| Affinity Propagation: AP聚类算法 | 您所在的位置:网站首页 › ap算法聚类 › Affinity Propagation: AP聚类算法 |
Affinity Propagation: AP聚类算法
|
算法概述
原文: [Frey B J, Dueck D. Clustering by passing messages between data points[J]. science, 2007, 315(5814): 972-976.](Frey B J, Dueck D. Clustering by passing messages between data points[J]. science, 2007, 315(5814) AP聚类一般翻译为近邻传播聚类,07年被提出,其优点有: 1. 不需要制定最终聚类族的个数 2. 已有的数据点作为最终的聚类中心,而不是新生成一个族中心。 3. 模型对数据的初始值不敏感。 4. 对初始相似度矩阵数据的对称性没有要求。 5. 相比与k-centers聚类方法,其结果的平方差误差较小。 基本概念: * Exemplar范例:即聚类族中心点; * s(i,j):数据点i与数据点j的相似度值,一般使用欧氏距离的的负值表示,即s(i,j)值越大表示点i与j的距离越近,AP算法中理解为数据点j作为数据点i的聚类中心的能力; * 相似度矩阵:作为算法的初始化矩阵,n个点就有由n乘n个相似度值组成的矩阵; * Preference参考度或称为偏好参数:是相似度矩阵中横轴纵轴索引相同的点,如s(i,i),若按欧氏距离计算其值应为0,但在AP聚类中其表示数据点i作为聚类中心的程度,因此不能为0。迭代开始前假设所有点成为聚类中心的能力相同,因此参考度一般设为相似度矩阵中所有值得最小值或者中位数,但是参考度越大则说明个数据点成为聚类中心的能力越强,则最终聚类中心的个数则越多; * Responsibility,r(i,k):吸引度信息,表示数据点k适合作为数据点i的聚类中心的程度;公式如下: 其中a(i,k’)表示除k外其他点对i点的归属度值,初始为0;s(i,k’)表示除k外其他点对i的吸引度,即i外其他点都在争夺i点的 所有权;r(i,k)表示数据点k成为数据点i的聚类中心的累积证明,r(i,k)值大于0,则表示数据点k成为聚类中心的能力强。说明:此时只考虑哪个点k成为点i的聚类中心的可能性最大,但是没考虑这个吸引度最大的k是否也经常成为其他点的聚类中心(即归属度),若点k只是点i的聚类中心,不是其他任何点的聚类中心,则会造成最终聚类中心个数大于实际的中心个数。 * Availability,a(i,k):归属度信息,表示数据点i选择数据点k作为其聚类中心的合适程度,公式如下: |
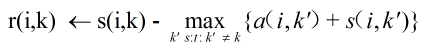
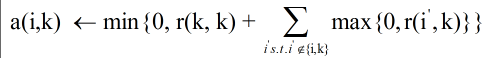
【本文地址】