证 ubuntu@ceph-deploy:~$ sudo rbd ls --pool rbd-pool-1 rbd-img-1 rbd-img-2 # 列出详细信息 ubuntu@ceph-deploy:~$ sudo rbd ls --pool rbd-pool-1 -l NAME SIZE PARENT FMT PROT LOCK rbd-img-1 3 GiB 2 rbd-img-2 5 GiB 2查看镜像的详细信息 ubuntu@ceph-deploy:~$ sudo rbd --image rbd-img-1 --pool rbd-pool-1 info rbd image 'rbd-img-1': size 3 GiB in 768 objects order 22 (4 MiB objects) snapshot_count: 0 id: d41dee2cd129 block_name_prefix: rbd_data.d41dee2cd129 format: 2 features: layering op_features: flags: create_timestamp: Sun Aug 22 08:53:33 2021 access_timestamp: Sun Aug 22 08:53:33 2021 modify_timestamp: Sun Aug 22 08:53:33 2021 ubuntu@ceph-deploy:~$ sudo rbd --image rbd-img-2 --pool rbd-pool-1 info rbd image 'rbd-img-2': size 5 GiB in 1280 objects order 22 (4 MiB objects) snapshot_count: 0 id: d420cab622d4 block_name_prefix: rbd_data.d420cab622d4 format: 2 features: layering op_features: flags: create_timestamp: Sun Aug 22 08:53:48 2021 access_timestamp: Sun Aug 22 08:53:48 2021 modify_timestamp: Sun Aug 22 08:53:48 2021以 json 格式显示镜像信息 ubuntu@ceph-deploy:~$ sudo rbd ls --pool rbd-pool-1 -l --format json --pretty-format [ { "image": "rbd-img-1", "id": "d41dee2cd129", "size": 3221225472, "format": 2 }, { "image": "rbd-img-2", "id": "d420cab622d4", "size": 5368709120, "format": 2 } ]镜像的其他特性 layering: 支持镜像分层快照特性,用于快照及写时复制,可以对 image 创建快照并保护,然 后从快照克隆出新的 image 出来,父子 image 之间采用 COW 技术,共享对象数据。默认添加的特性 striping: 支持条带化 v2,类似 raid 0,只不过在 ceph 环境中的数据被分散到不同的对象中, 可改善顺序读写场景较多情况下的性能。 exclusive-lock: 支持独占锁,限制一个镜像只能被一个客户端使用。 object-map: 支持对象映射(依赖 exclusive-lock),加速数据导入导出及已用空间统计等,此特 性开启的时候,会记录 image 所有对象的一个位图,用以标记对象是否真的存在,在一些场 景下可以加速 io。 fast-diff: 快速计算镜像与快照数据差异对比(依赖 object-map)。 deep-flatten: 支持快照扁平化操作,用于快照管理时解决快照依赖关系等。 journaling: 修改数据是否记录日志,该特性可以通过记录日志并通过日志恢复数据(依赖独 占锁),开启此特性会增加系统磁盘 IO 使用。 jewel 默认开启的特性包括: layering/exlcusive lock/object map/fast diff/deep flatten 镜像特性的启用 # 启用指定存储池中的指定镜像的特性 ubuntu@ceph-deploy:~$ sudo rbd feature enable exclusive-lock --pool rbd-pool-1 --image rbd-img-1 ubuntu@ceph-deploy:~$ sudo rbd feature enable object-map --pool rbd-pool-1 --image rbd-img-1 ubuntu@ceph-deploy:~$ sudo rbd feature enable fast-diff --pool rbd-pool-1 --image rbd-img-1 # 验证镜像特性 ubuntu@ceph-deploy:~$ sudo rbd info --image rbd-img-1 --pool rbd-pool-1 rbd image 'rbd-img-1': size 3 GiB in 768 objects order 22 (4 MiB objects) snapshot_count: 0 id: d41dee2cd129 block_name_prefix: rbd_data.d41dee2cd129 format: 2 features: layering, exclusive-lock, object-map, fast-diff op_features: flags: object map invalid, fast diff invalid create_timestamp: Sun Aug 22 08:53:33 2021 access_timestamp: Sun Aug 22 08:53:33 2021 modify_timestamp: Sun Aug 22 08:53:33 2021镜像特性的禁用 ubuntu@ceph-deploy:~$ sudo rbd feature disable fast-diff --pool rbd-pool-1 --image rbd-img-1 ubuntu@ceph-deploy:~$ sudo rbd feature disable exclusive-lock --pool rbd-pool-1 --image rbd-img-1 ubuntu@ceph-deploy:~$ sudo rbd info --image rbd-img-1 --pool rbd-pool-1 rbd image 'rbd-img-1': size 3 GiB in 768 objects order 22 (4 MiB objects) snapshot_count: 0 id: d41dee2cd129 block_name_prefix: rbd_data.d41dee2cd129 format: 2 features: layering op_features: flags: create_timestamp: Sun Aug 22 08:53:33 2021 access_timestamp: Sun Aug 22 08:53:33 2021 modify_timestamp: Sun Aug 22 08:53:33 2021 2.2 配置客户端使用 RBD在客户端挂载 RBD,并使用普通用户挂载 RBD 并验证使用。 客户端需要安装ceph-common # 1、添加源 ubuntu@client:~$ wget -q -O- 'https://download.ceph.com/keys/release.asc' | sudo apt-key add - ubuntu@client:~$ apt-add-repository 'deb https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-octopus/ bionic main' # 2、安装 ceph-common ubuntu@client:~$ sudo apt install -y ceph-common # 3、在客户端映射 rbd 映像 ubuntu@client:~$ sudo rbd map --pool rbd-pool-1 --image rbd-img-1 /dev/rbd0 ubuntu@client:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 30G 0 disk ├─sda1 8:1 0 1M 0 part ├─sda2 8:2 0 1G 0 part /boot └─sda3 8:3 0 29G 0 part └─ubuntu--vg-ubuntu--lv 253:0 0 20G 0 lvm / sr0 11:0 1 945M 0 rom rbd0 252:0 0 3G 0 disk # 4、使用普通用户挂载测试 ubuntu@ceph-deploy:~$ sudo ceph auth get client.alice exported keyring for client.alice [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=mypool1" # 更改用户权限 ubuntu@ceph-deploy:~$ sudo ceph auth caps client.alice mon 'allow r' osd 'allow rwx pool=rbd-pool-1' updated caps for client.alice ubuntu@ceph-deploy:~$ sudo ceph auth get client.alice exported keyring for client.alice [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=rbd-pool-1" # 5、创建密钥环并拷贝到客户端 ubuntu@ceph-deploy:~$ sudo ceph-authtool --create-keyring ceph.client.alice.keyring creating ceph.client.alice.keyring ubuntu@ceph-deploy:~$ sudo ceph auth get client.alice -o ceph.client.alice.keyring exported keyring for client.alice ubuntu@ceph-deploy:~$ sudo cat ceph.client.alice.keyring [client.alice] key = AQAwBCJhy/iIOBAAgPVXbcx1DP8yTssy90JB9g== caps mon = "allow r" caps osd = "allow rwx pool=rbd-pool-1" # 拷贝密钥环 ubuntu@ceph-deploy:~$ scp ceph.client.alice.keyring ubuntu@ceph-client:/etc/ceph # 6、查看集群,默认使用的是admin,需要使用 --user 指定用户 ubuntu@ceph-client:~$ sudo ceph --user alice -s cluster: id: b7c42944-dd49-464e-a06a-f3a466b79eb4 health: HEALTH_OK services: mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 8h) mgr: ceph-mgr1(active, since 32h), standbys: ceph-mgr2 osd: 16 osds: 16 up (since 7h), 16 in (since 7h) data: pools: 3 pools, 65 pgs objects: 10 objects, 51 B usage: 16 GiB used, 143 GiB / 160 GiB avail pgs: 65 active+clean # 7、使用普通用户映射rbd ubuntu@ceph-client:~$ sudo rbd device map --pool rbd-pool-1 --image rbd-img-1 --user alice /dev/rbd0 ubuntu@ceph-client:~$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 30G 0 disk ├─sda1 8:1 0 1M 0 part ├─sda2 8:2 0 1G 0 part /boot └─sda3 8:3 0 29G 0 part └─ubuntu--vg-ubuntu--lv 253:0 0 20G 0 lvm / sr0 11:0 1 945M 0 rom rbd0 252:0 0 3G 0 disk # 8、格式化并使用 ubuntu@ceph-client:~$ sudo mkfs.ext4 /dev/rbd0 mke2fs 1.44.1 (24-Mar-2018) Discarding device blocks: done Creating filesystem with 786432 4k blocks and 196608 inodes Filesystem UUID: bfcf3ca0-56ae-4cc1-a059-7579c98a4cd8 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912 Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: done # 创建挂载点 ubuntu@ceph-client:~$ sudo mkdir -p /data ubuntu@ceph-client:~$ sudo mount /dev/rbd0 /data/ ubuntu@ceph-client:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 954M 0 954M 0% /dev tmpfs 198M 11M 187M 6% /run /dev/mapper/ubuntu--vg-ubuntu--lv 20G 5.4G 14G 30% / tmpfs 986M 0 986M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 986M 0 986M 0% /sys/fs/cgroup /dev/sda2 976M 150M 759M 17% /boot tmpfs 198M 0 198M 0% /run/user/1000 /dev/rbd0 2.9G 9.0M 2.8G 1% /data # 通过nginx设置 ubuntu@ceph-client:~$ sudo apt install -y nginx ubuntu@ceph-client:~$ cd /data ubuntu@ceph-client:/data$ sudo mkdir -p www/html ubuntu@ceph-client:/data$ ls lost+found www ubuntu@ceph-client:/data$ cd www/html/ # 一个比较好看的index首页 ubuntu@ceph-client:/data/www/html$ sudo vim index.html Arch_Villain的个人主页 body{font-family: arial, sans-serif;background-color: #ddd;transition:1s;} .title{position: fixed;bottom: 0;left: 0;text-align: center;width: 100%;color:#454545;} .nav{overflow:hidden;position: fixed;bottom: 0;left: 0;height: 420px;width: 100%;} .navs{width: 800px;height: 840px;margin:0 auto;transform-origin:50% 50%;transition: 1s;transform:rotate(0deg);z-index: 0;} .rotate{animation: rotate1 20s linear infinite;} .navs li{position: absolute;left: 50%;top: 20px;margin-left: -50px;width: 100px;height: 100px;line-height:100px;transform-origin:50% 400px;text-align: center; border-radius:5px;transition:border-radius .3s,box-shadow 1s; box-shadow:0 0px 10px 0 rgba(0, 0, 0, 0.12); } .navs li:hover{border-radius:50%;z-index: 1;} .navs li a:hover{transform:scale(1.1);} .navs li a{text-decoration: none;color:#fff;font-family:Microsoft YaHei;font-size: 20px;display:inline-block;width: 100%;height: 100%;} ul,li{margin: 0;padding: 0;list-style:none;} @keyframes rotate1{ 0%{ transform:rotate(0deg); } 50%{ transform:rotate(180deg); } 100%{ transform:rotate(360deg); } } /*.resumes{text-align: center;margin-top: 50px;position: relative;z-index: 1;line-height:40px;} .resumes a{padding:5px 10px;background-color: #fff;text-decoration: none;color:#454545;font-family: microsoft YaHei;}*/ .octicon{vertical-align:middle;vertical-align:text-bottom;padding-right: 5px;width: 22px;height: 22px;} (function(){ function gc(){ return '#'+('00000'+(Math.random()*0x10000000?1:-1; //var nowAngle = navs.style.transform.match(/rotate\((-?\d+)deg\)/); //nowAngle = nowAngle==null?0:nowAngle[1]*1; //nowAngle += angle*d; nowData += -d; nowData = nowData>max-1?nowData%max:nowData cephfs-test.key # 查看集群 ubuntu@ceph-deploy:~/ceph-cluster$ sudo ceph -s --user cephfs-test cluster: id: b7c42944-dd49-464e-a06a-f3a466b79eb4 health: HEALTH_OK services: mon: 3 daemons, quorum ceph-mon1,ceph-mon2,ceph-mon3 (age 9h) mgr: ceph-mgr1(active, since 33h), standbys: ceph-mgr2 mds: cephfs-test-1:1 {0=ceph-mon1=up:active} osd: 16 osds: 16 up (since 8h), 16 in (since 8h) data: pools: 5 pools, 161 pgs objects: 58 objects, 75 MiB usage: 17 GiB used, 143 GiB / 160 GiB avail pgs: 161 active+clean # 挂载ceph文件系统 root@ceph-deploy:~# mount -t ceph -o name=cephfs-test,secretfile=cephfs-test.key 172.31.0.11:6789/ /data2 source mount path was not specified unable to parse mount source: -22 # 注意别少加冒号吆 root@ceph-deploy:~# mount -t ceph -o name=cephfs-test,secretfile=cephfs-test.key 172.31.0.11:6789:/ /data2 root@ceph-deploy:~# df -h Filesystem Size Used Avail Use% Mounted on udev 954M 0 954M 0% /dev tmpfs 198M 11M 187M 6% /run /dev/mapper/ubuntu--vg-ubuntu--lv 20G 5.5G 14G 30% / tmpfs 986M 0 986M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 986M 0 986M 0% /sys/fs/cgroup /dev/sda2 976M 150M 759M 17% /boot tmpfs 198M 0 198M 0% /run/user/1000 172.31.0.11:6789:/ 46G 0 46G 0% /data2 root@ceph-deploy:~# mkdir -p /data2/www/html/ root@ceph-deploy:~# vim /data2/www/html/index.html # 将之前的首页弄过来 root@ceph-deploy:~# vim /etc/nginx/sites-enabled/default # 修改nginx配置 root /data2/www/html; # 重启nginx服务访问页面成功
目前的状态是 ceph-mon1 和 ceph-mon3 分别是 active 状态,ceph-mon2 和 ceph-mgr1 分别处 于 standby 状态,现在可以将 ceph-mgr1 设置为 ceph-mon1 的 standby,将 ceph-mon3 设置 为 ceph-mon2 的 standby,以实现每个主都有一个固定备份角色的结构,则修改配置文件如 下: # 对应关系 ceph-mgr1 => ceph-mon1 ceph-mon3 => ceph-mon2 # 修改 ceph.conf 配置文件 ubuntu@ceph-deploy:~/ceph-cluster$ cat ceph.conf [global] fsid = b7c42944-dd49-464e-a06a-f3a466b79eb4 public_network = 172.31.0.0/24 cluster_network = 192.168.10.0/24 mon_initial_members = ceph-mon1 mon_host = 172.31.0.11 auth_cluster_required = cephx auth_service_required = cephx auth_client_required = cephx [mon] mon allow pool delete = true [mds.ceph-mgr1] mds_standby_for_name = ceph-mon1 mds_standby_replay = true [mds.ceph-mon3] mds_standby_for_name = ceph-mon2 mds_standby_replay = true 分发配置文件到mds服务器并重启服务 ubuntu@ceph-deploy:~/ceph-cluster$ ceph-deploy --overwrite-conf config push ceph-{mon1,mon2,mon3,mgr1} ubuntu@ceph-deploy:~/ceph-cluster$ for node in ceph-{mon1,mon2,mon3,mgr1}; do ssh $node "sudo systemctl restart ceph-mds@${node}" done ceph集群 mds 高可用状态 ubuntu@ceph-deploy:~/ceph-cluster$ sudo ceph fs status cephfs-test-1 - 1 clients ============= RANK STATE MDS ACTIVITY DNS INOS 0 active ceph-mon2 Reqs: 0 /s 18 16 1 active ceph-mon1 Reqs: 0 /s 10 13 POOL TYPE USED AVAIL cephfs-metadata-pool-1 metadata 3251k 45.0G cephfs-data-pool-1 data 192k 45.0G STANDBY MDS ceph-mon3 ceph-mgr1 MDS version: ceph version 15.2.14 (cd3bb7e87a2f62c1b862ff3fd8b1eec13391a5be) octopus (stable) # 高可用对应关系如下: ubuntu@ceph-deploy:~/ceph-cluster$ sudo ceph fs get cephfs-test-1
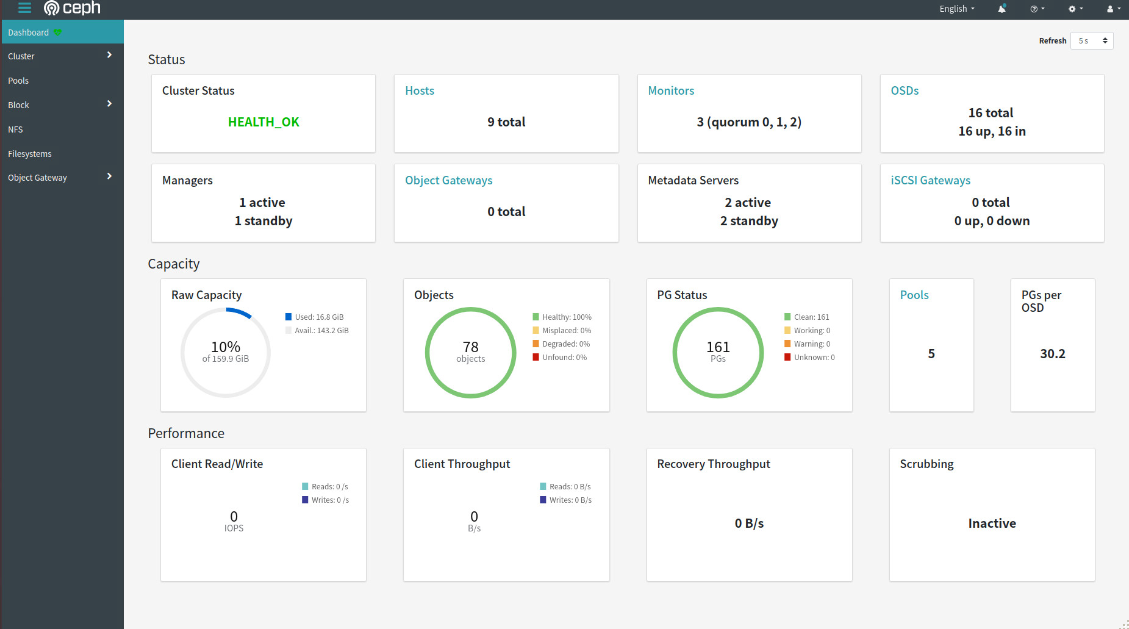
Ceph dashboard 是通过一个 web 界面,对已经运行的 ceph 集群进行状态查看及功能配置等 功能,早期 ceph 使用的是第三方的 dashboard 组件,如: CalamariCalamari 对外提供了十分漂亮的 Web 管理和监控界面,以及一套改进的 REST API 接口(不 同于 Ceph 自身的 REST API),在一定程度上简化了 Ceph 的管理。最初 Calamari 是作为 Inktank 公司的 Ceph 企业级商业产品来销售,红帽 2015 年收购 Inktank 后为了更好地推动 Ceph 的 发展,对外宣布 Calamari 开源。官网地址:https://github.com/ceph/calamari 优点: 管理功能好 界面友好 可以利用它来部署 Ceph 和监控 Ceph 缺点: 非官方 依赖 OpenStack 某些包 VSMVirtual Storage Manager (VSM)是 Intel 公司研发并且开源的一款 Ceph 集群管理和监控软件, 简化了一些 Ceph 集群部署的一些步骤,可以简单的通过 WEB 页面来操作。官网地址:https://github.com/intel/virtual-storage-manager 优点: 易部署 轻量级 灵活(可以自定义开发功能)缺点: 监控选项少 缺乏 Ceph 管理功能 InkscopeInkscope 是一个 Ceph 的管理和监控系统,依赖于 Ceph 提供的 API,使用 MongoDB 来 存储实时的监控数据和历史信息。官网地址:https://github.com/inkscope/inkscope 优点: 易部署 轻量级 灵活(可以自定义开发功能)缺点: 监控选项少 缺乏 Ceph 管理功能 Ceph-DashCeph-Dash 是用 Python 开发的一个 Ceph 的监控面板,用来监控 Ceph 的运行状态。同时 提供 REST API 来访问状态数据。官网地址:http://cephdash.crapworks.de/ 优点: 易部署 轻量级 灵活(可以自定义开发功能)缺点: 功能相对简单 4.1. 启动 dashboard 插件Ceph mgr 是一个多插件(模块化)的组件,其组件可以单独的启用或关闭,星新版本需要安装 dashboard 安保,而且必须安装在 mgr 节点,否则报错如下: ubuntu@ceph-mgr1:~$ sudo apt-cache madison ceph-mgr-dashboard ceph-mgr-dashboard | 15.2.14-1bionic | https://mirrors.tuna.tsinghua.edu.cn/ceph/debian-octopus bionic/main amd64 Packages ubuntu@ceph-mgr1:~$ sudo apt install -y ceph-mgr-dashboard Reading package lists... Done Building dependency tree Reading state information... Done ceph-mgr-dashboard is already the newest version (15.2.14-1bionic). ceph-mgr-dashboard set to manually installed. 0 upgraded, 0 newly installed, 0 to remove and 7 not upgraded. # 启用模块 ubuntu@ceph-deploy:~/ceph-cluster$ sudo ceph mgr module enable dashboard 4.2. 启用 dashboard 模块Ceph dashboard 在 mgr 节点进行开启设置,并且可以配置开启或者关闭 SSL # 关闭 SSL ubuntu@ceph-deploy:~/ceph-cluster$ sudo ceph config set mgr mgr/dashboard/ssl false # 指定 dashboard 监听地址和端口 ubuntu@ceph-deploy:~/ceph-cluster$ sudo ceph config set mgr mgr/dashboard/ceph-mgr1/server_addr 172.31.0.14 ubuntu@ceph-deploy:~/ceph-cluster$ sudo ceph config set mgr mgr/dashboard/ceph-mgr1/server_port 9009 ubuntu@ceph-mgr1:~$ sudo systemctl restart [email protected] ubuntu@ceph-mgr1:~$ sudo systemctl status [email protected] ● [email protected] - Ceph cluster manager daemon Loaded: loaded (/lib/systemd/system/[email protected]; indirect; vendor preset: enabled) Active: active (running) since Tue 2021-08-24 15:01:07 UTC; 9s ago Main PID: 4044 (ceph-mgr) Tasks: 33 (limit: 2287) CGroup: /system.slice/system-ceph\x2dmgr.slice/[email protected] └─4044 /usr/bin/ceph-mgr -f --cluster ceph --id ceph-mgr1 --setuser ceph --setgroup ceph Aug 24 15:01:07 ceph-mgr1 systemd[1]: Started Ceph cluster manager daemon. ubuntu@ceph-mgr1:~$ sudo netstat -nlpt Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.0.1:33807 0.0.0.0:* LISTEN 1444/containerd tcp 0 0 172.31.0.14:6800 0.0.0.0:* LISTEN 3750/ceph-mds tcp 0 0 172.31.0.14:9009 0.0.0.0:* LISTEN 4044/ceph-mgr tcp 0 0 172.31.0.14:6801 0.0.0.0:* LISTEN 3750/ceph-mds tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 1115/systemd-resolv tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1864/sshd tcp6 0 0 :::22 :::* LISTEN 1864/sshd 4.3. 设置 dashboard 账户及密码 ubuntu@ceph-deploy:~/ceph-cluster$ touch pass.txt ubuntu@ceph-deploy:~/ceph-cluster$ echo "123456" > pass.txt ubuntu@ceph-deploy:~/ceph-cluster$ sudo ceph dashboard set-login-credentials admin -i pass.txt ****************************************************************** *** WARNING: this command is deprecated. *** *** Please use the ac-user-* related commands to manage users. *** ****************************************************************** Username and password updated 访问 Dashboard http://172.31.0.14:9009
本节暂时结束 |

【本文地址】