| Scikit | 您所在的位置:网站首页 › anaconda下载sklearn › Scikit |
Scikit
|
本系列文章介绍人工智能的基础概念和常用公式。由于协及内容所需的数学知识要求,建议初二以上同学学习。 运行本系统程序,请在电脑安装好Python、matplotlib和scikit-learn库。相关安装方法可自行在百度查找。 线性回归算法是使用线性方程对数据集进行拟合的算法,是一个非常常见的回归算法。属于有监督学习。 目录 预测函数 成本函数 梯度下降算法 示例说明 示例程序 预测函数
这是一个直线方程,h(θ)是我们的预测函数,x是输入特征。这里只有一个特征值;θ0和θ1是模型参数。预测过程就是利用现有的样本参数X和h(θ)数集,计算出θ0和θ1的最合适值。 成本函数如何精确测量模型对训练样本拟合的好坏程序呢?我们用到一个叫成本函数也叫损失函数的公式来计算。
预测值和实际值的差的平方的平均值的一半就是线性回归算法的成本函数。之所以取一半是为了计算方便。 梯度下降算法有了预测函数,也有了可以测量拟合情况的成本函数。我们要如何求解θ0和θ1的值呢?这时就用上梯度下降算法了。 梯度下降算法的原理是:先随机选择一组θ0和θ1,同时选择一个参数a作为移动的步幅 。然后让θ0和θ1向特定方向移动这个步幅距离。经过多次迭代,让计算值趋向局部最小值。这时θ0和θ1就是最佳答案。
预测值和实际值的差的平方的平均值的一半就是线性回归算法的成本函数。之所以取一半是为了计算方便。 示例说明在[-2π,2π]区间内生成200个随机点,并添加了随机噪声。然后分别用2阶、4阶、6阶和8阶函数去拟合这个图型。
预测值和实际值的差的平方的平均值的一半就是线性回归算法的成本函数。之所以取一半是为了计算方便。 算出不同阶数函数的拟合评分和均方根误差
预测值和实际值的差的平方的平均值的一半就是线性回归算法的成本函数。之所以取一半是为了计算方便。 示例程序 from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures from sklearn.pipeline import Pipeline from sklearn.metrics import mean_squared_error from matplotlib.figure import SubplotParams import numpy as np import matplotlib.pyplot as plt def polynomial_model(degree=1): polynomial_features = PolynomialFeatures(degree=degree,include_bias=False) linear_regression = LinearRegression(normalize=True) pipeline = Pipeline([("polynomial_fetures",polynomial_features),("linear_regression",linear_regression)]) return pipeline if __name__ == '__main__': n_dots = 200 X = np.linspace(-2*np.pi,2*np.pi,n_dots) Y = np.sin(X) + 0.2* np.random.rand(n_dots)-0.1 X = X.reshape(-1,1) Y = Y.reshape(-1,1) degrees = [2,4,6,8] results = [] for d in degrees: model = polynomial_model(degree=d) model.fit(X,Y) train_score = model.score(X,Y) mse = mean_squared_error(Y,model.predict(X)) results.append({"model":model,"degree":d,"score":train_score,"mse":mse}) for r in results: print("degree:{};train score:{};mean squared error:{}".format(r["degree"],r["score"],r["mse"])) plt.figure(figsize=(12,6),dpi=200,subplotpars=SubplotParams(hspace=0.5)) for i,r,in enumerate(results): fig = plt.subplot(2,2,i+1) plt.xlim(-8,8) plt.title("LinearRegression degree={}".format(r["degree"])) plt.scatter(X,Y,s=5,c='b',alpha=0.5) plt.plot(X,r["model"].predict(X),"r-") plt.show() |
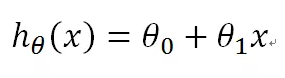
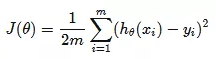



【本文地址】
公司简介
联系我们