| 西瓜书习题 | 您所在的位置:网站首页 › bp五要素 › 西瓜书习题 |
西瓜书习题
|
1.神经网络模型
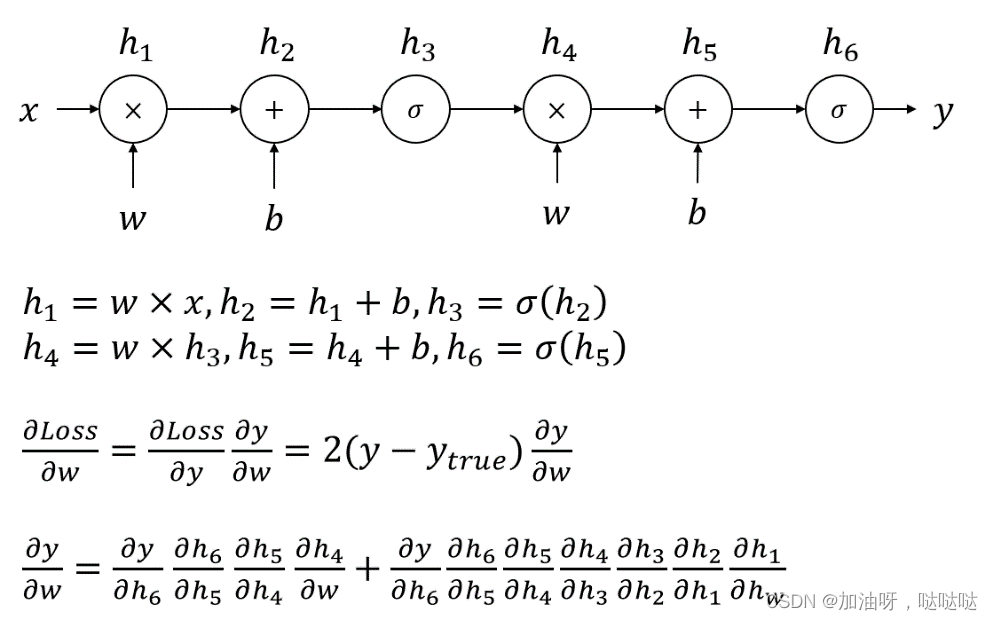
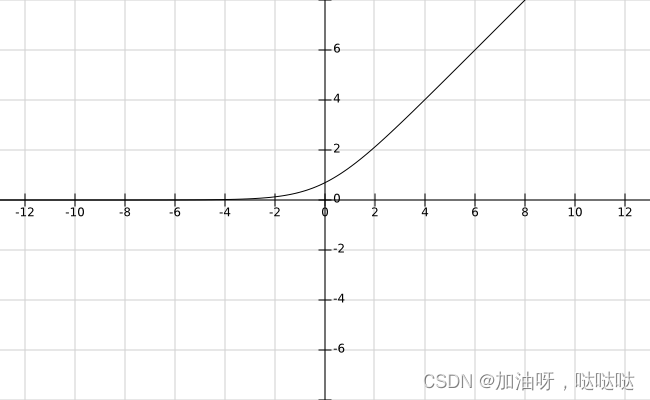
1、神经网络模型的两个最重要的要素是什么? 网络结构、激活函数网络结构、神经元模型激活函数、学习算法学习算法、神经元模型《机器学习》中采用的对神经网络的定义为:“神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应”。神经网络中最基本的成分是神经元模型,也即定义中的“简单单元”,网络结构是神经元“并行互连”的方式,这二者是神经网络模型最重要的要素。 2、以下哪个名称不是activation function的翻译? 响应函数挤压函数激活函数损失函数3、目前神经网络最常用的网络结构是下列哪个选项? 单层后向网络多层后向网络单层前馈网络多层前馈网络 2.万有逼近能力1、下列哪个选项是神经网络万有逼近的正确表述? 仅需一个包含足够多神经元的隐层,多层前馈神经网络就能以任意精度逼近任意复杂度的可测函数仅需一个包含足够多神经元的隐层,多层前馈神经网络就能完美表示任意复杂度的连续函数仅需一个包含足够多神经元的隐层,多层前馈神经网络就能以任意精度逼近任意复杂度的连续函数仅需一个包含100000000个神经元的隐层,多层前馈神经网络就能以任意精度逼近任意复杂度的连续函数2、下列哪个模型不具备万有逼近性? 线性模型泰勒展开傅里叶变换决策树3、多层前馈网络具有的强大表示能力称为神经网络的____性 (4个字)。 万有逼近 3.BP算法推导1、下列关于BP算法的描述哪个是错误的? BP算法适用于平方损失等许多常用损失函数BP算法是迄今最成功、最常用的神经网络算法BP算法的正式完整描述最早出现在1974年Werbos的博士学位论文中BP算法只能用于回归任务2、BP算法的每一轮采用的是什么学习规则? 广义感知机学习规则广义最小二乘学习规则广义决策树学习规则广义支持向量机学习规则3、BP算法的全称为____(7个字)。 误差逆传播算法 4.章节测试1、下列关于BP算法使用小步长优化神经网络的说法中正确的是哪个? 一定能学到最优解可以较好的避免振荡现象训练速度快学得的解比使用大步长具有更小的泛化误差2、下列关于多层前馈神经网络的描述中错误的是哪个? 可以使用BP算法优化至少包含一个隐层神经元之间不存在同层连接输入层可以直接连接到输出层3、多层前馈神经网络可以视为线性函数与激活函数的复合,而单隐层前馈神经网络中这种复合的次数有限,因而单隐层前馈神经网络的万有逼近性对激活函数有一定要求。你认为使用下列哪个激活函数的单隐层前馈神经网络能具有万有逼近性质? 双曲正切函数常值函数线性函数三次函数以多项式函数作为神经元激活函数的单隐层前馈神经网络不具有万有逼近性质。 4、下列哪个选项的步长调整方法是给出的四种方案中最好的? 先使用较大的步长,后使用较小的步长先使用较小的步长,后使用较大的步长一直使用较大的步长一直使用较小的步长5、下列关于万有逼近描述正确的是哪个选项? 万有逼近是神经网络独有的性质神经网络的万有逼近性表明可以很容易的找到一个很好的解具有万有逼近性是将神经网络作为机器学习模型的前提神经网络的万有逼近性可以指导我们设置隐层神经元数Sigmoid函数求导结果为exp(-x)*(1+exp(-x))^-2,代入即可。 6、Sigmoid函数在 x=0.5 处的导数值为____(保留3位小数)。 0.235 7、具有10个隐层结点的单隐层网络在处理输入维度为6维的三分类任务时 (有3个输出层结点),网络中共有____ (填写一个整数) 个参数。 103 输入层到隐层有610=60个权值、隐层到输出层有103=30个权值,另外还有10个隐层神经元阈值、3个输出层神经元阈值,共103个参数 8、实际应用中常使用试错法来设置隐层神经元数,当问题较复杂时,通常使用较____(多/少) 隐层神经元。 多 9、考虑一个有1个输入结点、1个隐层结点、1个输出结点构成的神经网络,该网络输入到隐层的权重与隐层到输出的权重共享,即该神经网络的前馈表达式为 f ( x ) = σ ( w σ ( w x + b ) + b ) f(x) = \sigma(w \sigma(wx+b)+b) f(x)=σ(wσ(wx+b)+b),其中 σ ( x ) \sigma(x) σ(x) 为Sigmoid激活函数。考虑由两个样本组成的数据集 D = { ( 0 , 0.5 ) , ( 1 , 0.25 ) } D=\{(0, 0.5), (1, 0.25)\} D={(0,0.5),(1,0.25)},神经网络初始化参数为 w = − 1 , b = − 1 w=-1, b=-1 w=−1,b=−1,使用平方损失作为损失函数 (总损失为所有样本的平方和损失,不除以2)。则该神经网络在初始化下的损失为____ (保留3位小数)。 0.079
10、上述损失关于 w w w的偏导在初始点处的取值为____(保留3位小数)。 -0.026 dw = 2 * ( (f(0) - 0.5) * f(0) * (1 - f(0)) * sigmod(-1) + \ (f(1)- 0.25) * f(1) * (1 - f(1)) * (sigmod(-2) - sigmod(-2) * (1 - sigmod(-2))) ) -0.02586877674420943311、上述损失关于 b b b 的偏导在初始点处的取值为____ (保留3位有效数字)。 -0.078 db = 2 * ( (f(0) - 0.5) * f(0) * (1 - f(0)) * (1 - sigmod(-1) * (1 - sigmod(-1))) + \ (f(1)- 0.25) * f(1) * (1 - f(1)) * (1 - sigmod(-2) * (1 - sigmod(-2))) ) -0.0784910915824705812、当步长取为0.5时,使用BP算法更新神经网络模型后,模型的损失为____ (保留3位小数)。 0.075 w_old = -1 b_old = -1 yita = 0.5 w_new = w_old - yita * dw b_new = b_old - yita * db err_new = (f(0, w_new, b_new) - 0.5)**2 + (f(1, w_new, b_new) - 0.25)**2 0.0753583450185946213、当步长取为20时,使用BP算法更新神经网络模型后,模型的损失为____ (保留3位小数)。对比上述两种步长值,体会步长选取与振荡现象的关系。 0.112 yita = 20 w_new = w_old - yita * dw b_new = b_old - yita * db err_new = (f(0, w_new, b_new) - 0.5)**2 + (f(1, w_new, b_new) - 0.25)**2 0.1123604033730004914、用学习率 α = 0.3 \alpha=0.3 α=0.3 进行15次梯度下降迭代,每次迭代后计算损失 J ( θ ) J(\theta) J(θ)。如果发现损失值 J ( θ ) J(\theta) J(θ)下降缓慢,并且在15次迭代后仍在下降。基于此,以下哪个结论最可信? α = 0.3 \alpha=0.3 α=0.3是学习率的有效选择当前学习率设置偏小当前学习率设置偏大无法从当前现象对学习率进行判断15、下图是某一激活函数的图像,下列哪个选项可能是该激活函数的表达式?
|
【本文地址】