| 使用Calibre | 您所在的位置:网站首页 › calibreweb怎么在线阅读 › 使用Calibre |
使用Calibre
|
目录 经过长时间的积累,想必大家都会收藏一些电子书,而随着电子书数量增多,管理和保存似乎成了一个小难题。今天,我们就通过 Calibre-Web 来搭建一个在线电子书库~ Calibre先来了解一下 Calibre,官网对其介绍: calibre is a powerful and easy to use e-book manager. Users say it’s outstanding and a must-have. It’ll allow you to do nearly everything and it takes things a step beyond normal e-book software. It’s also completely free and open source and great for both casual users and computer experts. 简而言之,就是一个功能强大的电子书管理器。 Calibre 支持 Windows、macOS、Linux,然而它是一个PC软件,只能在电脑上运行,无法在 Android/iOS 等移动设备上运行。虽然它也提供了 server 的功能,可以在手机上通过浏览器访问,但始终并非真正的在线书库。 如果你是第一次听说 Calibre,那可以下载安装体验一下~  Calibre-Web Calibre-WebCalibre-Web 又是什么? Calibre-Web is a web app providing a clean interface for browsing, reading and downloading eBooks using a valid Calibre database. 顾名思义,是 calibre 的 web 版本。 不过,它本身和 calibre 是两个独立的项目,唯一有直接关联的就是数据库文件了(metadata.db)。 此外,由于 calibre-web 不会自动生成 metadata.db,所以它需要依赖 calibre 来生成一个 metadata.db 文件才能正常运行。安装 calibre 后启动,默认就会创建一个书库,在用户目录下就会有一个metadata.db,或者你想偷懒也可以直接下载上面这个文件。 部署网上有许多教程是通过 docker 的形式安装,它更适合在NAS 等设备上直接运行,而如果我们想要修改源码反而极不方便。 所以今天我们将直接在 Ubuntu Server 22.04 上以 pip 包的形式进行安装: // 新建一个python的虚拟环境 $ virtualenv venv $ source venv/bin/activate // 安装calibre-web (venv)$ pip install calibreweb要完全启用 calibre-web 的功能,还有一些额外的依赖 requirements.txt: gevent betterreads flask_simpleldap google_auth_oauthlib pydrive comicapi rarfile html2text google-api-python-client==2.49.0 flask_dance==5.1.0 natsort==8.1.0 jsonschema==4.8.0手动安装一下: (venv)$ pip install -r requirements.txt如果缺少一些头文件,比如: Modules/common.h:15:10: fatal error: lber.h: No such file or directory Modules/LDAPObject.c:16:10: fatal error: sasl/sasl.h: No such file or directory则安装对应的库: $ sudo apt install libldap-dev $ sudo apt install libsasl2-dev最后启动试一下,默认监听在 8083 端口: (venv)$ cps启动后需要指定 calibre 的数据库文件 metadata.db:  日志 日志默认的日志等级是 INFO,日志文件保存在用户目录 ~/.calibre-web/ 下。 个人感觉比较坑的地方在于 calibre-web 在启动时会尝试 import 额外的依赖,然而 ImportError 的时候竟然是打 DEBUG 日志,导致有些功能异常的时候却完全不知道哪里出错了。 所以,强烈建议将日志等级改为 DEBUG(启动 cps 后在 web 界面-管理-基本配置 里修改)。 封面如果服务器上已经安装了 ImageMagic,那么上传 PDF 版本的电子书时,calibre-web 会自动提取封面图片。 在 Ubuntu Server 22.04 上碰到个报错: Pdf extraction forbidden by Imagemagick policy: attempt to perform an operation not allowed by the security policy `PDF' @ error/constitute.c/IsCoderAuthorized/421是由于 GhostScript 导致的,修改 /etc/ImageMagick-6/policy.xml,去掉下面的规则: 元数据上传电子书后,calibre-web 支持自动抓取书籍元数据,比如作者、出版社、出版日期、内容简介等。 在 calibre-web 0.6.19 版本中,官方内置了豆瓣、Google、Amazon等多个数据源: (venv)$ ls -al venv/lib/python3.10/site-packages/calibreweb/cps/metadata_provider drwxrwxr-x 3 ubuntu ubuntu 4096 Oct 9 23:39 . drwxrwxr-x 9 ubuntu ubuntu 4096 Oct 9 23:39 .. -rw-rw-r-- 1 ubuntu ubuntu 6640 Oct 9 23:39 amazon.py -rw-rw-r-- 1 ubuntu ubuntu 3555 Oct 9 23:39 comicvine.py -rw-rw-r-- 1 ubuntu ubuntu 7080 Oct 9 23:39 douban.py -rw-rw-r-- 1 ubuntu ubuntu 4508 Oct 9 23:39 google.py -rw-rw-r-- 1 ubuntu ubuntu 13537 Oct 9 23:39 lubimyczytac.py -rw-rw-r-- 1 ubuntu ubuntu 3149 Oct 9 23:39 scholar.py不过由于国内网络环境原因,使用 google 数据源反而会导致 calibre-web 卡住的问题,所以我们可以将 douban.py 以外的都删除,基本没啥大作用。 豆瓣在 calibre-web 0.6.19 版本中,metadata_provider/douban.py 有个小bug无法正常抓取出版社和丛书信息,简单修复一下:  另外,豆瓣的接口有访问频率限制和 IP 黑名单机制,如果你请求搜索接口 https://www.douban.com/j/search 返回 403 Forbidden,那就恭喜你中奖了。 不过我们仍然可以通过网页来搜索电子书 https://www.douban.com/search,修改 douban.py 的 SEARCH_URL 和正则匹配逻辑: 46c49 < SEARCH_URL = "https://www.douban.com/j/search" --- > SEARCH_URL = "https://www.douban.com/search" 89,96c92,95 < results = r.json() < if results["total"] == 0: < return [] < < book_id_list = [ < self.ID_PATTERN.search(item).group("id") < for item in results["items"][:10] if self.ID_PATTERN.search(item) < ] --- > book_id_list = [] > for sid in self.ID_PATTERN.findall(r.text): > if sid not in book_id_list: > book_id_list.append(sid)最终效果: 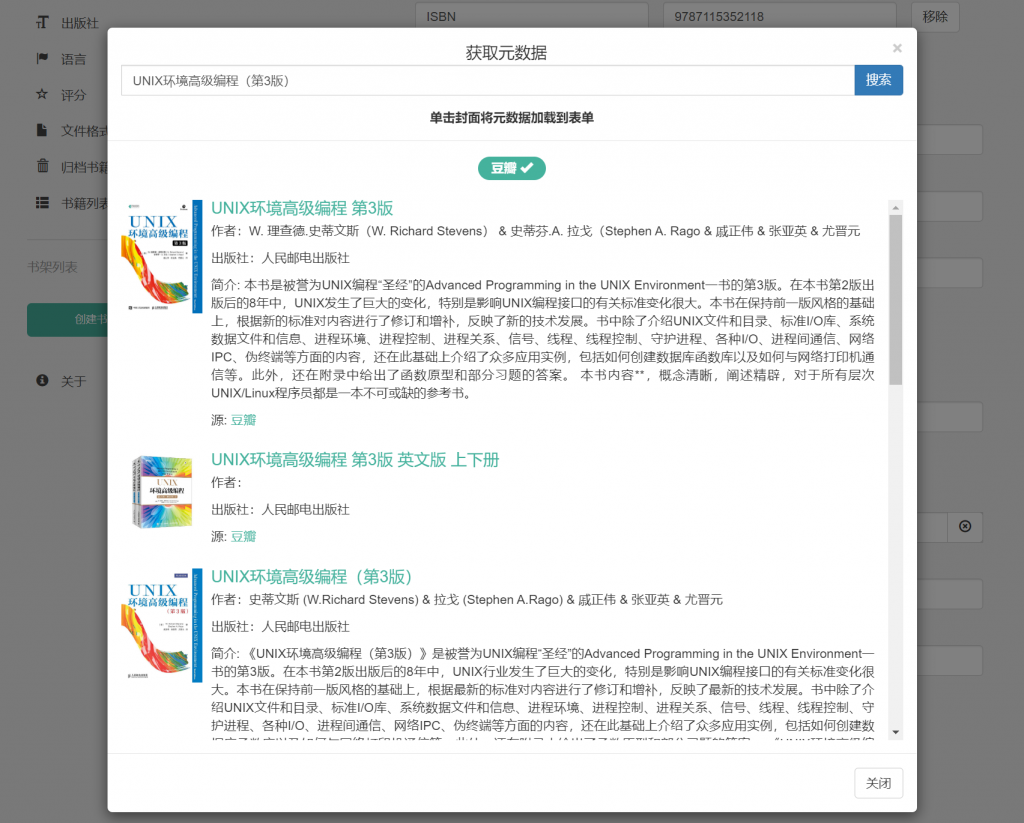 码字很辛苦,转载请注明来自ChenJiehua的《使用Calibre-Web搭建你的电子书库》 码字很辛苦,转载请注明来自ChenJiehua的《使用Calibre-Web搭建你的电子书库》
|
【本文地址】