| ICCV 2019 | 您所在的位置:网站首页 › ai换装app › ICCV 2019 |
ICCV 2019
|
作者丨文永明 学校丨中山大学硕士生 研究方向丨Object Manipulation、机器人视觉、GAN 引言笔者最近发现一篇发表在 ICCV 2019 挺有意思的论文,是来自中山大学 Fashion 组、邢波 Petuum 公司、湾区字节跳动的工作。中山大学 Fashion 团队是由梁小丹老师和董浩业同学组织。近闻,梁小丹老师获得 2019 年吴文俊人工智能优秀青年奖、2019 年达摩院青橙奖最年轻获得者(奖金 100 万,仅 28 岁)。
他们分析了现存的“AI 换衣”方法都是只能将新衣服应用到固定的人体姿势上,不同姿势有较大的差异,而且无法保持一致性,常常丢失纹理特,因此效果都也不太好。 因此,他们首次提出一种针对不同人体姿势的换衣系统,也就是将人物图像,目标衣服图像,目标姿势作为输入,经过他们提出的多姿势引导的视觉试穿网络(MG-VTON)生成试穿效果,而且生成效果比目前的 state-of-the-art 方法的表现都要好。 笔者觉得还蛮有意思挺好玩的,强烈推荐你们试一试这篇论文的“AI 试穿“效果,他们的 demo 链接:http://m.fashion-ai.cn/,也可以扫描二维码:
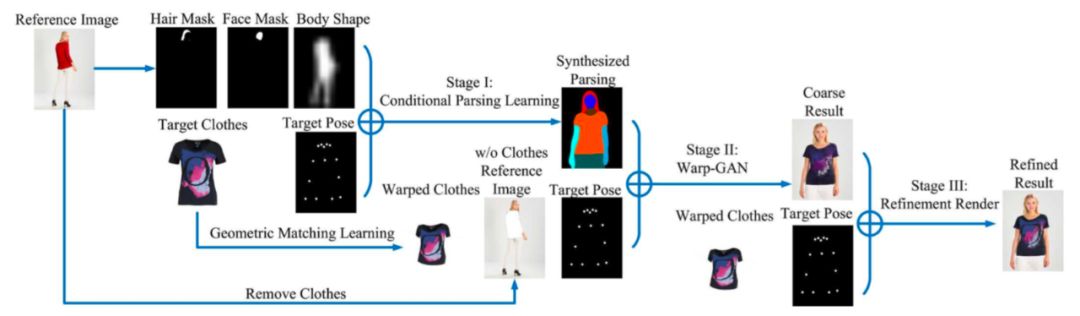
MG-VTON 通过操作衣服和姿势来学习合成视觉上的试穿效果,受 coarse-to-fine 的思想的启发,论文采用了一种轮廓由粗到细的策略,把主任务分为了三个子任务:条件解析学习,Wrap-GAN,细化渲染,如下图 Fig 1 所示 MG-VTON 的整体框架:
▲ Fig 1. MG-VTON的训练流程示意图 MG-VTON 就此可以分为三个阶段: 阶段一:首先,将参考人物图像分解成三个二进制掩码,分别是头发掩码 阶段二:通过扭曲生成对抗网络 Warp-GAN 将扭曲后的衣服图像、去除了衣服的参考人物图像、目标姿势、人物解析图训练生成粗粒度的试穿结果。 阶段三:以扭曲后的衣服、目标姿势、粗粒度合成结果为条件输入,通过细化渲染网络得到细化后的图像结果。 具体流程和损失函数条件解析网络 条件解析网络是基于条件生成对抗网络(CGAN)的设计的,条件解析网络与 CGAN 类似,其中输入条件为衣服图像 C、目标姿势 P、掩码 M,其中掩码 M 有三部分组成:头发掩码
▲ Fig 2. 条件解析网络流程示意图 条件解析网络损失函数也与 CGAN 类似,并且加入 L1 损失进一步平滑生成的结果,
Warp-GAN
▲ Fig 3. Warp-GAN流程示意图 Warp-GAN 除了常见的对抗损失
通过预训练好的 ϕ 将第 i 层特征映射到共享的高维特征空间去, 将这样提取出的特征,作为目标函数的一部分,通过比较待生成的图片的特征值与目标图片的特征值,使得待生成的图片与目标图片在语义上更加相似(相对于像素级别的损失函数)。同时,参考了 pixp2pixHD [1] 引入了特征损失:
Warp-GAN 总的损失函数为:
细化渲染网络与几何匹配模块
▲ Fig 4. 细化渲染网络流程示意图 将 Warp-GAN 得到的粗糙的试穿效果
通过局部的增强的细化渲染能得到更好的柔性物体的纹理特征,细化渲染网络总的损失函数为:
而几何匹配模块就是学习如何把衣服扭曲的一个模块,学习映射的有着参数的 θ 的函数 T,几何匹配模块损失函数最小化:
其中 数据集 由于现成的针对 AI 试穿的数据集都是固定一个姿势的,例如 VITON [2] 和 CP-VTON [3]。因此,本文作者构建了一个名为 MPV 的数据集,从互联网上挑选了 35,687 张人物图像和 13,524 张衣服图像,每张人物图像都有着不同的姿势,分辨率为 256×192,提取 62,780 个穿着同一件衣服的同一个人的不同姿势的三元组。还是使用了数据集 DeepFashion [4],里面是有着摆着不同姿势的同一个人,但是没有衣服图像。 评价标准 1. 使用了亚马逊劳务众包平台 AMT 来判断试穿的视觉效果的好坏。 2. 使用结构相似性 SSIM 评价指标来评价合成图片和真实图片的相似性,是一种全参考的图像质量评价指标。 3. 使用 IS 指标来衡量生成图片的生成质量和多样性。 结果分析
▲ Fig 3. MG-VTON与VITON、CP-VTON的对比
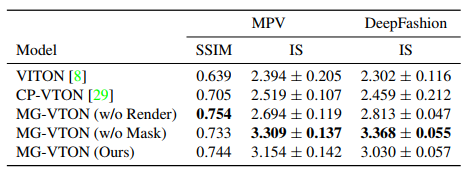
▲ Tab 1. 定量结果 在 MPV 和 DeepFashion 数据集中,SSIM 指标中 MG-VTON (w/o Render) 最高分,IS 指标中 MG-VTON (w/o Mask) 最好,从 Fig 3 来看,虽然 MG-VTON 比 MG-VTON (w/o Render) 以及 MG-VTON (w/o Mask) 的定量指标稍差一点,但是 MG-VTON 视觉效果最好。
▲ Fig 4. MPV上训练,DeepFashion上测试 在 MPV 上训练,在 DeepFashion 上测试,第一行是想要试穿的衣服和姿势估计,第一列是对应的人物图像,生成试穿效果都挺好的,能生成出不同动作姿势的试穿效果,不得不说细节纹理也处理的很好,因此应用价值高,可以应用得更广泛。
▲ Fig 5. 消融实验 消融实验里表明细化渲染网络中的掩码损失,感知损失,姿势状态,在 Warp-GAN 模块都起着至关重要的作用。
▲ Fig 6. 不同的人体解析质量得到的不同试穿效果
▲ Fig 7. 不同的人体解析质量得到的不同试穿效果 可以看出人体解析得越好,生成的试穿效果越好,证明了人体解析学习在 MG-VTON 中的作用。 总结思考这篇论文的创新点在于首次研究了多姿势的视觉试穿系统,一改以往只能固定动作姿势的试穿模式,做了大量定量和定性实验证明了 MG-VTON 的系统方法由于目前的其他的先进的视觉试穿方法,论文结构清晰明了,易于理解,并且参考了大量可借鉴的先进性改进,内容充实。 针对不同姿势的视觉试穿系统,所以实际上他们的实际应用价值更高,笔者试了下这篇论文他们提供的 demo,还蛮好玩的,生成的试穿效果也很好,大家也可以试一下笔者开头提供的 demo 链接地址和二维码玩一下。中大的 Fashion 组同时也做了 AI 会议 DDL 小程序也可以试一下,对 AI 会议的 DDL 作了系统的整理工作,笔者觉得他们的工具还挺方便有用的,二维码:
|







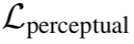 用于衡量高维特征的距离,使得生成图片质量更高,看起来更逼真,
用于衡量高维特征的距离,使得生成图片质量更高,看起来更逼真,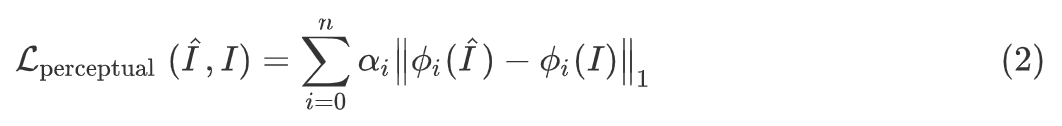
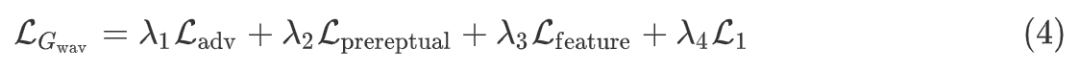

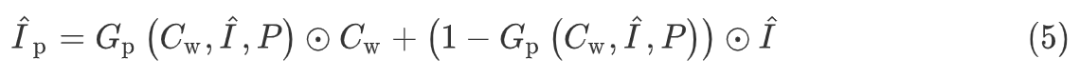
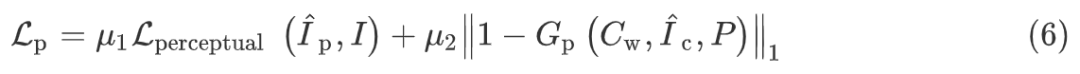
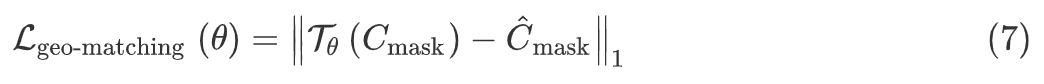






【本文地址】